 第15章 迭代器
第15章 迭代器
# 第15章 迭代器
这是漫长一天的结束。 ——菲尔(Phil)
迭代器是一种能生成一系列值的对象,通常供循环操作使用。Rust的标准库提供了遍历向量、字符串、哈希表及其他集合的迭代器,同时也有从输入流生成文本行、处理网络服务器接收到的连接、从通信通道获取其他线程传来的值等功能的迭代器。当然,你也可以为自己的需求实现迭代器。Rust的for循环为使用迭代器提供了自然的语法,而迭代器本身也提供了丰富的方法,用于映射、过滤、连接、收集等操作。
Rust的迭代器灵活、表现力强且效率高。考虑下面这个函数,它返回前n个正整数的和(通常称为第n个三角形数):
fn triangle(n: i32) -> i32 {
let mut sum = 0;
for i in 1..=n {
sum += i;
}
sum
}
2
3
4
5
6
7
表达式1..=n是一个RangeInclusive<i32>值。RangeInclusive<i32>是一个迭代器,它生成从起始值到结束值(包括两端)的整数,所以你可以将它用作for循环的操作数,来计算从1到n的和。
不过,迭代器还有一个fold方法,你可以用它来实现相同功能:
fn triangle(n: i32) -> i32 {
(1..=n).fold(0, |sum, item| sum + item)
}
2
3
fold方法以0作为初始累加值,获取1..=n生成的每个值,并将闭包|sum, item| sum + item应用于当前累加值和该值。闭包的返回值作为新的累加值。它返回的最后一个值就是fold方法本身的返回值,在这个例子中,即整个序列的总和。如果你习惯使用for和while循环,这种方式可能看起来有些奇怪,但一旦习惯了,fold方法是一种清晰简洁的替代方案。
这在函数式编程语言中相当常见,这类语言非常注重表达能力。但Rust的迭代器经过精心设计,以确保编译器能将其转换为优质的机器代码。在上述第二个定义的发布版本构建中,Rust了解fold的定义并将其内联到triangle函数中。接着,闭包|sum, item| sum + item也被内联进去。最后,Rust检查合并后的代码,发现有一种更简单的方法来计算从1到n的和:总和总是等于n * (n + 1) / 2。Rust将triangle函数的整个主体,包括循环、闭包等,都转换为一条乘法指令和其他一些算术运算。
这个例子只是简单的算术运算,但迭代器在更复杂的应用中表现也很出色。它们是Rust提供灵活抽象的又一个例子,在典型使用场景中几乎不会带来额外开销。
在本章中,我们将解释:
Iterator和IntoIterator特性,它们是Rust迭代器的基础。- 典型迭代器管道的三个阶段:从某种值源创建迭代器;通过选择或处理值将一种迭代器转换为另一种;最后消费迭代器生成的值。
- 如何为自己的类型实现迭代器。
迭代器有很多方法,如果你已经掌握了基本概念,略读部分内容也无妨。但迭代器在符合Rust习惯用法的代码中非常常见,熟悉相关工具对于掌握这门语言至关重要。
# Iterator和IntoIterator特性
迭代器是实现了std::iter::Iterator特性的任何值:
trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
... // 许多默认方法
}
2
3
4
5
Item是迭代器生成的值的类型。next方法要么返回Some(v),其中v是迭代器的下一个值,要么返回None表示序列结束。这里我们省略了Iterator的许多默认方法,在本章的其余部分我们将逐个介绍它们。
如果某种类型有自然的迭代方式,那么该类型可以实现std::iter::IntoIterator特性,其into_iter方法接受一个值并返回一个对其进行迭代的迭代器:
trait IntoIterator
where
Self::IntoIter: Iterator<Item = Self::Item>
{
type Item;
type IntoIter: Iterator;
fn into_iter(self) -> Self::IntoIter;
}
2
3
4
5
6
7
8
IntoIter是迭代器值本身的类型,Item是它生成的值的类型。我们将任何实现了IntoIterator的类型称为可迭代类型(iterable),因为只要你需要,就可以对其进行迭代。
Rust的for循环很好地将这些部分结合在一起。要遍历向量的元素,你可以这样写:
println!("There's:");
let v = vec!["antimony", "arsenic", "aluminum", "selenium"];
for element in &v {
println!("{}", element);
}
2
3
4
5
在底层,每个for循环只是对IntoIterator和Iterator方法调用的简写形式:
let mut iterator = (&v).into_iter();
while let Some(element) = iterator.next() {
println!("{}", element);
}
2
3
4
for循环使用IntoIterator::into_iter将其操作数&v转换为迭代器,然后反复调用Iterator::next。每次next返回Some(element)时,for循环就执行其主体;如果返回None,循环结束。
基于这个例子,以下是一些关于迭代器的术语:
- 如前所述,迭代器是实现了
Iterator特性的任何类型。 - 可迭代类型是实现了
IntoIterator特性的任何类型:你可以通过调用其into_iter方法获得一个对其进行迭代的迭代器。在这个例子中,向量引用&v就是可迭代类型。 - 迭代器生成值。
- 迭代器生成的值称为项(items)。这里的项是
"antimony"、"arsenic"等。 - 接收迭代器生成项的代码是消费者(consumer)。在这个例子中,
for循环就是消费者。
虽然for循环总是对其操作数调用into_iter,但你也可以直接将迭代器传递给for循环;例如,当你遍历一个Range时就是这种情况。所有迭代器都会自动实现IntoIterator,其into_iter方法只是返回该迭代器本身。
如果在迭代器返回None之后再次调用它的next方法,Iterator特性并没有规定它应该怎么做。大多数迭代器会再次返回None,但并非所有迭代器都如此。(如果这导致了问题,“fuse” 中介绍的fuse适配器可能会有帮助。)
# 创建迭代器
Rust标准库文档详细说明了每种类型提供何种迭代器,但库遵循一些通用约定,以帮助你快速定位所需内容。
# iter 和 iter_mut 方法
大多数集合类型都提供iter和iter_mut方法,它们返回对该类型进行自然迭代的迭代器,分别生成对每个项的共享引用或可变引用。像&[T]和&mut [T]这样的数组切片也有iter和iter_mut方法。如果你不想让for循环为你处理迭代,这些方法是获取迭代器最常用的方式:
let v = vec![4, 20, 12, 8, 6];
let mut iterator = v.iter();
assert_eq!(iterator.next(), Some(&4));
assert_eq!(iterator.next(), Some(&20));
assert_eq!(iterator.next(), Some(&12));
assert_eq!(iterator.next(), Some(&8));
assert_eq!(iterator.next(), Some(&6));
assert_eq!(iterator.next(), None);
2
3
4
5
6
7
8
这个迭代器的项类型是&i32:每次调用next都会生成对下一个元素的引用,直到到达向量末尾。
每种类型都可以根据自身目的,以最合理的方式实现iter和iter_mut方法。std::path::Path上的iter方法返回一个迭代器,每次生成路径的一个组件:
use std::ffi::OsStr;
use std::path::Path;
let path = Path::new("C:/Users/JimB/Downloads/Fedora.iso");
let mut iterator = path.iter();
assert_eq!(iterator.next(), Some(OsStr::new("C:")));
assert_eq!(iterator.next(), Some(OsStr::new("Users")));
assert_eq!(iterator.next(), Some(OsStr::new("JimB")));
...
2
3
4
5
6
7
8
9
这个迭代器的项类型是&std::ffi::OsStr,这是一种操作系统调用可接受的字符串借用切片。
如果对一种类型有多种常见的迭代方式,该类型通常会为每种遍历方式提供特定的方法,因为普通的iter方法会产生歧义。例如,&str字符串切片类型没有iter方法。相反,如果s是一个&str,那么s.bytes()返回一个迭代器,生成s的每个字节,而s.chars()将内容解释为UTF-8并生成每个Unicode字符。
# IntoIterator 实现
当一种类型实现了IntoIterator特性时,你可以像for循环那样自己调用它的into_iter方法:
// 通常你应该使用HashSet,但它的迭代顺序是不确定的,所以在示例中BTreeSet更合适。
use std::collections::BTreeSet;
let mut favorites = BTreeSet::new();
favorites.insert("Lucy in the Sky With Diamonds".to_string());
favorites.insert("Liebesträume No. 3".to_string());
let mut it = favorites.into_iter();
assert_eq!(it.next(), Some("Liebesträume No. 3".to_string()));
assert_eq!(it.next(), Some("Lucy in the Sky With Diamonds".to_string()));
assert_eq!(it.next(), None);
2
3
4
5
6
7
8
9
10
实际上,大多数集合为共享引用(&T)、可变引用(&mut T)和移动(T)提供了多种IntoIterator实现:
- 给定集合的共享引用时,
into_iter返回一个迭代器,该迭代器生成对其项的共享引用。例如,在前面的代码中,(&favorites).into_iter()会返回一个迭代器,其Item类型是&String。 - 给定集合的可变引用时,
into_iter返回一个迭代器,该迭代器生成对项的可变引用。例如,如果vector是某个Vec<String>,调用(&mut vector).into_iter()会返回一个迭代器,其Item类型是&mut String。 - 当按值传递集合时,
into_iter返回一个迭代器,该迭代器获取集合的所有权并按值返回项;项的所有权从集合转移到消费者,原始集合在这个过程中被消费。例如,前面代码中的favorites.into_iter()调用返回一个迭代器,按值生成每个字符串;消费者获得每个字符串的所有权。当迭代器被丢弃时,BTreeSet中剩余的任何元素也会被丢弃,现在为空的集合也会被释放。
由于for循环会对其操作数应用IntoIterator::into_iter,这三种实现方式就形成了以下习惯用法,用于遍历集合的共享引用或可变引用,或者消费集合并获取其元素的所有权:
for element in &collection { ... }
for element in &mut collection { ... }
for element in collection { ... }
2
3
这些只是对这里列出的IntoIterator实现之一的调用。
并非每种类型都提供这三种实现。例如,HashSet、BTreeSet和BinaryHeap没有在可变引用上实现IntoIterator,因为修改它们的元素可能会违反类型的不变性:修改后的值可能具有不同的哈希值,或者在与相邻元素的顺序关系上发生变化,所以修改元素会导致其位置不正确。
其他类型部分支持可变操作。例如,HashMap和BTreeMap生成对其条目的值的可变引用,但由于前面提到的类似原因,对其键只生成共享引用。
一般原则是,迭代应该高效且可预测,所以Rust完全省略了那些开销大或可能表现出意外行为的实现(例如,重新计算修改后的HashSet条目的哈希值,并可能在后续迭代中再次遇到它们)。
切片实现了IntoIterator的三种变体中的两种;由于切片不拥有其元素,所以不存在 “按值” 的情况。相反,&[T]和&mut [T]的into_iter方法返回一个迭代器,生成对元素的共享引用和可变引用。如果你将底层的切片类型[T]想象成某种集合,这就很好地符合了整体模式。
你可能已经注意到,IntoIterator的前两种变体,即针对共享引用和可变引用的变体,等同于对引用目标调用iter或iter_mut。为什么Rust两者都提供呢?
IntoIterator是使for循环正常工作的特性,显然这是必要的。但当你不使用for循环时,写favorites.iter()比(&favorites).into_iter()更清晰。通过共享引用进行迭代是你经常需要的操作,所以iter和iter_mut在易用性方面仍然很有价值。
IntoIterator在泛型代码中也很有用:你可以使用T: IntoIterator这样的约束,将类型变量T限制为可迭代的类型。或者,你可以写T: IntoIterator<Item = U>,进一步要求迭代生成特定类型U。例如,这个函数输出任何可迭代类型的值,其项可以用"{:?}"格式打印:
use std::fmt::Debug;
fn dump<T, U>(t: T)
where
T: IntoIterator<Item = U>,
U: Debug
{
for u in t {
println!("{:?}", u);
}
}
2
3
4
5
6
7
8
9
10
11
你不能使用iter和iter_mut来编写这个泛型函数,因为它们不是任何特性的方法:大多数可迭代类型只是恰好有这些名称的方法。
# from_fn 和 successors
一种简单通用的生成值序列的方法是提供一个返回这些值的闭包。
给定一个返回Option<T>的函数,std::iter::from_fn会返回一个迭代器,该迭代器通过调用这个函数来生成其项。例如:
use rand::random; // 在Cargo.toml依赖项中:rand = "0.7"
use std::iter::from_fn;
// 生成1000个随机线段的长度,其端点在区间[0, 1]上均匀分布。(这不是你能在`rand_distr`库中找到的分布,但自己实现很容易。)
let lengths: Vec<f64> =
from_fn(|| Some((random::<f64>() - random::<f64>()).abs()))
.take(1000)
.collect();
2
3
4
5
6
7
8
这段代码调用from_fn创建一个生成随机数的迭代器。由于该迭代器总是返回Some,序列永远不会结束,但我们调用take(1000)将其限制为前1000个元素。然后collect将迭代结果构建成一个向量。这是一种高效构建初始化向量的方式;我们将在本章后面的 “构建集合:collect和FromIterator” 中解释原因。
如果每个项都依赖于前一个项,std::iter::successors函数就很有用。你需要提供一个初始项和一个函数,该函数接受一个项并返回下一个项的Option。如果返回None,迭代就结束。例如,这是我们在第2章绘制曼德布洛特集合的程序中,编写escape_time函数的另一种方式:
use num::Complex;
use std::iter::successors;
fn escape_time(c: Complex<f64>, limit: usize) -> Option<usize> {
let zero = Complex { re: 0.0, im: 0.0 };
successors(Some(zero), |&z| { Some(z * z + c) })
.take(limit)
.enumerate()
.find(|(_i, z)| z.norm_sqr() > 4.0)
.map(|(i, _z)| i)
}
2
3
4
5
6
7
8
9
10
11
从zero开始,successors调用通过不断对最后一个点进行平方并加上参数c,在复平面上生成一系列点。在绘制曼德布洛特集合时,我们想知道这个序列是会永远在原点附近循环,还是会趋向无穷远。take(limit)调用设置了我们追踪序列的长度限制,enumerate为每个点编号,将每个点z转换为元组(i, z)。我们使用find查找第一个远离原点足够远的点。find方法返回一个Option:如果存在这样的点,返回Some((i, z)),否则返回None。对Option::map的调用将Some((i, z))转换为Some(i),但None保持不变:这正是我们想要的返回值。
from_fn和successors都接受FnMut闭包,所以你的闭包可以捕获并修改周围作用域中的变量。例如,这个fibonacci函数使用一个move闭包捕获一个变量,并将其用作运行状态:
fn fibonacci() -> impl Iterator<Item = usize> {
let mut state = (0, 1);
std::iter::from_fn(move || {
state = (state.1, state.0 + state.1);
Some(state.0)
})
}
assert_eq!(fibonacci().take(8).collect::<Vec<_>>(), vec![1, 1, 2, 3, 5, 8, 13, 21]);
2
3
4
5
6
7
8
9
注意:from_fn和successors方法非常灵活,你几乎可以将任何对迭代器的使用转换为对其中一个方法的单次调用,并通过传递复杂的闭包来获得所需的行为。但这样做忽略了迭代器提供的清晰展示数据如何在计算中流动的机会,也没有使用常见模式的标准名称。在依赖这两个方法之前,请确保你已经熟悉了本章中的其他迭代器方法;通常有更好的方法来完成任务。
# drain 方法
许多集合类型都提供了一个drain方法,它接受对集合的可变引用,并返回一个迭代器,该迭代器将每个元素的所有权传递给消费者。
然而,与into_iter()方法不同,into_iter()方法按值获取集合并消费它,而drain方法只是借用对集合的可变引用,当迭代器被丢弃时,它会从集合中移除任何剩余元素,并使集合为空。
对于可以通过范围进行索引的类型,如String、向量和VecDeques,drain方法接受一个要移除的元素范围,而不是排空整个序列:
use std::iter::FromIterator;
let mut outer = "Earth".to_string();
let inner = String::from_iter(outer.drain(1..4));
assert_eq!(outer, "Eh");
assert_eq!(inner, "art");
2
3
4
5
6
如果你确实需要排空整个序列,可以使用完整范围..作为参数。
# 其他迭代器来源
前面的章节主要关注向量和HashMap等集合类型,但标准库中还有许多其他类型支持迭代。表15-1总结了一些比较有趣的类型,但实际上还有更多。我们在专门介绍特定类型的章节(即第16、17和18章)中会更详细地介绍其中一些方法。
表15-1 标准库中的其他迭代器
| 类型或特性 | 表达式 | 注释 |
|---|---|---|
std::ops::Range迭代器 | 1..10 | 端点必须是整数类型才能进行迭代。范围包含起始值,不包含结束值。(1..10).step_by(2)生成1, 3, 5, 7, 9。 |
std::ops::RangeFrom | 1.. | 无界迭代。起始值必须是整数。如果值达到类型的限制,可能会导致程序崩溃或溢出。 |
std::ops::RangeInclusive | 1..=10 | 与Range类似,但包含结束值。 |
Option<T> | Some(10).iter() | 行为类似于长度为0(None)或1(Some(v))的向量。 |
Result<T, E> | Ok("blah").iter() | 与Option类似,生成Ok值。 |
Vec<T>,&[T] | v.windows(16) | 生成给定长度的每个连续切片,从左到右。切片之间有重叠。v.chunks(16)生成给定长度的不重叠连续切片,从左到右。v.chunks_mut(1024)与chunks类似,但切片是可变的。v.split(|byte| byte & 1 != 0)根据给定的谓词分隔切片。v.split_mut(...)与上述类似,但生成可变切片。v.rsplit(...)与split类似,但从右到左生成切片。v.splitn(n, ...)与split类似,但最多生成n个切片。 |
String,&str | s.bytes() | 生成UTF-8形式的字节。 |
s.chars() | 生成UTF-8表示的字符。 | |
s.split_whitespace() | 按空白字符分割字符串,生成非空白字符的切片。 | |
s.lines() | 生成字符串的行切片。 | |
s.split('/') | 按给定模式分割字符串,生成匹配之间的切片。模式可以是多种类型:字符、字符串、闭包。 | |
s.matches(char::is_numeric) | 生成与给定模式匹配的切片。 | |
std::collections::HashMapstd::collections::BTreeMapstd::collections::HashSetstd::collections::BTreeSet | map.keys()map.values()map.values_mut()set1.union(set2)set1.intersection(set2) | 生成对映射的键或值的共享引用。 生成对条目的值的可变引用。 生成对 set1和set2并集元素的共享引用。生成对 set1和set2交集元素的共享引用。 |
std::sync::mpsc::Receiver | recv.iter() | 生成从另一个线程通过相应的Sender发送的值。 |
std::io::Read | stream.bytes() | 从I/O流中生成字节。 |
std::io::BufRead | stream.chars() | 将流解析为UTF-8并生成字符。bufstream.lines()将流解析为UTF-8,生成字符串形式的行。bufstream.split(0)按给定字节分割流,生成字节向量Vec<u8>缓冲区。 |
std::fs::ReadDir | std::fs::read_dir(path) | 生成目录项。 |
std::net::TcpListener | listener.incoming() | 生成传入的网络连接。 |
| 自由函数 | std::iter::empty() | 立即返回None。 |
std::iter::once(5) | 生成给定的值,然后结束。 | |
std::iter::repeat("#9") | 永远生成给定的值。 |
# 迭代器适配器
一旦你有了一个迭代器,Iterator特性提供了大量的适配器方法(简称适配器),这些方法接受一个迭代器,并构建一个具有有用行为的新迭代器。为了了解适配器的工作原理,我们将从两个最常用的适配器map和filter开始。然后我们将介绍其余的适配器工具,几乎涵盖了你能想到的从其他序列生成值序列的所有方式:截断、跳过、组合、反转、连接、重复等等。
# map 和 filter
Iterator特性的map适配器允许你通过对迭代器的项应用闭包来转换迭代器。filter适配器允许你使用闭包决定保留哪些项、丢弃哪些项,从而从迭代器中过滤出项。
例如,假设你正在遍历文本行,并希望去除每行的前导和尾随空白字符。标准库的str::trim方法可以从单个&str中去除前导和尾随空白字符,并返回一个从原始字符串借用的新的、已修剪的&str。你可以使用map适配器将str::trim应用于迭代器中的每一行:
let text = " ponies \n giraffes\niguanas\nsquid".to_string();
let v: Vec<&str> = text.lines()
.map(str::trim)
.collect();
assert_eq!(v, ["ponies", "giraffes", "iguanas", "squid"]);
2
3
4
5
text.lines()调用返回一个迭代器,生成字符串的行。对该迭代器调用map会返回第二个迭代器,它将str::trim应用于每一行,并将结果作为其项生成。最后,collect将这些项收集到一个向量中。
map返回的迭代器本身当然也可以进一步进行适配。如果你想从结果中排除“iguanas”,可以这样写:
let text = " ponies \n giraffes\niguanas\nsquid".to_string();
let v: Vec<&str> = text.lines()
.map(str::trim)
.filter(|s| *s != "iguanas")
.collect();
assert_eq!(v, ["ponies", "giraffes", "squid"]);
2
3
4
5
6
这里,filter返回第三个迭代器,它只生成map迭代器中闭包|s| *s != "iguanas"返回true的那些项。迭代器适配器链就像Unix shell中的管道:每个适配器都有单一的目的,从左到右读取时,很清楚序列是如何被转换的。
这些适配器的签名如下:
fn map<B, F>(self, f: F) -> impl Iterator<Item = B>
where
Self: Sized,
F: FnMut(Self::Item) -> B;
fn filter<P>(self, predicate: P) -> impl Iterator<Item = Self::Item>
where
Self: Sized,
P: FnMut(&Self::Item) -> bool;
2
3
4
5
6
7
8
9
在标准库中,map和filter实际上返回特定的不透明结构体类型,分别名为std::iter::Map和std::iter::Filter。然而,仅仅看到它们的名字并没有太大帮助,所以在本书中,我们将写成-> impl Iterator<Item =...>,因为这告诉了我们真正想知道的信息:该方法返回一个生成给定类型项的迭代器。
由于大多数适配器按值接受self,它们要求Self是Sized的(所有常见的迭代器都是如此)。
map迭代器按值将每个项传递给它的闭包,并依次将闭包结果的所有权传递给它的消费者。filter迭代器通过共享引用将每个项传递给它的闭包,并在该项被选择传递给消费者时保留所有权。这就是为什么在示例中必须解引用s才能将其与"iguanas"进行比较:filter迭代器的项类型是&str,所以闭包参数s的类型是&&str。
关于迭代器适配器,有两个重要的点需要注意。
首先,简单地对迭代器调用适配器并不会消费任何项;它只是返回一个新的迭代器,准备根据需要从第一个迭代器中提取项来生成自己的项。在适配器链中,实际执行任何工作的唯一方法是对最终的迭代器调用next。所以在我们前面的示例中,text.lines()方法调用本身实际上并没有从字符串中解析任何行;它只是返回一个迭代器,如果被请求,该迭代器会解析行。同样,map和filter只是返回新的迭代器,如果被请求,它们会进行映射或过滤。在collect开始对filter迭代器调用next之前,不会进行任何工作。
如果你使用有副作用的适配器,这一点尤其重要。例如,这段代码什么都不会打印:
["earth", "water", "air", "fire"]
.iter()
.map(|elt| println!("{}", elt));
2
3
iter调用返回一个遍历数组元素的迭代器,map调用返回第二个迭代器,它将闭包应用于第一个迭代器生成的每个值。但这里没有任何东西实际从整个链中请求一个值,所以next方法永远不会运行。实际上,Rust会对此发出警告:
warning: unused `std::iter::Map` that must be used
|
7 | / ["earth", "water", "air", "fire"]
^
________________________________________________
8 | | .iter() .map( |elt| println!("{}", elt));
|
= note: iterators are lazy and do nothing unless consumed
2
3
4
5
6
7
8
错误消息中的 “lazy” 一词并不是贬义词;它只是一个术语,用于描述任何将计算推迟到需要其值时才进行的机制。Rust的惯例是迭代器应该只做满足每次next调用所需的最少工作;在这个例子中,根本没有这样的调用,所以不会进行任何工作。
第二点重要的是,迭代器适配器是一种零开销的抽象。由于map、filter及其相关方法是泛型的,将它们应用于迭代器会为涉及的特定迭代器类型专门化它们的代码。这意味着Rust有足够的信息将每个迭代器的next方法内联到其消费者中,然后将整个结构作为一个单元转换为机器代码。所以我们前面展示的lines/map/filter迭代器链与你可能手动编写的代码一样高效:
for line in text.lines() {
let line = line.trim();
if line != "iguanas" {
v.push(line);
}
}
2
3
4
5
6
本节的其余部分将介绍Iterator特性上可用的各种适配器。
# filter_map 和 flat_map
map适配器在每个输入项生成一个输出项的情况下很适用。但如果你想在迭代过程中删除某些项而不是处理它们,或者用零个或多个项替换单个项,该怎么办呢?filter_map和flat_map适配器为你提供了这种灵活性。
filter_map适配器与map类似,只不过它允许其闭包将项转换为新项(就像map那样),或者将该项从迭代中删除。因此,它有点像filter和map的组合。它的签名如下:
fn filter_map<B, F>(self, f: F) -> impl Iterator<Item = B>
where
Self: Sized,
F: FnMut(Self::Item) -> Option<B>;
2
3
4
这与map的签名相同,只是这里闭包返回的是Option<B>,而不是简单的B。当闭包返回None时,该项将从迭代中删除;当它返回Some(b)时,b就是filter_map迭代器生成的下一项。
例如,假设你想扫描一个字符串,查找其中由空白字符分隔且可解析为数字的单词,并处理这些数字,同时丢弃其他单词。你可以这样写:
use std::str::FromStr;
let text = "1\nfrond .25 289\n3.1415 estuary\n ";
for number in text
.split_whitespace()
.filter_map(|w| f64::from_str(w).ok())
{
println!("{:4.2}", number.sqrt());
}
2
3
4
5
6
7
8
9
这段代码的输出如下:
1.00
0.50
17.00
1.77
2
3
4
传递给filter_map的闭包尝试使用f64::from_str解析每个由空白字符分隔的切片。这会返回一个Result<f64, ParseFloatError>,.ok()将其转换为Option<f64>:解析错误会变成None,而成功的解析结果会变成Some(v)。filter_map迭代器会丢弃所有None值,并为每个Some(v)生成值v。
但是,为什么要将map和filter融合成这样一个操作,而不是直接使用这两个适配器呢?filter_map适配器在像刚才展示的这种情况下很有用,即判断是否将某项包含在迭代中的最佳方法是实际尝试处理它。你也可以仅使用filter和map来实现相同的功能,但会有点笨拙:
text.split_whitespace()
.map(|w| f64::from_str(w))
.filter(|r| r.is_ok())
.map(|r| r.unwrap())
2
3
4
你可以将flat_map适配器看作是map和filter_map的延续,只不过现在闭包返回的不再是一个项(像map那样)或零个或一个项(像filter_map那样),而是任意数量项的序列。flat_map迭代器生成闭包返回的序列的连接。flat_map的签名如下:
fn flat_map<U, F>(self, f: F) -> impl Iterator<Item = U::Item>
where
F: FnMut(Self::Item) -> U,
U: IntoIterator;
2
3
4
传递给flat_map的闭包必须返回一个可迭代对象,任何类型的可迭代对象都可以。
例如,假设我们有一个将国家映射到其主要城市的表格。给定一个国家列表,我们如何遍历它们的主要城市呢?
use std::collections::HashMap;
let mut major_cities = HashMap::new();
major_cities.insert("Japan", vec!["Tokyo", "Kyoto"]);
major_cities.insert("The United States", vec!["Portland", "Nashville"]);
major_cities.insert("Brazil", vec!["São Paulo", "Brasília"]);
major_cities.insert("Kenya", vec!["Nairobi", "Mombasa"]);
major_cities.insert("The Netherlands", vec!["Amsterdam", "Utrecht"]);
let countries = ["Japan", "Brazil", "Kenya"];
for &city in countries.iter().flat_map(|country| &major_cities[country]) {
println!("{}", city);
}
2
3
4
5
6
7
8
9
10
11
12
13
这段代码的输出如下:
Tokyo
Kyoto
São Paulo
Brasília
Nairobi
Mombasa
2
3
4
5
6
一种理解方式是,对于每个国家,我们获取其城市向量,将所有向量连接成一个单一序列,然后打印该序列。但请记住,迭代器是惰性的:只有for循环对flat_map迭代器的next方法的调用才会导致实际工作的执行。完整的连接序列从未在内存中构建。相反,我们这里有一个小状态机,它从城市迭代器中一次提取一个项,直到迭代器耗尽,然后才为下一个国家生成一个新的城市迭代器。其效果就像一个嵌套循环,但被封装成了一个迭代器来使用。
# flatten
flatten适配器将迭代器的项连接起来,前提是每个项本身是一个可迭代对象:
use std::collections::BTreeMap;
// 一个将城市映射到其公园的表格:每个值都是一个向量。
let mut parks = BTreeMap::new();
parks.insert("Portland", vec!["Mt. Tabor Park", "Forest Park"]);
parks.insert("Kyoto", vec!["Tadasu-no-Mori Forest", "Maruyama Koen"]);
parks.insert("Nashville", vec!["Percy Warner Park", "Dragon Park"]);
// 构建一个包含所有公园的向量。`values`为我们提供一个生成向量的迭代器,然后`flatten`依次生成每个向量的元素。
let all_parks: Vec<_> =
parks.values().flatten().cloned().collect();
assert_eq!(all_parks,
vec!["Tadasu-no-Mori Forest", "Maruyama Koen", "Percy Warner Park",
"Dragon Park", "Mt. Tabor Park", "Forest Park"]);
2
3
4
5
6
7
8
9
10
11
12
13
14
“flatten” 这个名字来源于将两级结构扁平化为一级结构的概念:BTreeMap及其包含公园名称的向量被扁平化为一个生成所有名称的迭代器。
flatten的签名如下:
fn flatten(self) -> impl Iterator<Item = Self::Item::Item>
where
Self::Item: IntoIterator;
2
3
换句话说,底层迭代器的项本身必须实现IntoIterator,这样它实际上就是一个序列的序列。flatten方法然后返回一个对这些序列连接结果进行迭代的迭代器。当然,这是惰性执行的,只有在我们迭代完上一个序列的所有项后,才会从self中提取一个新项。
flatten方法有一些令人惊讶的用法。如果你有一个Vec<Option<...>>,并且只想遍历其中的Some值,flatten就非常好用:
assert_eq!(vec![None, Some("day"), None, Some("one")]
.into_iter()
.flatten()
.collect::<Vec<_>>(),
vec!["day", "one"]);
2
3
4
5
这之所以有效,是因为Option本身实现了IntoIterator,表示一个包含零个或一个元素的序列。None元素对迭代没有贡献,而每个Some元素贡献一个值。同样,你可以使用flatten来遍历Option<Vec<...>>值:None的行为与空向量相同。
Result也实现了IntoIterator,其中Err表示一个空序列,所以对Result值的迭代器应用flatten实际上会剔除所有的Err并将它们丢弃,得到一个包含解包后成功值的流。我们不建议在代码中忽略错误,但当人们认为自己清楚情况时,会使用这个巧妙的技巧。
你可能会发现,有时你实际需要的是flat_map,却误用了flatten。例如,标准库中的str::to_uppercase方法,用于将字符串转换为大写形式,其实现类似如下:
fn to_uppercase(&self) -> String {
self.chars()
.map(char::to_uppercase)
.flatten() // 有更好的方法
.collect()
}
2
3
4
5
6
之所以需要flatten,是因为ch.to_uppercase()返回的不是单个字符,而是一个生成一个或多个字符的迭代器。将每个字符映射为其大写等效字符会得到一个字符迭代器的迭代器,而flatten负责将它们拼接在一起,最终我们可以将其收集到一个String中。
但是,这种map和flatten的组合非常常见,所以Iterator专门提供了flat_map适配器来处理这种情况。(实际上,flat_map在flatten之前被添加到标准库中。)所以前面的代码可以写成:
fn to_uppercase(&self) -> String {
self.chars()
.flat_map(char::to_uppercase)
.collect()
}
2
3
4
5
# take 和 take_while
Iterator特性的take和take_while适配器允许你在迭代一定数量的项之后,或者当一个闭包决定终止时,结束迭代。它们的签名如下:
fn take(self, n: usize) -> impl Iterator<Item = Self::Item>
where
Self: Sized;
fn take_while<P>(self, predicate: P) -> impl Iterator<Item = Self::Item>
where
Self: Sized,
P: FnMut(&Self::Item) -> bool;
2
3
4
5
6
7
8
这两个方法都获取一个迭代器的所有权,并返回一个新的迭代器,该迭代器可能会提前结束序列,传递来自第一个迭代器的项。take迭代器在最多生成n个项之后返回None。take_while迭代器将谓词应用于每个项,对于第一个使谓词返回false的项,它会返回None,并且在后续每次调用next时也返回None。
例如,给定一封电子邮件,其中用空白行将邮件头与邮件正文分隔开,你可以使用take_while仅遍历邮件头:
let message = "To: jimb\r\n\
From: superego <editor@oreilly.com>\r\n\
\r\n\
Did you get any writing done today?\r\n\
When will you stop wasting time plotting fractals?\r\n ";
for header in message.lines().take_while(|l|!l.is_empty()) {
println!("{}", header);
}
2
3
4
5
6
7
8
9
回顾 “字符串字面量” 可知,当字符串中的一行以反斜杠结尾时,Rust不会将下一行的缩进包含在字符串中,所以这个字符串中的任何一行都没有前导空白字符。这意味着message的第三行是空白行。take_while适配器一旦看到这个空白行就会终止迭代,所以这段代码只打印前两行:
To: jimb
From: superego <editor@oreilly.com>
2
# skip 和 skip_while
Iterator特性的skip和skip_while方法是take和take_while的补充:它们从迭代的开头丢弃一定数量的项,或者丢弃项直到闭包找到一个可接受的项,然后原样传递剩余的项。它们的签名如下:
fn skip(self, n: usize) -> impl Iterator<Item = Self::Item>
where
Self: Sized;
fn skip_while<P>(self, predicate: P) -> impl Iterator<Item = Self::Item>
where
Self: Sized,
P: FnMut(&Self::Item) -> bool;
2
3
4
5
6
7
8
skip适配器的一个常见用法是在遍历程序的命令行参数时跳过命令名。在第2章中,我们的最大公约数计算器使用以下代码来遍历命令行参数:
for arg in std::env::args().skip(1) {
...
}
2
3
std::env::args函数返回一个迭代器,将程序的参数作为String类型生成,第一项是程序本身的名称。在这个循环中,我们不想处理这个字符串。对该迭代器调用skip(1)会返回一个新的迭代器,它在第一次调用时丢弃程序名,然后生成所有后续参数。
skip_while适配器使用一个闭包来决定从序列开头丢弃多少个项。你可以像这样遍历上一节中邮件的正文行:
for body in message.lines()
.skip_while(|l|!l.is_empty())
.skip(1) {
println!("{}", body);
}
2
3
4
5
这里使用skip_while跳过非空白行,但该迭代器确实会生成空白行本身 —— 毕竟,闭包对该行返回了false。所以我们也使用skip方法来丢弃它,这样就得到了一个迭代器,其第一项将是邮件正文的第一行。结合上一节中message的声明,这段代码会打印:
Did you get any writing done today?
When will you stop wasting time plotting fractals?
2
# peekable
可窥视(peekable)迭代器允许你查看下一个即将生成的项,而无需实际消费它。你可以通过调用Iterator特性的peekable方法,将任何迭代器转换为可窥视迭代器:
fn peekable(self) -> std::iter::Peekable<Self>
where
Self: Sized;
2
3
这里,Peekable<Self>是一个实现了Iterator<Item = Self::Item>的结构体,Self是底层迭代器的类型。
Peekable迭代器有一个额外的方法peek,它返回一个Option<&Item>:如果底层迭代器已结束,则返回None;否则返回Some(r),其中r是对下一个项的共享引用(注意,如果迭代器的项类型已经是对某个东西的引用,那么这里最终会得到一个引用的引用)。
调用peek会尝试从底层迭代器中提取下一个项,如果有,则将其缓存,直到下一次调用next。Peekable上的所有其他Iterator方法都知道这个缓存:例如,对可窥视迭代器iter调用iter.last()时,会在耗尽底层迭代器后检查缓存。
当你在处理迭代器时,在看到超出预期的内容之前无法确定要消费多少个项时,可窥视迭代器就非常有用。例如,如果你正在从字符流中解析数字,在看到数字后面的第一个非数字字符之前,你无法确定数字在哪里结束:
use std::iter::Peekable;
fn parse_number<I>(tokens: &mut Peekable<I>) -> u32
where
I: Iterator<Item = char>
{
let mut n = 0;
loop {
match tokens.peek() {
Some(r) if r.is_digit(10) => {
n = n * 10 + r.to_digit(10).unwrap();
}
_ => return n
}
tokens.next();
}
}
let mut chars = "226153980,1766319049".chars().peekable();
assert_eq!(parse_number(&mut chars), 226153980);
// 看,`parse_number`没有消费逗号!所以我们来消费它。
assert_eq!(chars.next(), Some(','));
assert_eq!(parse_number(&mut chars), 1766319049);
assert_eq!(chars.next(), None);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
parse_number函数使用peek检查下一个字符,只有当它是数字时才消费它。如果它不是数字或者迭代器已耗尽(即peek返回None),我们就返回已解析的数字,并将下一个字符留在迭代器中,准备被消费。
# fuse
一旦Iterator返回了None,该特性并没有规定如果你再次调用它的next方法,它应该如何表现。大多数迭代器会再次返回None,但并非所有迭代器都如此。如果你的代码依赖于这种行为,可能会遇到意外情况。
fuse适配器接受任何迭代器,并生成一个在首次返回None后肯定会继续返回None的迭代器:
struct Flaky(bool);
impl Iterator for Flaky {
type Item = &'static str;
fn next(&mut self) -> Option<Self::Item> {
if self.0 {
self.0 = false;
Some("totally the last item")
} else {
self.0 = true; // 哎呀!
None
}
}
}
let mut flaky = Flaky(true);
assert_eq!(flaky.next(), Some("totally the last item"));
assert_eq!(flaky.next(), None);
assert_eq!(flaky.next(), Some("totally the last item"));
let mut not_flaky = Flaky(true).fuse();
assert_eq!(not_flaky.next(), Some("totally the last item"));
assert_eq!(not_flaky.next(), None);
assert_eq!(not_flaky.next(), None);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
fuse适配器在需要处理来源不确定的迭代器的泛型代码中可能最为有用。与其期望你处理的每个迭代器都表现良好,不如使用fuse来确保这一点。
# 可逆迭代器和 rev
有些迭代器能够从序列的两端提取项。你可以使用rev适配器反转这样的迭代器。例如,对向量进行迭代时,从向量末尾提取项和从开头提取项一样容易。这样的迭代器可以实现std::iter::DoubleEndedIterator特性,该特性扩展了Iterator:
trait DoubleEndedIterator : Iterator {
fn next_back(&mut self) -> Option<Self::Item>;
}
2
3
你可以将双端迭代器想象成有两个指针,分别标记序列当前的前端和后端。从任一端提取项都会使该指针向另一端移动;当两个指针相遇时,迭代就结束了:
let bee_parts = ["head", "thorax", "abdomen"];
let mut iter = bee_parts.iter();
assert_eq!(iter.next(), Some(&"head"));
assert_eq!(iter.next_back(), Some(&"abdomen"));
assert_eq!(iter.next(), Some(&"thorax"));
assert_eq!(iter.next_back(), None);
assert_eq!(iter.next(), None);
2
3
4
5
6
7
切片的迭代器结构使得这种行为很容易实现:它实际上是一对指向我们尚未生成的元素范围的起始和结束位置的指针;next和next_back只是从其中一端提取一个项。像BTreeSet和BTreeMap这样的有序集合的迭代器也是双端的:它们的next_back方法首先提取最大的元素或条目。一般来说,只要可行,标准库都会提供双端迭代功能。
但并非所有迭代器都能如此轻松地做到这一点:从通道的Receiver接收来自其他线程的值的迭代器,无法预知接收到的最后一个值可能是什么。一般来说,你需要查看标准库文档,以确定哪些迭代器实现了DoubleEndedIterator,哪些没有。
如果一个迭代器是双端的,你可以使用rev适配器反转它:
fn rev(self) -> impl Iterator<Item = Self>
where
Self: Sized + DoubleEndedIterator;
2
3
返回的迭代器也是双端的:它的next和next_back方法只是交换了一下:
let meals = ["breakfast", "lunch", "dinner"];
let mut iter = meals.iter().rev();
assert_eq!(iter.next(), Some(&"dinner"));
assert_eq!(iter.next(), Some(&"lunch"));
assert_eq!(iter.next(), Some(&"breakfast"));
assert_eq!(iter.next(), None);
2
3
4
5
6
大多数迭代器适配器,如果应用于可逆迭代器,会返回另一个可逆迭代器。例如,map和filter会保留可逆性。
# inspect
inspect适配器对于调试迭代器适配器管道很方便,但在生产代码中使用得并不多。它只是将一个闭包应用于每个项的共享引用,然后传递该项。闭包不能影响这些项,但可以进行诸如打印它们或对它们进行断言之类的操作。
这个例子展示了将字符串转换为大写形式会改变其长度的情况:
let upper_case: String = "große".chars()
.inspect(|c| println!("before: {:?}", c))
.flat_map(|c| c.to_uppercase())
.inspect(|c| println!(" after: {:?}", c))
.collect();
assert_eq!(upper_case, "GROSSE");
2
3
4
5
6
小写的德文字母“ß”的大写形式是“SS”,这就是为什么char::to_uppercase返回一个字符迭代器,而不是单个替换字符。前面的代码使用flat_map将to_uppercase返回的所有序列连接成一个String,并在执行过程中打印以下内容:
before: 'g'
after: 'G'
before: 'r'
after: 'R'
before: 'o'
after: 'O'
before: 'ß'
after: 'S'
after: 'S'
before: 'e'
after: 'E'
2
3
4
5
6
7
8
9
10
11
# chain
chain适配器将一个迭代器附加到另一个迭代器之后。更准确地说,i1.chain(i2)返回一个迭代器,它先从i1中提取项,直到i1耗尽,然后从i2中提取项。
chain适配器的签名如下:
fn chain<U>(self, other: U) -> impl Iterator<Item = Self::Item>
where
Self: Sized,
U: IntoIterator<Item = Self::Item>;
2
3
4
换句话说,你可以将一个迭代器与任何生成相同项类型的可迭代对象连接起来。例如:
let v: Vec<i32> = (1..4).chain(vec![20, 30, 40]).collect();
assert_eq!(v, [1, 2, 3, 20, 30, 40]);
2
如果chain迭代器的两个底层迭代器都是可逆的,那么它本身也是可逆的:
let v: Vec<i32> = (1..4).chain(vec![20, 30, 40]).rev().collect();
assert_eq!(v, [40, 30, 20, 3, 2, 1]);
2
chain迭代器会跟踪两个底层迭代器是否都返回了None,并根据情况将next和next_back调用导向其中一个迭代器。
# enumerate
Iterator特性的enumerate适配器会为序列附加一个递增的索引,将一个生成项A、B、C…… 的迭代器,转换为一个生成对(0, A)、(1, B)、(2, C)…… 的迭代器。乍一看,这似乎很简单,但它的使用频率却出奇地高。
消费者可以使用这个索引来区分不同的项,并确定处理每个项的上下文。例如,第2章中绘制曼德布洛特集合的程序将图像分成八个水平条带,并为每个条带分配一个不同的线程。该代码使用enumerate来告诉每个线程其条带对应图像的哪一部分。
它从一个像素的矩形缓冲区开始:
let mut pixels = vec![0; columns * rows];
接下来,它使用chunks_mut将图像分割成水平条带,每个线程对应一个条带:
let threads = 8;
let band_rows = rows / threads + 1;
...
let bands: Vec<&mut [u8]> = pixels.chunks_mut(band_rows * columns).collect();
2
3
4
然后,它遍历这些条带,为每个条带启动一个线程:
for (i, band) in bands.into_iter().enumerate() {
let top = band_rows * i;
// 启动一个线程来渲染`top..top + band_rows`行
...
}
2
3
4
5
每次迭代都会得到一个对(i, band),其中band是线程应该绘制的像素缓冲区的&mut [u8]切片,i是该条带在整个图像中的索引,这要归功于enumerate适配器。根据绘图的边界和条带的大小,这些信息足以让线程确定它被分配到图像的哪一部分,从而确定在band中绘制什么。
你可以将enumerate生成的(索引, 项)对,类比为迭代HashMap或其他关联集合时得到的(键, 值)对。如果你正在迭代一个切片或向量,索引就是该项出现的“键”。
# zip
zip适配器将两个迭代器组合成一个单一的迭代器,该迭代器生成包含来自每个迭代器的一个值的对,就像拉链将两边连接成一条缝一样。当两个底层迭代器中的任何一个结束时,压缩后的迭代器就结束。
例如,你可以通过将无界范围0..与另一个迭代器压缩,得到与enumerate适配器相同的效果:
let v: Vec<_> = (0..).zip("ABCD".chars()).collect();
assert_eq!(v, vec![(0, 'A'), (1, 'B'), (2, 'C'), (3, 'D')]);
2
从这个意义上说,你可以将zip视为enumerate的泛化:enumerate为序列附加索引,而zip可以附加任何任意迭代器的项。我们之前提到enumerate可以帮助为处理项提供上下文;zip是一种更灵活的实现相同功能的方式。
zip的参数不一定是迭代器本身,它可以是任何可迭代对象:
use std::iter::repeat;
let endings = vec!["once", "twice", "chicken soup with rice"];
let rhyme: Vec<_> = repeat("going")
.zip(endings)
.collect();
assert_eq!(rhyme, vec![("going", "once"), ("going", "twice"), ("going", "chicken soup with rice")]);
2
3
4
5
6
7
# by_ref
在本节中,我们一直在为迭代器附加适配器。一旦这样做了,你还能把适配器去掉吗?通常不行:适配器获取底层迭代器的所有权,并且没有提供方法将其归还。
迭代器的by_ref方法借用对迭代器的可变引用,这样你就可以对该引用应用适配器。当你从这些适配器中消费完项后,丢弃它们,借用就结束了,你就可以重新访问原始迭代器。
例如,在本章前面,我们展示了如何使用take_while和skip_while来处理邮件消息的头部行和正文。但是如果你想使用同一个底层迭代器同时进行这两个操作呢?使用by_ref,我们可以使用take_while处理头部,完成后,拿回底层迭代器,take_while会将其留在恰好可以处理邮件正文的位置:
let message = "To: jimb\r\n\
From: id\r\n\
\r\n\
Oooooh, donuts!!\r\n ";
let mut lines = message.lines();
println!("Headers:");
for header in lines.by_ref().take_while(|l|!l.is_empty()) {
println!("{}", header);
}
println!("\nBody:");
for body in lines {
println!("{}", body);
}
2
3
4
5
6
7
8
9
10
11
12
13
lines.by_ref()调用借用了对迭代器的可变引用,take_while迭代器获取的是这个引用的所有权。该迭代器在第一个for循环结束时超出作用域,这意味着借用结束了,所以你可以在第二个for循环中再次使用lines。这段代码会打印以下内容:
Headers:
To: jimb
From: id
Body:
Oooooh, donuts!!
2
3
4
5
6
by_ref适配器的定义很简单:它返回对迭代器的可变引用。然后,标准库包含了这个有点奇怪的实现:
impl<'a, I: Iterator + ?Sized> Iterator for &'a mut I {
type Item = I::Item;
fn next(&mut self) -> Option<I::Item> {
(**self).next()
}
fn size_hint(&self) -> (usize, Option<usize>) {
(**self).size_hint()
}
}
2
3
4
5
6
7
8
9
换句话说,如果I是某种迭代器类型,那么&mut I也是一个迭代器,它的next和size_hint方法委托给它所引用的对象。当你对迭代器的可变引用调用适配器时,适配器获取的是该引用的所有权,而不是迭代器本身的所有权。这只是一个借用,当适配器超出作用域时就结束了。
# cloned、copied
cloned适配器接受一个生成引用的迭代器,并返回一个生成从这些引用克隆的值的迭代器,很像iter.map(|item| item.clone())。当然,被引用的类型必须实现Clone。例如:
let a = ['1', '2', '3', '∞'];
assert_eq!(a.iter().next(), Some(&'1'));
assert_eq!(a.iter().cloned().next(), Some('1'));
2
3
copied适配器的原理相同,但限制更严格:被引用的类型必须实现Copy。像iter.copied()这样的调用大致等同于iter.map(|r| *r)。由于每个实现Copy的类型也都实现了Clone,cloned的通用性更强,但根据项的类型,克隆调用可能会进行任意数量的分配和复制操作。如果你认为因为你的项类型很简单,这种情况永远不会发生,那么最好使用copied,让类型检查器检查你的假设。
# cycle
cycle适配器会返回一个迭代器,它会不断重复底层迭代器生成的序列。底层迭代器必须实现std::clone::Clone,这样cycle才能保存其初始状态,并在每次循环重新开始时复用该状态。例如:
let dirs = ["North", "East", "South", "West"];
let mut spin = dirs.iter().cycle();
assert_eq!(spin.next(), Some(&"North"));
assert_eq!(spin.next(), Some(&"East"));
assert_eq!(spin.next(), Some(&"South"));
assert_eq!(spin.next(), Some(&"West"));
assert_eq!(spin.next(), Some(&"North"));
assert_eq!(spin.next(), Some(&"East"));
2
3
4
5
6
7
8
9
或者,为了充分展示迭代器的用法:
use std::iter::{once, repeat};
let fizzes = repeat("").take(2).chain(once("fizz")).cycle();
let buzzes = repeat("").take(4).chain(once("buzz")).cycle();
let fizzes_buzzes = fizzes.zip(buzzes);
let fizz_buzz = (1..100).zip(fizzes_buzzes)
.map(|tuple|
match tuple {
(i, ("", "")) => i.to_string(),
(_, (fizz, buzz)) => format!("{}{}", fizz, buzz)
});
for line in fizz_buzz {
println!("{}", line);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这段代码实现了一个儿童文字游戏,现在它有时会被用作程序员的面试题。在这个游戏中,玩家轮流数数,将任何能被三整除的数字替换为单词“fizz”,能被五整除的数字替换为“buzz”。能同时被两者整除的数字则变为“fizzbuzz”。
# 消耗迭代器
到目前为止,我们已经介绍了创建迭代器以及将它们适配成新迭代器的方法;在这里,我们将通过展示消耗迭代器的方式来完成整个迭代器相关知识的介绍。
当然,你可以使用for循环来消耗迭代器,或者显式调用next方法,但有许多常见任务你不必反复编写代码来实现。Iterator特性提供了大量方法来处理其中的许多任务。
# 简单累加:count、sum、product
count方法从迭代器中取出元素,直到它返回None,并告诉你取出了多少个元素。下面是一个简短的程序,用于计算标准输入中的行数:
use std::io::prelude::*;
fn main() {
let stdin = std::io::stdin();
println!("{}", stdin.lock().lines().count());
}
2
3
4
5
6
sum和product方法计算迭代器元素的总和或乘积,这些元素必须是整数或浮点数:
fn triangle(n: u64) -> u64 {
(1..=n).sum()
}
assert_eq!(triangle(20), 210);
fn factorial(n: u64) -> u64 {
(1..=n).product()
}
assert_eq!(factorial(20), 2432902008176640000);
2
3
4
5
6
7
8
9
(你可以通过实现std::iter::Sum和std::iter::Product特性来扩展sum和product,使其适用于其他类型,本书中我们不会对此进行描述。)
# max、min
Iterator上的min和max方法返回迭代器生成的最小或最大元素。迭代器的元素类型必须实现std::cmp::Ord,这样元素之间才能相互比较。例如:
assert_eq!([-2, 0, 1, 0, -2, -5].iter().max(), Some(&1));
assert_eq!([-2, 0, 1, 0, -2, -5].iter().min(), Some(&-5));
2
这些方法返回Option<Self::Item>,这样如果迭代器没有生成任何元素,它们就可以返回None。
正如在“等价比较”中所解释的,Rust的浮点类型f32和f64只实现了std::cmp::PartialOrd,而没有实现std::cmp::Ord,所以你不能使用min和max方法来计算一系列浮点数中的最小或最大值。这并不是Rust设计中受欢迎的一点,但这是有意为之的:对于IEEE NaN值,这类函数应该如何处理并不明确。简单地忽略它们可能会掩盖代码中更严重的问题。
如果你知道自己想如何处理NaN值,可以使用max_by和min_by迭代器方法,它们允许你提供自己的比较函数。
# max_by、min_by
max_by和min_by方法返回迭代器生成的最大或最小元素,由你提供的比较函数来确定:
use std::cmp::Ordering;
// 比较两个f64值。如果遇到NaN则panic。
fn cmp(lhs: &f64, rhs: &f64) -> Ordering {
lhs.partial_cmp(rhs).unwrap()
}
let numbers = [1.0, 4.0, 2.0];
assert_eq!(numbers.iter().copied().max_by(cmp), Some(4.0));
assert_eq!(numbers.iter().copied().min_by(cmp), Some(1.0));
let numbers = [1.0, 4.0, std::f64::NAN, 2.0];
assert_eq!(numbers.iter().copied().max_by(cmp), Some(4.0)); // panics
2
3
4
5
6
7
8
9
10
11
12
max_by和min_by方法通过引用将元素传递给比较函数,这样它们就可以高效地处理任何类型的迭代器,所以cmp函数期望通过引用接收参数,即使我们使用了copied来获取一个生成f64元素的迭代器。
# max_by_key、min_by_key
Iterator上的max_by_key和min_by_key方法允许你通过应用于每个元素的闭包来选择最大或最小元素。闭包可以选择元素的某个字段,或者对元素进行计算。
由于你通常感兴趣的是与某些最小值或最大值相关的数据,而不仅仅是极值本身,所以这些函数通常比min和max更有用。它们的签名如下:
fn min_by_key<B: Ord, F>(self, f: F) -> Option<Self::Item>
where
Self: Sized,
F: FnMut(&Self::Item) -> B;
fn max_by_key<B: Ord, F>(self, f: F) -> Option<Self::Item>
where
Self: Sized,
F: FnMut(&Self::Item) -> B;
2
3
4
5
6
7
8
9
也就是说,给定一个接受一个元素并返回任何有序类型B的闭包,返回闭包返回的B值最大或最小的元素,如果没有生成任何元素,则返回None。
例如,如果你需要扫描一个城市哈希表,以找到人口最多和最少的城市,你可以这样写:
use std::collections::HashMap;
let mut populations = HashMap::new();
populations.insert("Portland", 583_776);
populations.insert("Fossil", 449);
populations.insert("Greenhorn", 2);
populations.insert("Boring", 7_762);
populations.insert("The Dalles", 15_340);
assert_eq!(populations.iter().max_by_key(|&(_name, pop)| pop),
Some((&"Portland", &583_776)));
assert_eq!(populations.iter().min_by_key(|&(_name, pop)| pop),
Some((&"Greenhorn", &2)));
2
3
4
5
6
7
8
9
10
11
12
13
闭包|&(_name, pop)| pop应用于迭代器生成的每个元素,并返回用于比较的值——在这种情况下,是城市的人口。返回的值是整个元素,而不仅仅是闭包返回的值。(当然,如果你经常进行这样的查询,你可能会希望安排一种比在表中进行线性搜索更高效的查找条目的方法。)
# 比较元素序列
假设字符串、向量和切片的单个元素可以进行比较,你可以使用<和==运算符来比较它们。虽然迭代器不支持Rust的比较运算符,但它们提供了像eq和lt这样的方法来完成相同的工作,从迭代器中取出一对对元素进行比较,直到得出结果。例如:
let packed = "Helen of Troy";
let spaced = "Helen of Troy";
let obscure = "Helen of Sandusky"; // 人不错,只是不出名
assert!(packed != spaced);
assert!(packed.split_whitespace().eq(spaced.split_whitespace()));
// 这是因为' ' < 'o',所以为真。
assert!(spaced < obscure);
// 这是因为'Troy' > 'Sandusky',所以为真。
assert!(spaced.split_whitespace().gt(obscure.split_whitespace()));
2
3
4
5
6
7
8
9
10
对split_whitespace的调用返回字符串中按空格分隔的单词的迭代器。在这些迭代器上使用eq和gt方法会进行逐词比较,而不是逐字符比较。这些都是可能的,因为&str实现了PartialOrd和PartialEq。
迭代器提供了eq和ne方法用于相等比较,以及lt、le、gt和ge方法用于有序比较。cmp和partial_cmp方法的行为类似于Ord和PartialOrd特性的相应方法。
# any 和 all
any和all方法会将一个闭包应用到迭代器生成的每个元素上,如果闭包对任何一个元素返回true,any就返回true;如果闭包对所有元素都返回true,all就返回true:
let id = "Iterator";
assert!(id.chars().any(char::is_uppercase));
assert!( !id.chars().all(char::is_uppercase));
2
3
这些方法只会消耗确定结果所需数量的元素。例如,如果闭包对某个给定元素返回true,那么any会立即返回true,而不会再从迭代器中取出更多元素。
# position、rposition 和 ExactSizeIterator
position方法会将一个闭包应用到迭代器的每个元素上,并返回闭包返回true的第一个元素的索引。更准确地说,它返回索引的Option类型值:如果闭包对任何元素都不返回true,position就返回None。一旦闭包返回true,它就会停止取出元素。例如:
let text = "Xerxes";
assert_eq!(text.chars().position(|c| c == 'e'), Some(1));
assert_eq!(text.chars().position(|c| c == 'z'), None);
2
3
rposition方法的功能与之相同,只是它从右侧开始搜索。例如:
let bytes = b"Xerxes";
assert_eq!(bytes.iter().rposition(|&c| c == b'e'), Some(4));
assert_eq!(bytes.iter().rposition(|&c| c == b'X'), Some(0));
2
3
rposition方法需要一个可反转的迭代器,这样它才能从序列的右端取出元素。它还需要一个精确大小的迭代器,以便它能像position方法那样分配索引,从左侧的0开始计数。精确大小的迭代器是实现了std::iter::ExactSizeIterator特征(trait)的迭代器:
trait ExactSizeIterator: Iterator {
fn len(&self) -> usize { ... }
fn is_empty(&self) -> bool { ... }
}
2
3
4
len方法返回剩余元素的数量,is_empty方法在迭代完成时返回true。
自然地,并非每个迭代器都能提前知道它会生成多少个元素。例如,前面使用的str::chars迭代器就不知道(因为UTF - 8是一种可变宽度编码),所以你不能在字符串上使用rposition方法。但是字节数组的迭代器肯定知道数组的长度,所以它可以实现ExactSizeIterator。
# fold和rfold
fold方法是一个非常通用的工具,用于在迭代器生成的整个元素序列上累积某种结果。给定一个初始值(我们称之为累加器)和一个闭包,fold会反复将闭包应用到当前累加器和迭代器的下一个元素上。闭包返回的值会作为新的累加器,与下一个元素一起传递给闭包。fold最终返回的是最后的累加器值。如果序列为空,fold就直接返回初始累加器。
许多其他消耗迭代器值的方法都可以通过使用fold来实现:
let a = [5, 6, 7, 8, 9, 10];
assert_eq!(a.iter().fold(0, |n, _| n + 1), 6);
assert_eq!(a.iter().fold(0, |n, i| n + i), 45);
assert_eq!(a.iter().fold(1, |n, i| n * i), 151200);
// max
assert_eq!(a.iter().cloned().fold(i32::min_value(),
std::cmp::max),
10);
2
3
4
5
6
7
8
fold方法的签名如下:
fn fold<A, F>(self, init: A, f: F) -> A
where
Self: Sized,
F: FnMut(A, Self::Item) -> A;
2
3
4
这里,A是累加器的类型。init参数是一个A类型的值,闭包的第一个参数和返回值也是A类型,fold本身的返回值同样是A类型。
注意,累加器值会被移入和移出闭包,所以你可以对非Copy的累加器类型使用fold:
let a = ["Pack", "my", "box", "with", "five", "dozen", "liquor", "jugs"];
// 另请参阅:切片上的`join`方法,它不会在末尾给你多余的空格。
let pangram = a.iter()
.fold(String::new(), |s, w| s + w + " ");
assert_eq!(pangram, "Pack my box with five dozen liquor jugs ");
2
3
4
5
rfold方法与fold方法相同,只是它需要一个双端迭代器,并且从后向前处理元素:
let weird_pangram = a.iter()
.rfold(String::new(), |s, w| s + w + " ");
assert_eq!(weird_pangram, "jugs liquor dozen five with box my Pack ");
2
3
# try_fold和try_rfold
try_fold方法与fold方法类似,不过迭代过程可以提前结束,无需消耗迭代器中的所有值。传递给try_fold的闭包必须返回一个Result类型的值:如果它返回Err(e),try_fold会立即返回Err(e)作为其值。否则,它会使用成功的值继续进行折叠操作。闭包也可以返回一个Option类型的值:返回None会提前结束,结果是折叠值的Option类型值。
下面是一个程序,用于计算从标准输入读取的数字的总和:
use std::error::Error;
use std::io::prelude::*;
use std::str::FromStr;
fn main() -> Result<(), Box<dyn Error>> {
let stdin = std::io::stdin();
let sum = stdin.lock()
.lines()
.try_fold(0, |sum, line| -> Result<u64, Box<dyn Error>> {
Ok(sum + u64::from_str(&line?.trim())?)
})?;
println!("{}", sum);
Ok(())
}
2
3
4
5
6
7
8
9
10
11
12
13
14
缓冲输入流上的lines迭代器生成的元素类型是Result<String, std::io::Error>,并且将String解析为整数也可能会失败。在这里使用try_fold可以让闭包返回Result<u64, ...>类型的值,这样我们就可以使用?运算符将闭包中的错误传播到main函数。
由于try_fold非常灵活,它被用于实现Iterator的许多其他消费方法。例如,下面是all方法的一种实现:
fn all<P>(&mut self, mut predicate: P) -> bool
where
P: FnMut(Self::Item) -> bool,
Self: Sized
{
self.try_fold((), |_, item| {
if predicate(item) { Some(()) } else { None }
}).is_some()
}
2
3
4
5
6
7
8
9
注意,这不能用普通的fold来编写:all方法承诺只要predicate返回false就停止消耗底层迭代器中的元素,但fold总是会消耗整个迭代器。
如果你正在实现自己的迭代器类型,值得研究一下你的迭代器是否可以比Iterator特征的默认定义更高效地实现try_fold。如果你能加快try_fold的速度,那么基于它构建的所有其他方法也会受益。
正如其名称所示,try_rfold方法与try_fold方法相同,只是它从后端而不是前端获取值,并且需要一个双端迭代器。
# nth、nth_back
nth方法接受一个索引n,从迭代器中跳过n个元素,然后返回下一个元素;如果在到达该位置之前序列结束,则返回None。调用.nth(0)等同于.next()。
它不会像适配器那样获取迭代器的所有权,所以你可以多次调用它:
let mut squares = (0..10).map(|i| i*i);
assert_eq!(squares.nth(4), Some(16));
assert_eq!(squares.nth(0), Some(25));
assert_eq!(squares.nth(6), None);
2
3
4
它的签名如下:
fn nth(&mut self, n: usize) -> Option<Self::Item> where Self: Sized;
nth_back方法与之非常相似,只不过它从双端迭代器的后端获取元素。调用.nth_back(0)等同于.next_back():它返回最后一个元素,如果迭代器为空则返回None。
# last
last方法返回迭代器生成的最后一个元素,如果迭代器为空则返回None。它的签名如下:
fn last(self) -> Option<Self::Item>;
例如:
let squares = (0..10).map(|i| i*i);
assert_eq!(squares.last(), Some(81));
2
这个方法会从前端开始消耗迭代器的所有元素,即使迭代器是可反转的。如果你有一个可反转的迭代器,并且不需要消耗它的所有元素,那么你应该直接使用iter.next_back()。
# find、rfind 和 find_map
find方法从迭代器中取出元素,返回第一个使给定闭包返回true的元素;如果在找到合适的元素之前序列结束,则返回None。它的签名是:
fn find<P>(&mut self, predicate: P) -> Option<Self::Item> where Self: Sized,
P: FnMut(&Self::Item) -> bool;
2
rfind方法与之类似,但它需要一个双端迭代器,并且从后向前搜索值,返回最后一个使闭包返回true的元素。
例如,使用“max_by_key, min_by_key”中的城市和人口表,你可以这样写:
assert_eq!(populations.iter().find(|&(_name, &pop)| pop > 1_000_000),
None);
assert_eq!(populations.iter().find(|&(_name, &pop)| pop > 500_000),
Some((&"Portland", &583_776)));
2
3
4
表中没有城市的人口超过一百万,但有一个城市的人口超过了五十万。
有时,你的闭包不仅仅是一个简单的谓词,对每个元素进行布尔判断后就继续处理下一个;它可能更复杂,本身会产生一个有意义的值。在这种情况下,find_map正是你所需要的。它的签名是:
fn find_map<B, F>(&mut self, f: F) -> Option<B> where
F: FnMut(Self::Item) -> Option<B>;
2
这与find类似,只不过闭包返回的不是bool类型,而是某个值的Option类型。find_map会返回第一个值为Some的Option。
例如,如果我们有一个包含每个城市公园信息的数据库,我们可能想查看是否有公园是火山,如果是,则提供公园的名称:
let big_city_with_volcano_park = populations.iter()
.find_map(|(&city, _)| {
if let Some(park) = find_volcano_park(city, &parks) {
// find_map返回这个值,这样调用者就知道我们找到了哪个公园
return Some((city, park.name));
}
// 排除这个元素,继续搜索
None
});
assert_eq!(big_city_with_volcano_park,
Some(("Portland", "Mt. Tabor Park")));
2
3
4
5
6
7
8
9
10
11
# 构建集合:collect和FromIterator
在本书中,我们一直在使用collect方法来构建包含迭代器元素的向量(vector)。例如,在第2章中,我们调用std::env::args()来获取程序命令行参数的迭代器,然后调用该迭代器的collect方法将它们收集到一个向量中:
let args: Vec<String> = std::env::args().collect();
但collect并不局限于向量:实际上,只要迭代器生成合适的元素类型,它可以从Rust标准库中构建任何类型的集合:
use std::collections::{HashSet, BTreeSet, LinkedList, HashMap, BTreeMap};
let args: HashSet<String> = std::env::args().collect();
let args: BTreeSet<String> = std::env::args().collect();
let args: LinkedList<String> = std::env::args().collect();
// 收集到映射(map)中需要(键,值)对,所以在这个例子中,
// 将字符串序列与整数序列进行zip操作。
let args: HashMap<String, usize> = std::env::args().zip(0..).collect();
let args: BTreeMap<String, usize> = std::env::args().zip(0..).collect();
// 等等
2
3
4
5
6
7
8
9
10
11
自然地,collect本身并不知道如何构造所有这些类型。相反,当某个集合类型(如Vec或HashMap)知道如何从迭代器构造自身时,它会实现std::iter::FromIterator特征,而collect只是一个方便的包装:
trait FromIterator<A> : Sized {
fn from_iter<T: IntoIterator<Item = A>>(iter: T) -> Self;
}
2
3
如果一个集合类型实现了FromIterator<A>,那么它的类型关联函数from_iter会从生成A类型元素的可迭代对象中构建该类型的值。
在最简单的情况下,实现可以简单地构造一个空集合,然后逐个添加迭代器中的元素。例如,std::collections::LinkedList对FromIterator的实现就是这样。
然而,有些类型可以做得更好。例如,从某个迭代器iter构造一个向量可以像这样简单:
let mut vec = Vec::new();
for item in iter {
vec.push(item)
}
vec
2
3
4
5
但这并不理想:随着向量的增长,它可能需要扩展其缓冲区,这需要调用堆分配器并复制现有元素。向量确实采取了一些算法措施来降低这种开销,但如果有一种方法可以一开始就分配一个大小合适的缓冲区,那就根本不需要调整大小了。
这就是Iterator特征的size_hint方法发挥作用的地方:
trait Iterator {
...
fn size_hint(&self) -> (usize, Option<usize>) {
(0, None)
}
}
2
3
4
5
6
这个方法返回迭代器将生成的元素数量的下限和可选的上限。默认定义返回下限为零,并且不指定上限,实际上就是说“我不知道”,但许多迭代器可以提供更准确的信息。例如,Range的迭代器确切知道它将生成多少个元素,Vec或HashMap的迭代器也是如此。这样的迭代器为size_hint提供了自己的特定定义。
这些界限正是Vec对FromIterator的实现从一开始就正确调整新向量缓冲区大小所需要的信息。插入操作仍然会检查缓冲区是否足够大,所以即使提示不准确,也只会影响性能,而不会影响安全性。其他类型也可以采取类似的步骤:例如,HashSet和HashMap也使用Iterator::size_hint来为它们的哈希表选择合适的初始大小。
关于类型推断有一点需要注意:在本节开头,看到相同的调用std::env::args().collect()根据上下文生成四种不同类型的集合,这有点奇怪。collect的返回类型是它的类型参数,所以前两个调用等同于以下内容:
let args = std::env::args().collect::<Vec<String>>();
let args = std::env::args().collect::<HashSet<String>>();
2
但只要只有一种类型可能作为collect的参数,Rust的类型推断就会为你提供该类型。当你明确指定args的类型时,就确保了这种情况。
# Extend特征
如果一个类型实现了std::iter::Extend特征,那么它的extend方法会将一个可迭代对象中的元素添加到集合中:
let mut v: Vec<i32> = (0..5).map(|i| 1 << i).collect();
v.extend(&[31, 57, 99, 163]);
assert_eq!(v, &[1, 2, 4, 8, 16, 31, 57, 99, 163]);
2
3
所有的标准集合都实现了Extend,所以它们都有这个方法;String类型也实现了。而数组和切片由于长度固定,没有这个方法。
该特征的定义如下:
trait Extend<A> {
fn extend<T>(&mut self, iter: T)
where
T: IntoIterator<Item = A>;
}
2
3
4
5
显然,这与std::iter::FromIterator非常相似:FromIterator用于创建一个新的集合,而Extend用于扩展一个现有的集合。实际上,标准库中FromIterator的一些实现只是创建一个新的空集合,然后调用extend来填充它。例如,std::collections::LinkedList对FromIterator的实现就是这样:
impl<T> FromIterator<T> for LinkedList<T> {
fn from_iter<I: IntoIterator<Item = T>>(iter: I) -> Self {
let mut list = Self::new();
list.extend(iter);
list
}
}
2
3
4
5
6
7
# partition
partition方法使用一个闭包来决定每个元素的归属,从而将迭代器中的元素划分到两个集合中:
let things = ["doorknob", "mushroom", "noodle", "giraffe", "grapefruit"];
// 有趣的事实:生物的名称总是以奇数位置的字母开头。
let (living, nonliving): (Vec<&str>, Vec<&str>) = things.iter().partition(|name| name.as_bytes()[0] & 1 != 0);
assert_eq!(living, vec!["mushroom", "giraffe", "grapefruit"]);
assert_eq!(nonliving, vec!["doorknob", "noodle"]);
2
3
4
5
与collect类似,partition可以创建任何你想要的集合类型,不过两个集合必须是相同的类型。和collect一样,你需要指定返回类型:前面的示例中写出了living和nonliving的类型,让类型推断为partition调用选择正确的类型参数。
partition的签名如下:
fn partition<B, F>(self, f: F) -> (B, B)
where
Self: Sized,
B: Default + Extend<Self::Item>,
F: FnMut(&Self::Item) -> bool;
2
3
4
5
collect要求其结果类型实现FromIterator,而partition要求实现std::default::Default(Rust的所有集合都通过返回一个空集合来实现该特征)和std::default::Extend。
其他语言提供的partition操作只是将迭代器拆分成两个迭代器,而不是构建两个集合。但这并不适合Rust:从底层迭代器中取出但还未从相应的分区迭代器中取出的元素需要存储在某个地方;无论如何,你最终还是会在内部构建某种类型的集合。
# for_each和try_for_each
for_each方法只是将一个闭包应用到每个元素上:
["doves", "hens", "birds"]
.iter()
.zip(["turtle", "french", "calling"].iter())
.zip(2..5)
.rev()
.map(|((item, kind), quantity)| {
format!("{} {} {}", quantity, kind, item)
})
.for_each(|gift| {
println!("You have received: {}", gift);
});
2
3
4
5
6
7
8
9
10
11
这段代码会输出:
You have received: 4 calling birds
You have received: 3 french hens
You have received: 2 turtle doves
2
3
这与一个简单的for循环非常相似,在for循环中你也可以使用break和continue等控制结构。但是像这样一长串的适配器调用在for循环中会有点别扭:
for gift in ["doves", "hens", "birds"]
.iter()
.zip(["turtle", "french", "calling"].iter())
.zip(2..5)
.rev()
.map(|((item, kind), quantity)| {
format!("{} {} {}", quantity, kind, item)
})
{
println!("You have received: {}", gift);
}
2
3
4
5
6
7
8
9
10
11
被绑定的模式gift,最终可能会与使用它的循环体相距较远。
如果你的闭包可能会出错或者需要提前退出,你可以使用try_for_each:
...
.try_for_each(|gift| {
writeln!(&mut output_file, "You have received: {}", gift)
})?;
2
3
4
# 实现自己的迭代器
你可以为自己定义的类型实现IntoIterator和Iterator特性,这样本章介绍的所有适配器和消费方法都能使用,同时许多为标准迭代器接口编写的其他库和外部包代码也能正常工作。在本节中,我们将展示一个对自定义范围类型的简单迭代器,以及一个对二叉树类型的更复杂迭代器。
假设我们有如下的范围类型(从标准库的std::ops::Range<T>类型简化而来):
struct I32Range {
start: i32,
end: i32
}
2
3
4
对I32Range进行迭代需要两个状态:当前值和迭代结束的界限。这恰好与I32Range类型本身很契合,用start作为下一个值,end作为界限。因此,你可以像这样实现Iterator特性:
impl Iterator for I32Range {
type Item = i32;
fn next(&mut self) -> Option<i32> {
if self.start >= self.end {
return None;
}
let result = Some(self.start);
self.start += 1;
result
}
}
2
3
4
5
6
7
8
9
10
11
这个迭代器生成i32类型的元素,所以Item类型就是i32。如果迭代完成,next方法返回None;否则,它会生成下一个值,并更新自身状态,为下一次调用做准备。
当然,for循环会使用IntoIterator::into_iter将其操作数转换为迭代器。标准库为每一个实现了Iterator的类型都提供了IntoIterator的通用实现,所以I32Range可以直接使用:
let mut pi = 0.0;
let mut numerator = 1.0;
for k in (I32Range { start: 0, end: 14 }) {
pi += numerator / (2 * k + 1) as f64;
numerator /= -3.0;
}
pi *= f64::sqrt(12.0);
// IEEE 754精确规定了这个结果。
assert_eq!(pi as f32, std::f32::consts::PI);
2
3
4
5
6
7
8
9
但I32Range是一个特殊情况,即可迭代对象和迭代器是同一类型。很多情况并非如此简单。例如,下面是第10章中的二叉树类型:
enum BinaryTree<T> {
Empty,
NonEmpty(Box<TreeNode<T>>)
}
struct TreeNode<T> {
element: T,
left: BinaryTree<T>,
right: BinaryTree<T>
}
2
3
4
5
6
7
8
9
10
遍历二叉树的经典方法是递归,利用函数调用栈来记录你在树中的位置以及尚未访问的节点。但是在为BinaryTree<T>实现Iterator时,每次对next的调用都必须恰好生成一个值并返回。为了记录尚未生成的树节点,迭代器必须维护自己的栈。下面是BinaryTree的一种可能的迭代器类型:
use self::BinaryTree::*;
// 中序遍历`BinaryTree`的状态
struct TreeIter<'a, T> {
// 树节点引用的栈。由于我们使用`Vec`的`push`和`pop`方法,栈顶就是向量的末尾。
// 迭代器接下来要访问的节点在栈顶,其尚未访问的祖先节点在它下面。如果栈为空,迭代就结束了。
unvisited: Vec<&'a TreeNode<T>>
}
2
3
4
5
6
7
当我们创建一个新的TreeIter时,它的初始状态应该是即将生成树中最左边的叶节点。根据未访问节点栈的规则,栈顶应该是那个叶节点,后面跟着它未访问的祖先节点,也就是树左边缘的节点。我们可以通过从根节点到叶节点沿着树的左边缘遍历,并将遇到的每个节点压入栈来初始化unvisited,所以我们在TreeIter上定义一个方法来实现这个功能:
impl<'a, T: 'a> TreeIter<'a, T> {
fn push_left_edge(&mut self, mut tree: &'a BinaryTree<T>) {
while let NonEmpty(ref node) = *tree {
self.unvisited.push(node);
tree = &node.left;
}
}
}
2
3
4
5
6
7
8
mut tree允许循环在沿着左边缘向下遍历时改变tree指向的节点,但由于tree是一个共享引用,它不能修改节点本身。
有了这个辅助方法,我们可以为BinaryTree提供一个iter方法,返回一个对树进行迭代的迭代器:
impl<T> BinaryTree<T> {
fn iter(&self) -> TreeIter<T> {
let mut iter = TreeIter { unvisited: Vec::new() };
iter.push_left_edge(self);
iter
}
}
2
3
4
5
6
7
iter方法构造一个unvisited栈为空的TreeIter,然后调用push_left_edge进行初始化。最左边的节点按未访问节点栈的规则最终位于栈顶。
遵循标准库的惯例,我们可以在树的共享引用上实现IntoIterator,通过调用BinaryTree::iter来实现:
impl<'a, T: 'a> IntoIterator for &'a BinaryTree<T> {
type Item = &'a T;
type IntoIter = TreeIter<'a, T>;
fn into_iter(self) -> Self::IntoIter {
self.iter()
}
}
2
3
4
5
6
7
IntoIter的定义将TreeIter确立为&BinaryTree的迭代器类型。
最后,在Iterator的实现中,我们真正开始遍历树。和BinaryTree的iter方法一样,迭代器的next方法也遵循栈的规则:
impl<'a, T> Iterator for TreeIter<'a, T> {
type Item = &'a T;
fn next(&mut self) -> Option<&'a T> {
// 找到本次迭代必须生成的节点,或者结束迭代。(如果是`None`,使用`?`操作符立即返回。)
let node = self.unvisited.pop()?;
// 在`node`之后,我们接下来要生成的是`node`右子树中最左边的子节点,所以沿着这条路径向下压入栈。我们的辅助方法恰好能满足需求。
self.push_left_edge(&node.right);
// 返回对该节点值的引用。
Some(&node.element)
}
}
2
3
4
5
6
7
8
9
10
11
如果栈为空,迭代就完成了。否则,node是对当前要访问节点的引用;这次调用将返回对其element字段的引用。但首先,我们必须将迭代器的状态推进到下一个节点。如果这个节点有右子树,下一个要访问的节点就是右子树的最左边节点,我们可以使用push_left_edge将它及其未访问的祖先节点压入栈中。但如果这个节点没有右子树,push_left_edge不会产生任何效果,这正是我们想要的:我们可以依靠新的栈顶是该节点的第一个未访问祖先节点(如果有的话)。
有了IntoIterator和Iterator的实现,我们终于可以使用for循环通过引用对BinaryTree进行迭代。使用“填充二叉树”中BinaryTree的add方法:
// 构建一棵小树
let mut tree = BinaryTree::Empty;
tree.add("jaeger");
tree.add("robot");
tree.add("droid");
tree.add("mecha");
// 对其进行迭代
let mut v = Vec::new();
for kind in &tree {
v.push(*kind);
}
assert_eq!(v, ["droid", "jaeger", "mecha", "robot"]);
2
3
4
5
6
7
8
9
10
11
12
图15-1展示了在遍历一棵示例树时,未访问节点栈的行为。在每一步,下一个要访问的节点都在栈顶,其所有未访问的祖先节点在它下面。
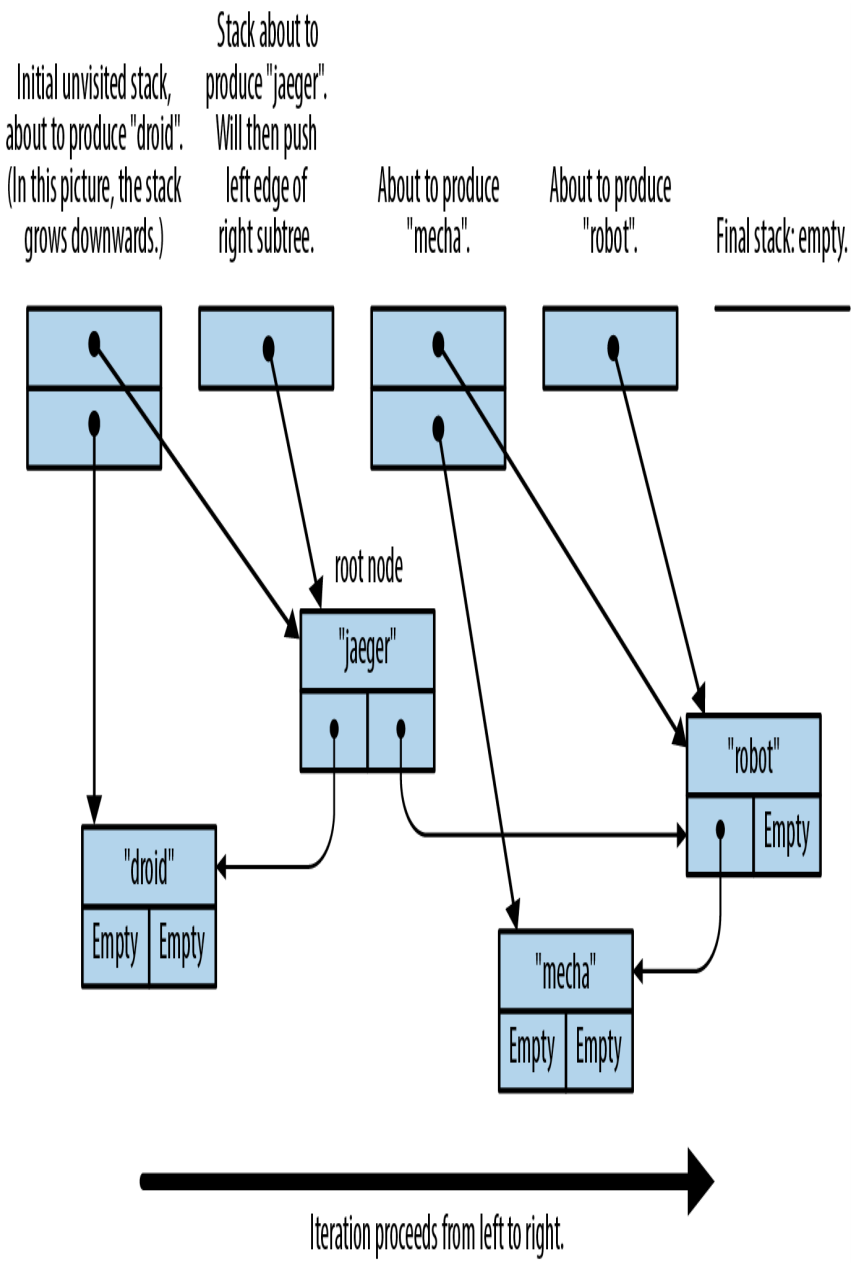 图15-1. 遍历二叉树
图15-1. 遍历二叉树
所有常用的迭代器适配器和消费方法都可以在我们的树上使用:
assert_eq!(tree.iter()
.map(|name| format!("mega-{}", name))
.collect::<Vec<_>>(),
vec!["mega-droid", "mega-jaeger", "mega-mecha", "mega-robot"]);
2
3
4
迭代器体现了Rust提供强大、零成本抽象的理念,这些抽象提高了代码的表达力和可读性。迭代器并没有完全取代循环,但它确实提供了一个强大的原语,具备内置的惰性求值和出色的性能。
注:实际上,由于
Option是一个可迭代对象,其行为类似于包含零个或一个元素的序列,假设闭包返回Option<T>,那么iterator.filter_map(closure)就等同于iterator.flat_map(closure)。