 第11章 特性与泛型
第11章 特性与泛型
# 第11章 特性与泛型
计算机科学家往往能够处理非统一的结构——情况1、情况2、情况3等,而数学家则倾向于寻找一个统一的公理来支配整个系统。 ——唐纳德·克努特(Donald Knuth)
编程领域的一个重大发现是,编写能够处理多种不同类型值的代码是可行的,甚至这些类型在编写代码时还未被发明出来。以下是两个例子:
Vec<T>是泛型的:你可以创建任何类型值的向量,包括在你的程序中定义的、Vec的作者从未预料到的类型。- 许多类型都有
.write()方法,包括File和TcpStream。你的代码可以通过引用获取任何实现了写入功能的类型,并向其发送数据,而无需关心它具体是哪种类型。以后,如果有人添加了一种新的可写入类型,你的代码也能支持。
当然,这种能力对于Rust来说并非首创。它被称为多态性(polymorphism),是20世纪70年代热门的编程语言新技术,如今已广泛应用。Rust通过两个相关特性来支持多态性:特性(traits)和泛型(generics)。许多程序员对这些概念并不陌生,但Rust从Haskell的类型类(typeclasses)中汲取灵感,采用了全新的实现方式。
特性是Rust对接口(interfaces)或抽象基类(abstract base classes)的实现。乍一看,它们与Java或C#中的接口很相似。用于字节写入的特性名为std::io::Write,其在标准库中的定义如下:
trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()> { ... }
...
}
2
3
4
5
6
这个特性提供了多个方法,我们这里只展示了前三个。
标准类型File和TcpStream都实现了std::io::Write,Vec<u8>也是如此。这三种类型都提供了名为.write()、.flush()等的方法。不关心写入类型的代码可以这样编写:
use std::io::Write;
fn say_hello(out: &mut dyn Write) -> std::io::Result<()> {
out.write_all(b"hello world\n")?;
out.flush()
}
2
3
4
5
6
out的类型是&mut dyn Write,意思是 “对任何实现了Write特性的值的可变引用”。我们可以将任何这样的值的可变引用传递给say_hello:
use std::fs::File;
let mut local_file = File::create("hello.txt")?;
say_hello(&mut local_file)?; // 可行
let mut bytes = vec![];
say_hello(&mut bytes)?; // 同样可行
assert_eq!(bytes, b"hello world\n");
2
3
4
5
6
7
本章将首先介绍特性的使用方法、工作原理以及如何定义自己的特性。但特性的功能远不止我们目前提到的这些。我们将用它们为现有类型,甚至是像str和bool这样的内置类型添加扩展方法。我们将解释为什么为类型添加特性不会增加额外的内存开销,以及如何在不产生虚方法调用开销的情况下使用特性。我们还会了解到,内置特性是Rust为运算符重载和其他功能提供的语言钩子。此外,我们将介绍Self类型、关联函数和关联类型,这三个从Haskell借鉴的特性,优雅地解决了其他语言需要通过变通方法才能解决的问题。
泛型是Rust中另一种多态性的实现方式。与C++模板类似,泛型函数或类型可以用于多种不同类型的值:
/// 给定两个值,选择较小的那个。
fn min<T: Ord>(value1: T, value2: T) -> T {
if value1 <= value2 {
value1
} else {
value2
}
}
2
3
4
5
6
7
8
函数中的<T: Ord>表示min可以用于任何实现了Ord特性的类型T的参数,即任何有序类型。这样的要求被称为约束(bound),因为它限制了T可能的类型。编译器会为你实际使用的每个类型T生成定制的机器代码。
泛型和特性密切相关:泛型函数使用约束中的特性来明确它们可以应用于哪些类型的参数。因此,我们还将讨论&mut dyn Write和<T: Write>的异同,以及如何在这两种使用特性的方式中做出选择。
# 使用特性
特性是一种任何给定类型可能支持也可能不支持的功能。通常情况下,特性代表一种能力:即某个类型能做的事情。
- 实现了
std::io::Write的类型的值可以输出字节。 - 实现了
std::iter::Iterator的类型的值可以生成一系列值。 - 实现了
std::clone::Clone的类型的值可以在内存中创建自身的克隆。 - 实现了
std::fmt::Debug的类型的值可以使用println!()和{:?}格式化说明符进行打印。
这四个特性都是Rust标准库的一部分,许多标准类型都实现了它们。例如:
std::fs::File实现了Write特性,它将字节写入本地文件;std::net::TcpStream实现了该特性,用于向网络连接写入数据;Vec<u8>同样实现了Write特性,每次对字节向量调用.write()都会在向量末尾追加一些数据。Range<i32>(0..10的类型)实现了Iterator特性,一些与切片、哈希表等相关的迭代器类型也实现了该特性。- 大多数标准库类型都实现了
Clone特性。主要的例外是像TcpStream这样的类型,它们不仅仅代表内存中的数据。 - 同样,大多数标准库类型都支持
Debug特性。
关于特性方法有一个不寻常的规则:特性本身必须在作用域内,否则其所有方法都不可见:
let mut buf: Vec<u8> = vec![];
buf.write_all(b"hello")?; // 错误:没有名为`write_all`的方法
2
在这种情况下,编译器会给出一条友好的错误消息,建议添加use std::io::Write;,这样确实可以解决问题:
use std::io::Write;
let mut buf: Vec<u8> = vec![];
buf.write_all(b"hello")?; // 正常
2
3
4
Rust有这个规则是因为,正如我们将在本章后面看到的,你可以使用特性为任何类型添加新方法,甚至是像u32和str这样的标准库类型。第三方库也可以这样做。显然,这可能会导致命名冲突!但由于Rust要求你导入计划使用的特性,库就可以自由利用这个强大的功能。要发生冲突,你必须导入两个为同一类型添加同名方法的特性,在实践中这种情况很少见。(如果你确实遇到了冲突,可以使用本章后面介绍的完全限定方法语法来明确指定你想要的内容。)
Clone和Iterator方法不需要任何特殊导入就能使用,是因为它们默认始终在作用域内:它们是标准前置模块(standard prelude)的一部分,Rust会自动将这些名称导入到每个模块中。实际上,前置模块主要是精心挑选的一些特性。我们将在第13章介绍其中的许多特性。
C++和C#程序员可能已经注意到,特性方法类似于虚方法(virtual methods)。不过,上面这样的调用速度很快,和其他任何方法调用一样快。简单来说,这里不存在多态性。显然buf是一个向量,不是文件或网络连接。编译器可以直接发出对Vec<u8>::write()的简单调用,甚至可以将该方法内联。(C++和C#通常也会这样做,尽管有时由于存在子类化的可能性而无法内联。)只有通过&mut dyn Write进行的调用才会产生动态调度(也称为虚方法调用)的开销,dyn关键字在类型中表明了这一点。dyn Write被称为特性对象(trait object);在接下来的部分,我们将研究特性对象的技术细节,以及它们与泛型函数的比较。
# 特性对象
在Rust中,使用特性编写多态代码有两种方式:特性对象和泛型。我们先介绍特性对象,下一节再讨论泛型。
Rust不允许定义类型为dyn Write的变量:
use std::io::Write;
let mut buf: Vec<u8> = vec![];
let writer: dyn Write = buf; // 错误:`Write`的大小不固定
2
3
4
变量的大小必须在编译时确定,而实现Write特性的类型大小可能各不相同。
如果你来自C#或Java,这可能会让你感到惊讶,但原因很简单。在Java中,类型为OutputStream(类似于Rust中std::io::Write的Java标准接口)的变量是对任何实现了OutputStream的对象的引用。在Java中,它是一个引用这一点不言而喻。C#和大多数其他语言中的接口也是如此。
在Rust中我们想要的是同样的效果,但在Rust中,引用是显式的:
let mut buf: Vec<u8> = vec![];
let writer: &mut dyn Write = &mut buf; // 正常
2
对特性类型的引用,如writer,被称为特性对象。与其他任何引用一样,特性对象指向某个值,有自己的生命周期,并且可以是可变的或共享的。
特性对象的不同之处在于,Rust通常在编译时不知道被引用值的具体类型。因此,特性对象包含一些关于被引用值类型的额外信息。这完全是Rust在内部使用的:当你调用writer.write(data)时,Rust需要这些类型信息,以便根据*writer的实际类型动态调用正确的write方法。你不能直接查询这些类型信息,并且Rust不支持从特性对象&mut dyn Write向下转型为像Vec<u8>这样的具体类型。
# 特性对象的布局
在内存中,特性对象是一个胖指针(fat pointer),由一个指向值的指针和一个指向表示该值类型的表的指针组成。因此,每个特性对象占用两个机器字长,如图11-1所示。
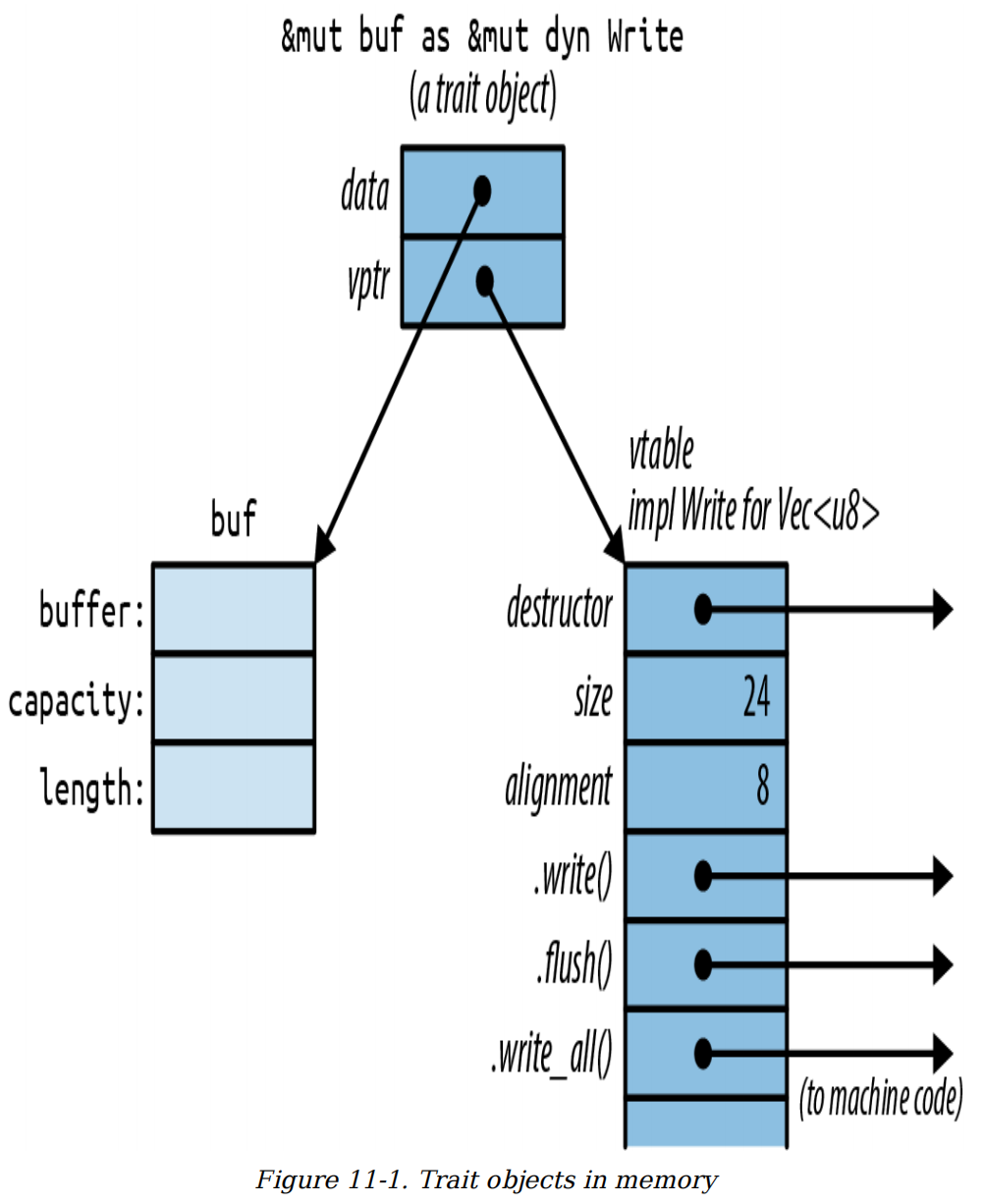 图11-1 内存中的特性对象
图11-1 内存中的特性对象
C++也有这种运行时类型信息,称为虚表(virtual table)或vtable。在Rust中,和C++一样,vtable在编译时生成一次,并由相同类型的所有对象共享。图11-1中颜色较深的部分,包括vtable,都是Rust的私有实现细节。同样,这些不是你可以直接访问的字段和数据结构。相反,当你调用特性对象的方法时,语言会自动使用vtable来确定调用哪个实现。
经验丰富的C++程序员会注意到,Rust和C++在内存使用上略有不同。在C++中,vtable指针(vptr)作为结构体的一部分存储。而Rust使用胖指针。结构体本身只包含其字段。
通过这种方式,一个结构体可以实现几十个特性,而无需包含几十个vptr。即使像i32这样小到无法容纳vptr的类型,也可以实现特性。
Rust在需要时会自动将普通引用转换为特性对象。这就是为什么在这个例子中我们能够将&mut local_file传递给say_hello:
let mut local_file = File::create("hello.txt")?;
say_hello(&mut local_file)?;
2
&mut local_file的类型是&mut File,而say_hello的参数类型是&mut dyn Write。由于File是一种可写入类型,Rust允许这样做,自动将普通引用转换为特性对象。
同样,Rust会很自然地将Box<File>转换为Box<dyn Write>,这是一个在堆中拥有可写入对象的类型:
let w: Box<dyn Write> = Box::new(local_file);
Box<dyn Write>和&mut dyn Write一样,是一个胖指针:它包含写入对象本身的地址和vtable的地址。其他指针类型,如Rc<dyn Write>,也是如此。
这种转换是创建特性对象的唯一方式。编译器实际做的事情非常简单。在进行转换时,Rust知道被引用值的真实类型(在这个例子中是File),所以它只是添加适当的vtable地址,将普通指针转换为胖指针。
# 泛型函数和类型参数
在本章开头,我们展示了一个say_hello()函数,它接受一个特征对象作为参数。现在,让我们将这个函数重写为一个泛型函数:
fn say_hello<W: Write>(out: &mut W) -> std::io::Result<()> {
out.write_all(b"hello world\n")?;
out.flush()
}
2
3
4
只有类型签名发生了变化:
fn say_hello(out: &mut dyn Write) // 普通函数
fn say_hello<W: Write>(out: &mut W) // 泛型函数
2
<W: Write>这部分让函数成为了泛型函数。这是一个类型参数,意味着在这个函数体中,W代表某种实现了Write特征的类型。按照惯例,类型参数通常用单个大写字母表示。
W代表哪种类型取决于泛型函数的使用方式:
say_hello(&mut local_file)?; | // 调用say_hello::<File> |
|---|---|
say_hello(&mut bytes)?; | // 调用say_hello::<Vec<u8>> |
当你将&mut local_file传递给泛型的say_hello()函数时,你实际上调用的是say_hello::<File>()。Rust会为这个函数生成机器码,调用File::write_all()和File::flush()。当你传递&mut bytes时,你调用的是say_hello::<Vec<u8>>()。Rust会为这个版本的函数生成单独的机器码,调用相应的Vec<u8>方法。在这两种情况下,Rust都会根据参数的类型推断出类型W。这个过程被称为单态化,编译器会自动处理这一切。
你也可以明确写出类型参数:say_hello::<File>(&mut local_file)?;。
这种情况很少有必要,因为Rust通常可以通过查看参数来推断类型参数。这里,say_hello泛型函数期望一个&mut W类型的参数,而我们传递给它的是一个&mut File,所以Rust推断出W = File。
如果你调用的泛型函数没有任何参数能提供有用的线索,你可能就得明确写出类型参数:
// 调用一个不带参数的泛型方法collect<C>()
let v1 = (0..1000).collect(); // 错误:无法推断类型
let v2 = (0..1000).collect::<Vec<i32>>(); // 正确
2
3
有时,我们需要类型参数具备多种能力。例如,如果我们想打印出向量中出现频率最高的前十个值,那么这些值必须是可打印的:
use std::fmt::Debug;
fn top_ten<T: Debug>(values: &Vec<T>) { ... }
2
但这还不够。我们要如何确定哪些值是出现频率最高的呢?通常的做法是将这些值作为哈希表中的键。这意味着这些值需要支持Hash和Eq操作。T的约束必须同时包含这些以及Debug。这里的语法使用+符号:
use std::hash::Hash;
use std::fmt::Debug;
fn top_ten<T: Debug + Hash + Eq>(values: &Vec<T>) { ... }
2
3
有些类型实现了Debug,有些实现了Hash,有些支持Eq,还有少数类型,比如u32和String,实现了这三种,如图11 - 2所示。
图11 - 2. 特征作为类型集合
类型参数也可能完全没有约束,但如果你没有为它指定任何约束,你对这个值能做的事情就很有限。你可以移动它,可以将它放入一个Box或向量中。差不多就这些了。
泛型函数可以有多个类型参数:
/// 对一个大型的分区数据集运行查询。
/// 请参阅<http://research.google.com/archive/mapreduce.html>。
fn run_query<M: Mapper + Serialize, R: Reducer + Serialize>(
data: &DataSet, map: M, reduce: R
) -> Results {
...
}
2
3
4
5
6
7
正如这个例子所示,约束可能会变得很长,让人看着很费劲。Rust提供了一种替代语法,使用where关键字:
fn run_query<M, R>(data: &DataSet, map: M, reduce: R) -> Results
where
M: Mapper + Serialize,
R: Reducer + Serialize
{
...
}
2
3
4
5
6
7
类型参数M和R仍然在前面声明,但约束被移到了单独的行上。这种where子句也允许用于泛型结构体、枚举、类型别名和方法——在任何允许约束的地方都可以使用。
当然,除了使用where子句,还有一种选择是保持简单:找到一种方法,在编写程序时不过度使用泛型。
“函数参数接收引用”介绍了生命周期参数的语法。一个泛型函数可以同时有生命周期参数和类型参数。
生命周期参数排在前面:
/// 返回`candidates`中离`target`点最近的点的引用。
fn nearest<'t, 'c, P>(target: &'t P, candidates: &'c [P]) -> &'c P
where
P: MeasureDistance
{
...
}
2
3
4
5
6
7
这个函数接受两个参数,target和candidates。它们都是引用,我们给它们不同的生命周期't和'c(如“不同的生命周期参数”中所讨论的)。此外,这个函数可以处理任何实现了MeasureDistance特征的类型P,所以我们可能在一个程序中对Point2d值使用它,在另一个程序中对Point3d值使用它。
生命周期对机器码没有任何影响。使用相同类型P但不同生命周期的两次对nearest()的调用,会调用相同的已编译函数。只有不同的类型才会导致Rust编译泛型函数的多个副本。
当然,函数并不是Rust中唯一的泛型代码:
- 我们已经在“泛型结构体”和“泛型枚举”中介绍过泛型类型。
- 即使定义方法的类型不是泛型的,单个方法也可以是泛型的:
impl PancakeStack {
fn push<T: Topping>(&mut self, goop: T) -> PancakeResult<()> {
goop.pour(&self);
self.absorb_topping(goop)
}
}
2
3
4
5
6
- 类型别名也可以是泛型的:
type PancakeResult<T> = Result<T, PancakeError>;
- 我们将在本章后面介绍泛型特征。
本节介绍的所有特性——约束、where子句、生命周期参数等等——都可以用于所有泛型项,而不仅仅是函数。
# 该如何选择
使用特征对象还是泛型代码,这个选择比较微妙。由于这两个特性都基于特征,它们有很多共同之处。
每当你需要将不同类型的值收集在一起时,特征对象就是正确的选择。从技术上讲,也可以创建泛型“沙拉”:
trait Vegetable {
...
}
struct Salad<V: Vegetable> {
veggies: Vec<V>
}
2
3
4
5
6
然而,这是一种相当严格的设计。每一份这样的“沙拉”完全由单一类型的蔬菜组成。不是每个人都喜欢这种东西。本书的一位作者曾经花14美元买了一份Salad<IcebergLettuce>,至今都还没缓过来。
我们怎样才能做出更好的“沙拉”呢?由于Vegetable值的大小可能各不相同,我们不能让Rust创建一个Vec<dyn Vegetable>:
struct Salad {
veggies: Vec<dyn Vegetable> // 错误:`dyn Vegetable`没有固定大小
}
2
3
特征对象就是解决方案:
struct Salad {
veggies: Vec<Box<dyn Vegetable>>
}
2
3
每个Box<dyn Vegetable>可以存放任何类型的蔬菜,但Box本身有固定大小——两个指针——适合存储在向量中。除了在食物中出现“盒子”这个不太恰当的比喻之外,这正是我们所需要的,而且它对于绘图应用程序中的形状、游戏中的怪物、网络路由器中可插拔的路由算法等等同样适用。
使用特征对象的另一个可能原因是减少编译后的代码总量。Rust可能需要为泛型函数使用的每种类型都编译一次。这可能会使二进制文件变大,在C++领域,这种现象被称为代码膨胀。如今,内存很充足,我们大多数人都可以忽略代码大小;但确实存在资源受限的环境。
除了涉及“沙拉”或低资源环境的情况外,泛型相对于特征对象有三个重要优势,因此在Rust中,泛型是更常用的选择。
第一个优势是速度。注意泛型函数签名中没有dyn关键字。因为你在编译时指定类型,无论是显式指定还是通过类型推断,编译器都确切知道要调用哪个write方法。不使用dyn关键字是因为没有特征对象——也就没有动态分发——涉及其中。
引言中展示的泛型min()函数和我们分别编写min_u8、min_i64、min_string等函数的速度一样快。编译器可以像对待任何其他函数一样内联它,所以在发布版本的构建中,对min::<i32>的调用可能只需要两三条指令。使用常量参数的调用,比如min(5, 3),会更快:Rust可以在编译时计算它,所以运行时完全没有开销。
再看这个泛型函数调用:
let mut sink = std::io::sink();
say_hello(&mut sink)?;
2
std::io::sink()返回一个Sink类型的写入器,它会悄悄地丢弃写入的所有字节。
当Rust为这段代码生成机器码时,它可以生成调用Sink::write_all、检查错误,然后调用Sink::flush的代码。这是泛型函数体中要求做的事情。
或者,Rust可以查看这些方法,并意识到以下几点:
Sink::write_all()什么都不做。Sink::flush()什么都不做。- 这两个方法都不会返回错误。
简而言之,Rust拥有完全优化掉这个函数调用所需的所有信息。
将其与使用特征对象的行为进行比较。Rust直到运行时才知道特征对象指向什么类型的值。所以即使你传递一个Sink,调用虚方法和检查错误的开销仍然存在。
泛型的第二个优势是,并非每个特征都支持特征对象。特征支持一些功能,比如关联函数,这些功能只适用于泛型,它们完全排除了特征对象的使用。我们在介绍这些功能时会指出。
泛型的第三个优势是,很容易同时用多个特征来约束泛型类型参数,就像我们的top_ten函数要求其T参数实现Debug + Hash + Eq一样。特征对象做不到这一点:Rust不支持像&mut (dyn Debug + Hash + Eq)这样的类型。(你可以使用本章后面定义的子特征来解决这个问题,但这有点复杂。)
# 定义和实现特征
定义一个特征很简单。给它取个名字,并列出特征方法的类型签名。如果我们正在编写一个游戏,可能会有这样一个特征:
/// 用于表示角色、物品和场景的特征——
/// 游戏世界中任何在屏幕上可见的东西。
trait Visible {
/// 在给定的画布上渲染这个对象。
fn draw(&self, canvas: &mut Canvas);
/// 如果点击坐标(x, y)应该选中这个对象,则返回true。
fn hit_test(&self, x: i32, y: i32) -> bool;
}
2
3
4
5
6
7
8
要实现一个特征,使用impl TraitName for Type的语法:
impl Visible for Broom {
fn draw(&self, canvas: &mut Canvas) {
for y in self.y - self.height - 1..self.y {
canvas.write_at(self.x, y, '|');
}
canvas.write_at(self.x, self.y, 'M');
}
fn hit_test(&self, x: i32, y: i32) -> bool {
self.x == x && self.y - self.height - 1 <= y && y <= self.y
}
}
2
3
4
5
6
7
8
9
10
11
注意,这个impl包含了Visible特征中每个方法的实现,没有其他内容。在特征impl中定义的所有内容都必须是该特征的实际功能;如果我们想添加一个辅助方法来支持Broom::draw(),就必须在一个单独的impl块中定义:
impl Broom {
/// 下面`Broom::draw()`使用的辅助函数。
fn broomstick_range(&self) -> Range<i32> {
self.y - self.height - 1..self.y
}
}
2
3
4
5
6
这些辅助函数可以在特征impl块中使用:
impl Visible for Broom {
fn draw(&self, canvas: &mut Canvas) {
for y in self.broomstick_range() {
...
}
...
}
...
}
2
3
4
5
6
7
8
9
# 默认方法
我们之前讨论的Sink写入器类型可以用几行代码实现。首先,定义类型:
/// 一个忽略你写入的任何数据的写入器。
pub struct Sink;
2
Sink是一个空结构体,因为我们不需要在其中存储任何数据。接下来,为Sink提供Write特性的实现:
use std::io::{Write, Result};
impl Write for Sink {
fn write(&mut self, buf: &[u8]) -> Result<usize> {
// 声称成功写入了整个缓冲区。
Ok(buf.len())
}
fn flush(&mut self) -> Result<()> {
Ok(())
}
}
2
3
4
5
6
7
8
9
10
11
12
到目前为止,这与Visible特性非常相似。但是我们也看到Write特性有一个write_all方法:
let mut out = Sink;
out.write_all(b"hello world\n")?;
2
为什么Rust允许我们在没有定义这个方法的情况下为Sink实现Write呢?答案是标准库中Write特性的定义包含了write_all的默认实现:
trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()> {
let mut bytes_written = 0;
while bytes_written < buf.len() {
bytes_written += self.write(&buf[bytes_written..])?;
}
Ok(())
}
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
write和flush方法是每个写入器都必须实现的基本方法。写入器也可以实现write_all,但如果没有实现,就会使用前面展示的默认实现。
你自己定义的特性也可以使用相同的语法包含默认实现。
标准库中对默认方法最显著的应用是Iterator特性,它有一个必需的方法(.next())和几十个默认方法。第15章会解释原因。
# 特性与他人定义的类型
Rust允许你在任何类型上实现任何特性,只要该特性或类型是在当前包中引入的。
这意味着,任何时候你想为某个类型添加方法,都可以使用特性来实现:
trait IsEmoji {
fn is_emoji(&self) -> bool;
}
/// 为内置字符类型实现IsEmoji特性。
impl IsEmoji for char {
fn is_emoji(&self) -> bool {
...
}
}
assert_eq!('$'.is_emoji(), false);
2
3
4
5
6
7
8
9
10
11
12
和其他任何特性方法一样,只有当IsEmoji在作用域内时,这个新的is_emoji方法才可见。
这个特定特性的唯一目的是为现有的char类型添加一个方法。这被称为扩展特性(extension trait)。当然,你也可以通过编写impl IsEmoji for str { ... }等方式,将这个特性添加到其他类型上。
你甚至可以使用泛型impl块,一次性为一整类类型添加扩展特性。这个特性可以在任何类型上实现:
use std::io::{self, Write};
/// 可以向其发送HTML的类型的特性。
trait WriteHtml {
fn write_html(&mut self, html: &HtmlDocument) -> io::Result<()>;
}
2
3
4
5
6
为所有实现Write的类型实现这个特性,就使其成为了一个扩展特性,为所有Rust写入器添加了一个方法:
/// 你可以将HTML写入任何std::io写入器。
impl<W: Write> WriteHtml for W {
fn write_html(&mut self, html: &HtmlDocument) -> io::Result<()> {
...
}
}
2
3
4
5
6
impl<W: Write> WriteHtml for W这行代码的意思是 “对于每一个实现了Write的类型W,这里是WriteHtml特性针对W的实现”。
serde库很好地展示了在标准类型上实现用户自定义特性的实用性。serde是一个序列化库,也就是说,你可以用它将Rust数据结构写入磁盘,之后再重新加载。该库定义了一个Serialize特性,为其支持的每种数据类型都实现了这个特性。所以在serde的源代码中,有针对bool、i8、i16、i32、数组和元组类型等的Serialize实现,涵盖了所有像Vec和HashMap这样的标准数据结构。
这一切的结果是,serde为所有这些类型添加了一个.serialize()方法。可以像这样使用:
use serde::Serialize;
use serde_json;
pub fn save_configuration(config: &HashMap<String, String>) -> std::io::Result<()> {
// 创建一个JSON序列化器,将数据写入文件。
let writer = File::create(config_filename())?;
let mut serializer = serde_json::Serializer::new(writer);
// serde的`.serialize()`方法完成其余工作。
config.serialize(&mut serializer)?;
Ok(())
}
2
3
4
5
6
7
8
9
10
11
我们之前说过,当你实现一个特性时,该特性或类型必须是在当前包中新建的。这被称为孤儿规则(orphan rule)。它有助于Rust确保特性实现的唯一性。你的代码不能为u8实现Write,因为Write和u8都在标准库中定义。如果Rust允许各个包这样做,那么可能会在不同的包中存在多个针对u8的Write实现,而Rust将无法合理地决定在给定的方法调用中使用哪个实现。
(C++也有类似的唯一性限制:单一定义规则(One Definition Rule)。以典型的C++风格,除了最简单的情况,编译器不会强制执行该规则,如果你违反了它,会得到未定义行为。)
# 特性中的Self
特性可以使用Self关键字作为一种类型。例如,标准的Clone特性(稍微简化后)看起来是这样的:
pub trait Clone {
fn clone(&self) -> Self;
...
}
2
3
4
在这里使用Self作为返回类型意味着x.clone()的类型与x的类型相同,无论x是什么类型。如果x是String,那么x.clone()的类型就是String,而不是dyn Clone或其他任何可克隆的类型。
同样,如果我们定义这个特性:
pub trait Spliceable {
fn splice(&self, other: &Self) -> Self;
}
2
3
并为其提供两个实现:
impl Spliceable for CherryTree {
fn splice(&self, other: &Self) -> Self {
...
}
}
impl Spliceable for Mammoth {
fn splice(&self, other: &Self) -> Self {
...
}
}
2
3
4
5
6
7
8
9
10
11
那么在第一个impl块中,Self只是CherryTree的别名,在第二个impl块中,它是Mammoth的别名。
这意味着我们可以拼接两棵樱桃树或两只猛犸象,而不是创建一个猛犸象 - 樱桃树的杂交体。self的类型和other的类型必须匹配。
使用Self类型的特性与特性对象不兼容:
// 错误:特性`Spliceable`不能用于创建特性对象
fn splice_anything(left: &dyn Spliceable, right: &dyn Spliceable) {
let combo = left.splice(right);
// ...
}
2
3
4
5
在深入研究特性的高级功能时,我们会多次遇到这个原因。Rust拒绝这段代码是因为它无法对left.splice(right)调用进行类型检查。特性对象的关键在于,其类型直到运行时才知道。Rust在编译时无法知道left和right是否会是所需的相同类型。
特性对象实际上适用于最简单的特性,即那些在Java中可以用接口或在C++中可以用抽象基类实现的特性。特性的更高级功能很有用,但它们不能与特性对象共存,因为使用特性对象时,Rust进行程序类型检查所需的类型信息会丢失。
现在,如果我们想要实现基因上不太可能的拼接,可以设计一个对特性对象友好的特性:
pub trait MegaSpliceable {
fn splice(&self, other: &dyn MegaSpliceable) -> Box<dyn MegaSpliceable>;
}
2
3
这个特性与特性对象兼容。对这个.splice()方法的调用进行类型检查没有问题,因为只要other和self的类型都是MegaSpliceable,就不要求other的类型与self的类型匹配。
# 子特性
我们可以声明一个特性是另一个特性的扩展:
/// 游戏世界中的某个角色,可能是玩家,也可能是其他小精灵、石像鬼、松鼠、食人魔等等。
trait Creature: Visible {
fn position(&self) -> (i32, i32);
fn facing(&self) -> Direction;
...
}
2
3
4
5
6
"trait Creature: Visible"这句话的意思是所有生物都是可见的。每个实现Creature特性的类型也必须实现Visible特性:
impl Visible for Broom {
...
}
impl Creature for Broom {
...
}
2
3
4
5
6
7
我们可以按任意顺序实现这两个特性,但是为一个类型实现Creature特性而不实现Visible特性是错误的。在这里,我们说Creature是Visible的子特性,而Creature是Visible的超特性。
子特性类似于Java或C#中的子接口,用户可以假设任何实现子特性的值也实现了它的超特性。但在Rust中,子特性不会继承其超特性的关联项;如果你想调用某个特性的方法,每个特性都必须在作用域内。
实际上,Rust中的子特性只是对Self的约束的一种简写形式。像这样定义Creature与前面展示的定义完全等效:
trait Creature where Self: Visible {
...
}
2
3
# 类型关联函数
在大多数面向对象语言中,接口不能包含静态方法或构造函数,但特性可以包含类型关联函数,这类似于Rust中的静态方法:
trait StringSet {
/// 返回一个新的空集合。
fn new() -> Self;
/// 返回一个包含`strings`中所有字符串的集合。
fn from_slice(strings: &[&str]) -> Self;
/// 检查这个集合是否包含特定的`value`。
fn contains(&self, string: &str) -> bool;
/// 向这个集合中添加一个字符串。
fn add(&mut self, string: &str);
}
2
3
4
5
6
7
8
9
10
每个实现StringSet特性的类型都必须实现这四个关联函数。前两个,new()和from_slice(),不接受self参数,它们用作构造函数。在非泛型代码中,可以使用::语法调用这些函数,就像调用其他任何类型关联函数一样:
// 创建两个假设实现了StringSet特性的类型的集合:
let set1 = SortedStringSet::new();
let set2 = HashedStringSet::new();
2
3
在泛型代码中也是如此,只是类型通常是一个类型变量,如下所示的对S::new()的调用:
/// 返回`document`中不在`wordlist`中的单词集合。
fn unknown_words<S: StringSet>(document: &[String], wordlist: &S) -> S {
let mut unknowns = S::new();
for word in document {
if!wordlist.contains(word) {
unknowns.add(word);
}
}
unknowns
}
2
3
4
5
6
7
8
9
10
与Java和C#接口一样,特性对象不支持类型关联函数。如果你想使用&dyn StringSet特性对象,必须更改特性,为每个不通过引用接受self参数的关联函数添加where Self: Sized约束:
trait StringSet {
fn new() -> Self
where Self: Sized;
fn from_slice(strings: &[&str]) -> Self
where Self: Sized;
fn contains(&self, string: &str) -> bool;
fn add(&mut self, string: &str);
}
2
3
4
5
6
7
8
这个约束告诉Rust,特征对象无需支持这个特定的关联函数。有了这些添加内容后,StringSet特征对象是被允许的;它们仍然不支持new或from_slice,但你可以创建它们,并使用它们来调用.contains()和.add()。同样的技巧适用于任何其他与特征对象不兼容的方法。(我们不会在这里进行关于其工作原理的繁琐技术解释,Sized特征将在第13章介绍。)
# 完全限定方法调用
目前为止,我们见过的调用特征方法的所有方式,都依赖Rust帮你补充一些缺失的部分。例如,假设你写下如下代码:
"hello".to_string()
这里的to_string指的是ToString特征的to_string方法,我们调用的是str类型对该方法的实现。所以这里涉及四个要素:特征、特征的方法、方法的实现,以及应用该实现的值。每次调用方法时,不必把这些都详细写出来,这确实很方便。但在某些情况下,你需要一种能精准表达自己意图的方式。完全限定方法调用就很合适。
首先,要知道方法其实就是一种特殊的函数。下面这两种调用方式是等价的:
"hello".to_string()
str::to_string("hello")
2
第二种形式看起来完全就是调用关联函数。即便to_string方法需要self参数,这种调用方式也没问题。只需把self作为函数的第一个参数传进去就行。
由于to_string是标准ToString特征的方法,你还可以使用另外两种形式:
ToString::to_string("hello")
<str as ToString>::to_string("hello")
2
这四种方法调用的效果完全一样。
大多数时候,你直接写value.method()就行。其他形式属于限定方法调用,它们指定了方法所关联的类型或特征。最后一种带尖括号的形式,两种都指定了,这就是完全限定方法调用。
当你用.运算符写"hello".to_string()时,并没有明确指出调用的是哪个to_string方法。Rust有一套方法查找算法,会根据类型、解引用强制转换等因素来确定具体调用的方法。使用完全限定调用,你就能精准指定要调用的方法,在一些特殊情况下,这很有帮助:
- 当两个方法同名时。经典的例子是
Outlaw结构体,它从两个不同的特征里继承了两个.draw()方法,一个用于在屏幕上绘制,另一个用于与法律相关的交互:
outlaw.draw(); // 报错:是在屏幕上绘制,还是拔出手枪?
Visible::draw(&outlaw); // 没问题:在屏幕上绘制
HasPistol::draw(&outlaw); // 没问题:执法相关操作
2
3
通常来说,最好把其中一个方法重命名,但有些时候没办法这么做。
- 当
self参数的类型无法推断时:
let zero = 0; // 未指定类型,可能是`i8`、`u8`等等
zero.abs(); // 报错:无法在类型不明确的数值上调用`abs`方法
i64::abs(zero); // 没问题
2
3
- 当把函数本身当作函数值使用时:
let words: Vec<String> =
line.split_whitespace() // 迭代器生成`&str`值
.map(ToString::to_string) // 没问题
.collect();
2
3
4
- 当在宏里调用特征方法时。我们会在第21章解释。
完全限定语法也适用于关联函数。上一节里,我们在泛型函数里用S::new()创建新集合。我们也可以写成StringSet::new(),或者<S as StringSet>::new()。
# 定义类型间关系的特征
到目前为止,我们看到的每个特征都是独立的:一个特征就是一组类型可以实现的方法。特征还能用于多个类型需要协同工作的场景,它们可以描述类型之间的关系。
std::iter::Iterator特征将每种迭代器类型和它生成的值的类型关联起来。std::ops::Mul特征关联了可以进行乘法运算的类型。在表达式a * b里,a和b的值可以是相同类型,也可以是不同类型。rand库包含一个用于随机数生成器的特征(rand::Rng),还有一个用于可随机生成类型的特征(rand::Distribution)。这些特征明确规定了这些类型如何协同工作。
你不用每天都创建这类特征,但在标准库和第三方库中,你会经常遇到它们。在本节中,我们会展示这些示例是如何实现的,在需要的时候介绍相关的Rust语言特性。这里的关键技能是读懂特征和方法签名,理解它们对相关类型的描述。
# 关联类型(或迭代器的工作原理)
我们从迭代器开始讲起。如今,每种面向对象语言都对迭代器提供了某种内置支持,迭代器是用来遍历某些值序列的对象。
Rust有一个标准的Iterator特征,定义如下:
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
...
}
2
3
4
5
这个特征的第一个特性type Item;是一个关联类型。每个实现Iterator的类型都必须指定它生成的项是什么类型。
第二个特性next()方法,在返回值里用到了这个关联类型。next()返回一个Option<Self::Item>:要么是Some(item),即序列里的下一个值;要么是None,表示没有更多值可访问了。类型写成Self::Item,而不是简单的Item,因为Item是每种迭代器类型的特性,不是一个独立的类型。和往常一样,只要使用self和Self类型的字段、方法等,它们就会在代码里显式出现。
下面是为一个类型实现Iterator特征的示例:
// (代码来自`std::env`标准库模块)
impl Iterator for Args {
type Item = String;
fn next(&mut self) -> Option<String> {
...
}
...
}
2
3
4
5
6
7
8
std::env::Args是标准库函数std::env::args()返回的迭代器类型,我们在第2章用这个函数来访问命令行参数。它生成String值,所以在实现部分声明type Item = String;。
泛型代码可以使用关联类型:
/// 遍历一个迭代器,把值存到一个新的向量里。
fn collect_into_vector<I: Iterator>(iter: I) -> Vec<I::Item> {
let mut results = Vec::new();
for value in iter {
results.push(value);
}
results
}
2
3
4
5
6
7
8
在这个函数体里,Rust会帮我们推断value的类型,这很方便;但我们必须明确写出collect_into_vector的返回类型,而关联类型Item是实现这一点的唯一方式。(Vec<I>是完全错误的:这意味着我们返回的是一个迭代器向量!)
前面这个示例代码,你一般不会自己去写,因为读完第15章后,你就会知道迭代器已经有一个标准方法能实现同样的功能:iter.collect()。所以在继续往下讲之前,我们再看一个示例:
/// 打印迭代器生成的所有值
fn dump<I>(iter: I)
where
I: Iterator
{
for (index, value) in iter.enumerate() {
println!("{}: {:?}", index, value); // 报错
}
}
2
3
4
5
6
7
8
9
这段代码基本没问题,但有一个问题:value可能不是可打印的类型。
error: `<I as Iterator>::Item` doesn't implement `Debug`
|
8 | println!("{}: {:?}", index, value); // error
| ^^^^^
| `<I as Iterator>::Item` cannot be
formatted
| using `{:?}` because it doesn't
implement `Debug`
|
= help: the trait `Debug` is not implemented for `<I as
Iterator>::Item`
= note: required by `std::fmt::Debug::fmt`
help: consider further restricting the associated type
|
5 | where I: Iterator, <I as Iterator>::Item: Debug
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
报错信息里用了<I as Iterator>::Item这种语法,这是一种明确但很冗长的表示I::Item的方式,让报错信息有点难懂。这是有效的Rust语法,但实际上你很少需要这么写类型。
报错信息的核心意思是,要让这个泛型函数能编译通过,我们必须确保I::Item实现了Debug特征,Debug特征用于用{:?}格式化值。就像报错信息里建议的,我们可以通过对I::Item设置约束来实现:
use std::fmt::Debug;
fn dump<I>(iter: I)
where
I: Iterator,
I::Item: Debug
{
...
}
2
3
4
5
6
7
8
或者,我们可以写成 “I必须是一个生成String值的迭代器”:
fn dump<I>(iter: I)
where
I: Iterator<Item = String>
{
...
}
2
3
4
5
6
Iterator<Item = String>本身也是一个特征。如果你把Iterator看作是所有迭代器类型的集合,那么Iterator<Item = String>就是Iterator的一个子集:即生成String的迭代器类型的集合。这种语法可以用在任何能使用特征名称的地方,包括特征对象类型:
fn dump(iter: &mut dyn Iterator<Item = String>) {
for (index, s) in iter.enumerate() {
println!("{}: {:?}", index, s);
}
}
2
3
4
5
像Iterator这样有关联类型的特征,只有在所有关联类型都明确指定的情况下,才和特征方法兼容,就像这里展示的一样。否则,s的类型可能是任意的,Rust也就没办法对这段代码进行类型检查。
我们展示了很多和迭代器有关的示例。这很难避免,因为迭代器是关联类型最典型的应用场景。但一般来说,只要一个特征需要涵盖的不只是方法,关联类型就很有用:
- 在线程池库中,代表一个工作单元的
Task特征,可以有一个关联的Output类型。 - 代表字符串搜索方式的
Pattern特征,可以有一个关联的Match类型,用来表示将模式和字符串匹配时收集到的所有信息:
trait Pattern {
type Match;
fn search(&self, string: &str) -> Option<Self::Match>;
}
/// 你可以在字符串里搜索特定字符。
impl Pattern for char {
/// “匹配结果” 只是字符被找到的位置。
type Match = usize;
fn search(&self, string: &str) -> Option<usize> {
...
}
}
2
3
4
5
6
7
8
9
10
11
12
如果你熟悉正则表达式,就很容易理解为RegExp实现Pattern特征时,Match类型会复杂得多,可能是一个结构体,包含匹配的起始位置和长度、括号分组的匹配位置等等。
- 用于操作关系型数据库的库,可能有一个
DatabaseConnection特征,其关联类型代表事务、游标、预处理语句等等。
关联类型非常适合每种实现都有一种特定相关类型的情况:每种类型的Task都会产生特定类型的Output;每种类型的Pattern都会查找特定类型的Match。不过,正如我们接下来会看到的,有些类型之间的关系并非如此。
# 泛型特征(或运算符重载的工作原理)
Rust中的乘法运算使用这个特征:
/// std::ops::Mul,支持`*`运算符的类型的特征。
pub trait Mul<RHS> {
/// 应用`*`运算符后的结果类型
type Output;
/// `*`运算符的方法
fn mul(self, rhs: RHS) -> Self::Output;
}
2
3
4
5
6
7
8
Mul是一个泛型特征。类型参数RHS是“right-hand side(右侧)”的缩写。
这里的类型参数和在结构体或函数中的含义相同:Mul是一个泛型特征,它的实例Mul<f64>、Mul<String>、Mul<Size>等都是不同的特征,就像min::<i32>和min::<String>是不同的函数,Vec<i32>和Vec<String>是不同的类型一样。
一个类型,比如WindowSize,可以同时实现Mul<f64>和Mul<i32>,甚至更多。这样你就可以用多种其他类型与WindowSize进行乘法运算。
每个实现都会有自己关联的Output类型。
在处理孤儿规则(orphan rule)时,泛型特征有特殊的豁免情况:只要特征的其中一个类型参数是在当前包(crate)中定义的类型,你就可以为外部类型实现外部特征。所以,如果你自己定义了WindowSize,即使你没有定义Mul和f64,也可以为f64实现Mul<WindowSize>。
这些实现甚至可以是泛型的,比如impl<T> Mul<WindowSize> for Vec<T>。这是可行的,因为其他任何包都不可能为其他类型定义Mul<WindowSize>,因此也就不会出现实现冲突的情况。(我们在“特征与他人的类型”中介绍过孤儿规则。)
nalgebra这样的包就是通过这种方式为向量定义算术运算的。
前面展示的特征少了一个小细节。真正的Mul特征是这样的:
pub trait Mul<RHS = Self> {
...
}
2
3
语法RHS = Self表示RHS的默认值是Self。如果我写impl Mul for Complex,没有指定Mul的类型参数,那就意味着impl Mul<Complex> for Complex。在约束中,如果我写where T: Mul,那就意味着where T: Mul<T>。
在Rust中,表达式lhs * rhs是Mul::mul(lhs, rhs)的简写。所以在Rust中重载*运算符,只需要实现Mul特征即可。我们将在下一章展示示例。
# impl Trait
可以想象,多种泛型类型组合在一起可能会变得很混乱。例如,仅使用标准库中的组合器(combinators)组合几个迭代器,就会让返回类型很快变得很难看:
use std::iter;
use std::vec::IntoIter;
fn cyclical_zip(v: Vec<u8>, u: Vec<u8>) -> iter::Cycle<iter::Chain<IntoIter<u8>, IntoIter<u8>>> {
v.into_iter().chain(u.into_iter()).cycle()
}
2
3
4
5
我们可以很容易地用特征对象来替换这个复杂的返回类型:
fn cyclical_zip(v: Vec<u8>, u: Vec<u8>) -> Box<dyn Iterator<Item = u8>> {
Box::new(v.into_iter().chain(u.into_iter()).cycle())
}
2
3
然而,在大多数情况下,为了避免难看的类型签名,每次调用这个函数都要承担动态分发的开销和不可避免的堆分配,这似乎不是一个划算的做法。
Rust有一个名为impl Trait的特性,正是为这种情况设计的。impl Trait允许我们“擦除”返回值的类型,只指定它实现的一个或多个特征,而无需进行动态分发或堆分配:
fn cyclical_zip(v: Vec<u8>, u: Vec<u8>) -> impl Iterator<Item = u8> {
v.into_iter().chain(u.into_iter()).cycle()
}
2
3
现在,cyclical_zip的签名不再指定特定的嵌套迭代器组合器结构体类型,而只是表明它返回某种u8类型的迭代器。返回类型表达了函数的意图,而不是实现细节。
这确实清理了代码,使其更具可读性,但impl Trait不仅仅是一种方便的简写。使用impl Trait意味着,只要返回的实际类型仍然实现了Iterator<Item = u8>,你将来就可以更改它,并且调用该函数的任何代码都将继续编译,不会出现问题。这为库作者提供了很大的灵活性,因为类型签名中只编码了相关的功能。
例如,如果库的第一个版本使用了前面那样的迭代器组合器,但后来发现了实现相同过程的更好算法,库作者可以使用不同的组合器,甚至创建一个实现Iterator的自定义类型,而库的用户可以在完全不更改代码的情况下获得性能提升。
你可能会想用impl Trait来近似实现面向对象语言中常用的工厂模式的静态分发版本。例如,你可能会定义这样一个特征:
trait Shape {
fn new() -> Self;
fn area(&self) -> f64;
}
2
3
4
在为几种类型实现该特征后,你可能希望根据运行时的值(比如用户输入的字符串)使用不同的Shape。但将impl Shape作为返回类型是行不通的:
fn make_shape(shape: &str) -> impl Shape {
match shape {
"circle" => Circle::new(),
"triangle" => Triangle::new(), // 错误:类型不兼容
"shape" => Rectangle::new(),
}
}
2
3
4
5
6
7
从调用者的角度来看,这样的函数没有什么意义。impl Trait是一种静态分发形式,因此编译器必须在编译时知道函数返回的类型,以便在栈上分配正确数量的空间,并正确访问该类型的字段和方法。在这里,返回类型可能是Circle、Triangle或Rectangle,它们占用的空间可能不同,并且area()方法的实现也不同。
需要注意的是,Rust不允许特征方法使用impl Trait作为返回值。要支持这一点,需要对语言的类型系统进行一些改进。在完成这项工作之前,只有自由函数和与特定类型相关联的函数可以使用impl Trait作为返回值。
impl Trait也可以用于接受泛型参数的函数。例如,考虑这个简单的泛型函数:
fn print<T: Display>(val: T) {
println!("{}", val);
}
2
3
它和使用impl Trait的版本是一样的:
fn print(val: impl Display) {
println!("{}", val);
}
2
3
有一个重要的例外情况。使用泛型允许函数的调用者指定泛型参数的类型,比如print::<i32>(42),而使用impl Trait则不行。
每个impl Trait参数都会被分配一个匿名类型参数,所以impl Trait用于参数的情况仅限于最简单的泛型函数,且参数类型之间没有关系。
# 关联常量
和结构体、枚举一样,特征也可以有关联常量。你可以使用与结构体或枚举相同的语法,声明一个带有关联常量的特征:
trait Greet {
const GREETING: &'static str = "Hello";
fn greet(&self) -> String;
}
2
3
4
不过,特征中的关联常量有特殊的能力。
和关联类型、关联函数一样,你可以声明关联常量,但不赋予其值:
trait Float {
const ZERO: Self;
const ONE: Self;
}
2
3
4
然后,特征的实现者可以定义这些值:
impl Float for f32 {
const ZERO: f32 = 0.0;
const ONE: f32 = 1.0;
}
impl Float for f64 {
const ZERO: f64 = 0.0;
const ONE: f64 = 1.0;
}
2
3
4
5
6
7
8
这允许你编写使用这些值的泛型代码:
fn add_one<T: Float + Add<Output = T>>(value: T) -> T {
value + T::ONE
}
2
3
注意,关联常量不能用于特征对象,因为编译器依赖于实现的类型信息,以便在编译时选择正确的值。
即使是像Float这样没有任何行为的简单特征,结合一些运算符,也可以提供关于一个类型足够的信息,来实现常见的数学函数,比如斐波那契函数:
fn fib<T: Float + Add<Output = T>>(n: usize) -> T {
match n {
0 => T::ZERO,
1 => T::ONE,
n => fib::<T>(n - 1) + fib::<T>(n - 2),
}
}
2
3
4
5
6
7
在最后两节中,我们展示了特征描述类型之间关系的不同方式。所有这些也可以看作是避免虚方法开销和向下转型的方法,因为它们使Rust在编译时能够了解更多具体类型。
# 逆向推导约束条件
当没有一个单一的特征能满足你所有需求时,编写泛型代码可能会非常困难。假设我们编写了这个非泛型函数来进行一些计算:
fn dot(v1: &[i64], v2: &[i64]) -> i64 {
let mut total = 0;
for i in 0..v1.len() {
total = total + v1[i] * v2[i];
}
total
}
2
3
4
5
6
7
现在我们想用相同的代码处理浮点型数值。我们可能会尝试这样做:
fn dot<N>(v1: &[N], v2: &[N]) -> N {
let mut total: N = 0;
for i in 0..v1.len() {
total = total + v1[i] * v2[i];
}
total
}
2
3
4
5
6
7
但并不顺利,Rust抱怨*运算符的使用和0的类型问题。我们可以通过Add和Mul特征,要求N是支持+和*运算的类型。不过,我们对0的使用需要改变,因为在Rust中0始终是整数,对应的浮点型数值是0.0。幸运的是,对于有默认值的类型,Rust有一个标准的Default特征。对于数值类型,默认值总是0。代码如下:
use std::ops::{Add, Mul};
fn dot<N: Add + Mul + Default>(v1: &[N], v2: &[N]) -> N {
let mut total = N::default();
for i in 0..v1.len() {
total = total + v1[i] * v2[i];
}
total
}
2
3
4
5
6
7
8
这样更接近正确答案了,但仍然无法正常工作:
error: mismatched types
|
5 | fn dot<N: Add + Mul + Default>(v1: &[N], v2: &[N]) -> N {
| - this type parameter
...
8 | total = total + v1[i] * v2[i];
| ^^^^^^^^^^^^^ expected type parameter
`N`,
| found associated type
|
= note: expected type parameter `N`
found associated type `<N as Mul>::Output`
help: consider further restricting this bound
|
5 | fn dot<N: Add + Mul + Default + Mul<Output = N>>(v1: &[N],
v2: &[N]) -> N {
| ^^^^^^^^^^^^^^^^^
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
我们的新代码假设两个N类型的值相乘会产生另一个N类型的值,但情况并非一定如此。你可以重载乘法运算符,使其返回任何你想要的类型。我们需要以某种方式告诉Rust,这个泛型函数只适用于具有常规乘法特性的类型,即N * N的结果是N类型。错误信息中的建议基本正确:我们可以将Mul替换为Mul<Output = N>,Add也做同样的替换:
fn dot<N: Add<Output = N> + Mul<Output = N> + Default>(v1: &[N], v2: &[N]) -> N {
...
}
2
3
此时,约束条件开始增多,代码变得难以阅读。我们把约束条件移到where子句中:
fn dot<N>(v1: &[N], v2: &[N]) -> N
where
N: Add<Output = N> + Mul<Output = N> + Default {
...
}
2
3
4
5
很好。但Rust仍然对这行代码报错:
error: cannot move out of type `[N]`, a non-copy slice
|
8 | total = total + v1[i] * v2[i];
| ^^^^^
| |
| cannot move out of here
| move occurs because `v1[_]` has type
`N`,
| which does not implement the `Copy` trait
2
3
4
5
6
7
8
9
由于我们没有要求N是可复制类型,Rust将v1[i]解释为试图从切片中移出一个值,这是不允许的。但我们根本不想修改切片,只是想把值复制出来进行操作。幸运的是,Rust所有的内置数值类型都实现了Copy,所以我们可以简单地将其添加到对N的约束中:
where
N: Add<Output = N> + Mul<Output = N> + Default + Copy
2
这样,代码就可以编译并运行了。最终代码如下:
use std::ops::{Add, Mul};
fn dot<N>(v1: &[N], v2: &[N]) -> N
where
N: Add<Output = N> + Mul<Output = N> + Default + Copy {
let mut total = N::default();
for i in 0..v1.len() {
total = total + v1[i] * v2[i];
}
total
}
#[test]
fn test_dot() {
assert_eq!(dot(&[1, 2, 3, 4], &[1, 1, 1, 1]), 10);
assert_eq!(dot(&[53.0, 7.0], &[1.0, 5.0]), 88.0);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
在Rust中,这种情况时有发生:在与编译器进行一番激烈“争论”后,代码看起来相当不错,就好像编写过程一帆风顺,而且运行效果也很好。
我们在这里所做的,是逆向推导N的约束条件,利用编译器来指导和检查我们的工作。之所以有点麻烦,是因为标准库中没有一个Number特征,能包含我们想要使用的所有运算符和方法。实际上,有一个很受欢迎的开源库num定义了这样一个特征!如果我们早知道,就可以在Cargo.toml中添加num,然后这样编写代码:
use num::Num;
fn dot<N: Num + Copy>(v1: &[N], v2: &[N]) -> N {
let mut total = N::zero();
for i in 0..v1.len() {
total = total + v1[i] * v2[i];
}
total
}
2
3
4
5
6
7
8
就像在面向对象编程中,合适的接口能让一切变得美好一样,在泛型编程中,合适的特征也能让一切变得美好。
不过,为什么要这么麻烦呢?为什么Rust的设计者没有让泛型更像C++模板那样,将约束条件隐含在代码中,类似于“鸭子类型”呢?
Rust这种方式的一个优点是泛型代码的向前兼容性。你可以更改一个公共泛型函数或方法的实现,如果不更改其签名,就不会破坏任何使用它的代码。
约束条件的另一个优点是,当你遇到编译器错误时,至少编译器能告诉你问题出在哪里。涉及模板的C++编译器错误信息可能比Rust的长得多,会指向许多不同的代码行,因为编译器无法判断问题出在模板本身,还是调用它的代码(调用代码也可能是模板),亦或是那个模板的调用者……
也许显式写出约束条件最重要的优点,就是它们在代码和文档中清晰可见。你查看Rust中泛型函数的签名时,就能清楚地知道它接受什么样的参数。而模板就做不到这一点。在像Boost这样的C++库中,完整记录参数类型的工作,比我们这里所经历的还要艰巨,因为Boost的开发者没有编译器来检查他们的工作。
# 特征作为基础
特征是Rust中的主要组织特性之一,这是有充分理由的。围绕一个好的接口来设计程序或库,再合适不过了。
本章充斥着各种语法、规则和解释。现在我们已经打下了基础,就可以开始探讨在Rust代码中使用特征和泛型的多种方式。事实上,我们才刚刚触及皮毛。接下来的两章将介绍标准库提供的常见特征。后续章节还会涉及闭包、迭代器、输入/输出和并发等内容。特征和泛型在所有这些主题中都起着核心作用。