 第16章 集合
第16章 集合
# 第16章 集合
我们的行为都如同麦克斯韦妖。生物体进行着组织活动。在日常经验中,能找到两个世纪以来严谨的物理学家一直热衷于这个奇妙幻想的原因。我们分拣邮件、建造沙堡、玩拼图、扬谷、重新排列棋子、集邮、给书籍按字母顺序排列、创造对称图案、创作十四行诗和奏鸣曲,还会整理房间。只要我们运用智慧,做这些事并不需要消耗太多精力。 ——詹姆斯·格雷克,《信息简史:一部历史,一个理论,一股洪流》
Rust标准库包含多种集合,这些泛型类型用于在内存中存储数据。在本书中,我们已经一直在使用诸如Vec和HashMap等集合。在本章中,我们将详细介绍这两种类型的方法,以及其他几种标准集合。在开始之前,让我们先探讨一下Rust集合与其他语言集合之间的一些系统性差异。
首先,移动(move)和借用(borrowing)无处不在。Rust使用移动语义来避免深度复制值。这就是为什么Vec<T>::push(item)方法按值而不是按引用接收参数。值被移动到向量中。第4章中的图示展示了这在实际中的工作原理:将一个Rust的String类型值压入Vec<String>中很快,因为Rust不必复制字符串的字符数据,并且字符串的所有权始终清晰明确。
其次,Rust没有失效错误(invalidation errors),即那种在程序持有指向集合内部数据的指针时,集合大小调整或发生其他变化导致的悬空指针错误。失效错误是C++中未定义行为的另一个来源,甚至在内存安全的语言中,它也偶尔会引发ConcurrentModificationException异常。Rust的借用检查器在编译时就排除了这类错误。
最后,Rust没有null,所以在其他语言使用null的地方,我们会看到Option类型。
除了这些差异,Rust的集合和你预期的差不多。如果你是一位经验丰富且时间紧迫的程序员,可以快速浏览本章内容,但不要错过“Entries”(条目)部分。
# 概述
表16-1展示了Rust的八种标准集合。它们都是泛型类型。
表16-1. 标准集合概述
| 集合 | 描述 | C++中的类似集合类型 | Java中的类似集合类型 | Python中的类似集合类型 |
|---|---|---|---|---|
Vec<T> | 可增长数组 | vector | ArrayList | list |
VecDeque<T> | 双端队列(可增长的环形缓冲区) | deque | ArrayDeque | collections.deque |
LinkedList<T> | 双向链表 | list | LinkedList | — |
BinaryHeap<T>其中 T: Ord | 最大堆 | priority_queue | PriorityQueue | heapq |
HashMap<K, V>其中 K: Eq + Hash | 键值对哈希表 | unordered_map | HashMap | dict |
BTreeMap<K, V>其中 K: Ord | 有序键值对表 | map | TreeMap | — |
HashSet<T>其中 T: Eq + Hash | 基于哈希的无序集合 | unordered_set | HashSet | set |
BTreeSet<T>其中 T: Ord | 有序集合 | set | TreeSet | — |
Vec<T>、HashMap<K, V>和HashSet<T>是最常用的集合类型。其余的集合有特定的使用场景。本章将依次讨论每种集合类型:
Vec<T>:一种可增长的、在堆上分配的T类型值的数组。本章大约一半的内容将介绍Vec及其众多有用的方法。VecDeque<T>:与Vec<T>类似,但更适合用作先进先出队列。它支持在列表的前端和后端高效地添加和删除值。不过,这会导致其他所有操作稍微变慢。BinaryHeap<T>:一种优先队列。BinaryHeap中的值被组织起来,以便始终能高效地查找和删除最大值。HashMap<K, V>:一种键值对表。通过键查找值的速度很快。条目以任意顺序存储。BTreeMap<K, V>:与HashMap<K, V>类似,但它会按键对条目进行排序。BTreeMap<String, i32>会按String的比较顺序存储其条目。除非你需要条目保持有序,否则HashMap的速度更快。HashSet<T>:一种T类型值的集合。添加和删除值的速度很快,判断给定值是否在集合中也很快。BTreeSet<T>:与HashSet<T>类似,但它会按值对元素进行排序。同样,除非你需要数据有序,否则HashSet的速度更快。
由于LinkedList很少被使用(并且在大多数使用场景中,在性能和接口方面都有更好的替代方案),我们在这里不会对其进行描述 。
# Vec<T>
由于我们在本书中一直在使用Vec,所以假设大家对它有一定的了解。若要了解其入门知识,请参见“Vectors”(向量)。在这里,我们将深入介绍它的方法及其内部工作原理。
创建向量最简单的方法是使用vec!宏:
// 创建一个空向量
let mut numbers: Vec<i32> = vec![];
// 创建一个具有给定内容的向量
let words = vec!["step", "on", "no", "pets"];
let mut buffer = vec![0u8; 1024]; // 1024个归零的字节
2
3
4
5
如第4章所述,向量有三个字段:长度、容量,以及一个指向存储元素的堆分配空间的指针。图16-1展示了上述向量在内存中的样子。空向量numbers最初的容量为0。在添加第一个元素之前,不会为它分配堆内存。
与所有集合一样,Vec实现了std::iter::FromIterator,所以你可以使用迭代器的.collect()方法从任何迭代器创建向量,如“Building Collections: collect and FromIterator”(构建集合:collect和FromIterator)中所述:
// 将另一个集合转换为向量
let my_vec = my_set.into_iter().collect::<Vec<String>>();
2
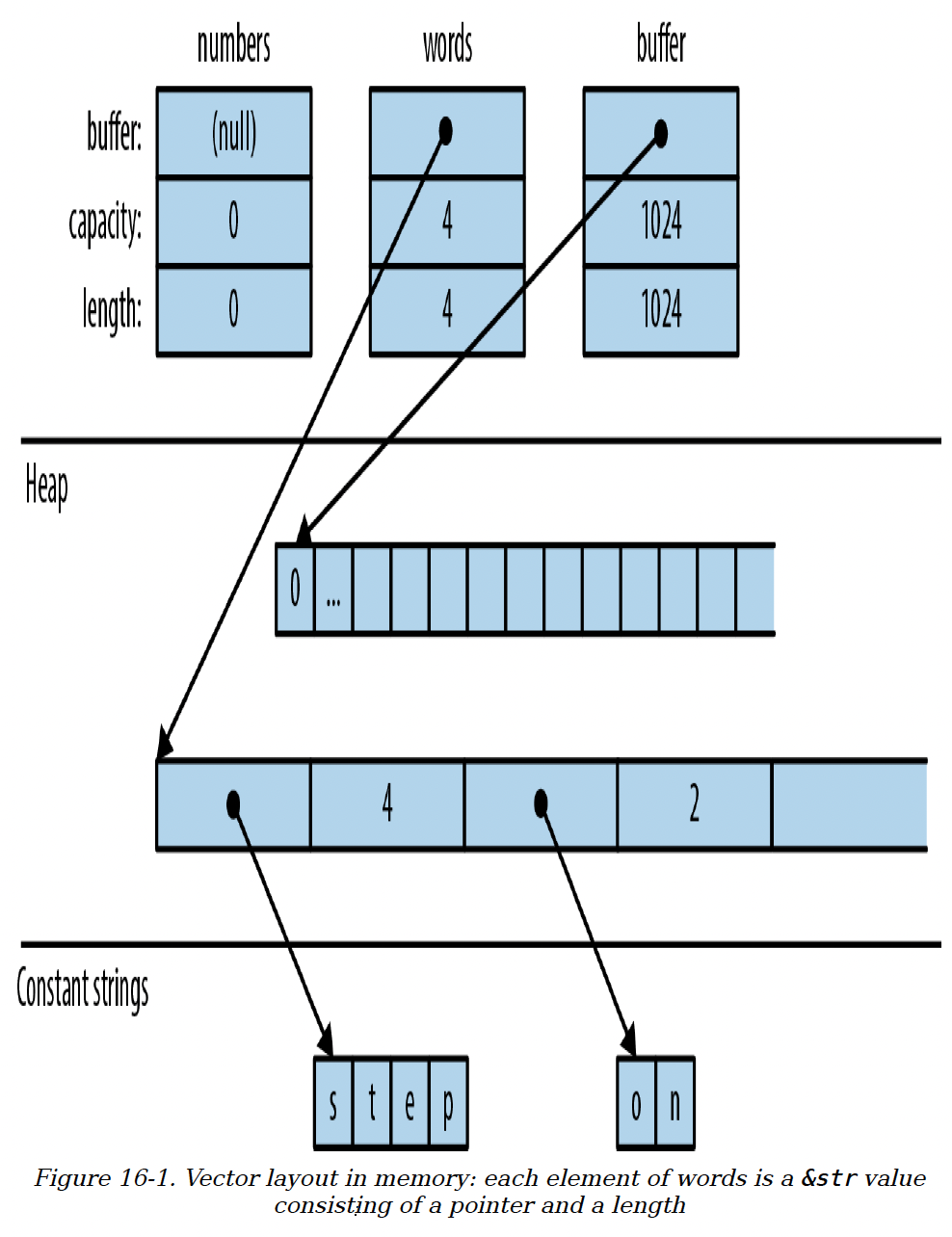 图16-1. 向量在内存中的布局:words中的每个元素都是一个&str值,由一个指针和一个长度组成
图16-1. 向量在内存中的布局:words中的每个元素都是一个&str值,由一个指针和一个长度组成
# 访问元素
通过索引获取数组、切片或向量的元素很简单:
// 获取对元素的引用
let first_line = &lines[0];
// 获取元素的副本
let fifth_number = numbers[4]; // 需要Copy
let second_line = lines[1].clone(); // 需要Clone
// 获取对切片的引用
let my_ref = &buffer[4..12];
// 获取切片的副本
let my_copy = buffer[4..12].to_vec(); // 需要Clone
2
3
4
5
6
7
8
9
如果索引超出范围,所有这些形式都会导致程序恐慌(panic)。
Rust对数值类型要求严格,对向量也不例外。向量的长度和索引的类型是usize。尝试使用u32、u64或isize作为向量索引会出错。你可以根据需要使用n as usize进行类型转换,参见“Type Casts”(类型转换)。
有几个方法可以方便地访问向量或切片的特定元素(请注意,所有切片方法也适用于数组和向量):
slice.first():返回对切片第一个元素的引用(如果有的话)。返回类型是Option<&T>,所以如果切片为空,返回值是None;如果不为空,返回值是Some(&slice[0]):
if let Some(item) = v.first() {
println!("We got one! {}", item);
}
2
3
slice.last():与first()类似,但返回对最后一个元素的引用。slice.get(index):如果slice[index]存在,则返回对它的Some引用。如果切片的元素数量少于index + 1,则返回None:
let slice = [0, 1, 2, 3];
assert_eq!(slice.get(2), Some(&2));
assert_eq!(slice.get(4), None);
2
3
slice.first_mut()、slice.last_mut()、slice.get_mut(index):上述方法的可变借用版本:
let mut slice = [0, 1, 2, 3];
{
let last = slice.last_mut().unwrap(); // last的类型: &mut i32
assert_eq!(*last, 3);
*last = 100;
}
assert_eq!(slice, [0, 1, 2, 100]);
2
3
4
5
6
7
因为按值返回T意味着移动它,所以就地访问元素的方法通常按引用返回这些元素。
.to_vec()方法是个例外,它会进行复制:
slice.to_vec():克隆整个切片,返回一个新的向量:
let v = [1, 2, 3, 4, 5, 6, 7, 8, 9];
assert_eq!(v.to_vec(),
vec![1, 2, 3, 4, 5, 6, 7, 8, 9]);
assert_eq!(v[0..6].to_vec(),
vec![1, 2, 3, 4, 5, 6]);
2
3
4
5
只有当元素是可克隆的,即T: Clone时,这个方法才可用。
# 迭代
向量和切片都是可迭代的,可以按值或按引用迭代,遵循“IntoIterator Implementations”(IntoIterator实现)中描述的模式:
- 对
Vec<T>进行迭代会生成T类型的元素。元素会一个一个地从向量中移出,消耗掉向量。 - 对
&[T; N]、&[T]或&Vec<T>类型的值(即对数组、切片或向量的引用)进行迭代,会生成&T类型的元素,即对单个元素的引用,这些元素不会被移动。 - 对
&mut [T; N]、&mut [T]或&mut Vec<T>类型的值进行迭代会生成&mut T类型的元素。
数组、切片和向量也有.iter()和.iter_mut()方法(在“iter和iter_mut方法”中介绍),用于创建生成对其元素引用的迭代器。
我们将在“Splitting”(拆分)部分介绍一些更高级的切片迭代方式。
# 向量的增长和收缩
数组、切片或向量的长度是其包含的元素数量:
slice.len():返回切片的长度,类型为usize。slice.is_empty():如果切片不包含任何元素(即slice.len() == 0),则返回true。
本节中的其余方法用于向量的增长和收缩。数组和切片一旦创建就不能调整大小,因此它们没有这些方法。
向量的所有元素都存储在堆上分配的一块连续内存中。向量的容量是这块内存能容纳的最大元素数量。Vec通常会为你管理容量,当需要更多空间时,它会自动分配一个更大的缓冲区,并将元素移动到新缓冲区中。也有一些方法可以显式管理容量:
Vec::with_capacity(n):创建一个新的、空的向量,其容量为n。vec.capacity():返回vec的容量,类型为usize。vec.capacity() >= vec.len()始终成立。vec.reserve(n):确保向量至少有足够的空闲容量来容纳n个更多的元素,即vec.capacity()至少为vec.len() + n。如果已经有足够的空间,则此方法不执行任何操作。如果空间不足,则会分配一个更大的缓冲区,并将向量的内容移动到其中。vec.reserve_exact(n):与vec.reserve(n)类似,但告诉vec除了n个元素所需的空间外,不要为未来的增长分配任何额外的容量。之后,vec.capacity()恰好为vec.len() + n。vec.shrink_to_fit():如果vec.capacity()大于vec.len(),则尝试释放多余的内存。
Vec<T>有许多添加或删除元素的方法,这些方法会改变向量的长度。这些方法都通过可变引用接收self参数。
以下两个方法在向量末尾添加或删除单个值:
vec.push(value):将给定的值添加到vec的末尾。vec.pop():删除并返回最后一个元素。返回类型为Option<T>。如果弹出的元素为x,则返回Some(x);如果向量已经为空,则返回None。
请注意,.push()按值而不是按引用接收参数。同样,.pop()返回弹出的值,而不是引用。本节中的大多数其余方法也是如此,它们将值移入和移出向量。
以下两个方法可以在向量的任意位置添加或删除值:
vec.insert(index, value):将给定的值插入到vec[index]处,将vec[index..]中的现有值向右移动一个位置以腾出空间。如果index > vec.len(),则会导致程序恐慌(panic)。vec.remove(index):删除并返回vec[index],将vec[index + 1..]中的现有值向左移动一个位置以填补空缺。如果index >= vec.len(),则会导致程序恐慌,因为在这种情况下不存在要删除的vec[index]元素。
向量越长,此操作就越慢。如果你经常使用vec.remove(0),可以考虑使用VecDeque(在“VecDeque<T>”中介绍)代替Vec。
.insert()和.remove()操作中需要移动的元素越多,速度就越慢。
有四个方法可以将向量的长度更改为特定值:
vec.resize(new_len, value):将vec的长度设置为new_len。如果这会增加vec的长度,则会添加value的副本以填充新空间。元素类型必须实现Clone特性。vec.resize_with(new_len, closure):与vec.resize类似,但调用闭包来构造每个新元素。它可用于元素类型未实现Clone的向量。vec.truncate(new_len):将vec的长度减少到new_len,丢弃vec[new_len..]范围内的任何元素。如果vec.len()已经小于或等于new_len,则不执行任何操作。vec.clear():从vec中删除所有元素,等同于vec.truncate(0)。
有四个方法可以一次添加或删除多个值:
vec.extend(iterable):将给定可迭代值中的所有项按顺序添加到vec的末尾,就像是多值版本的.push()。可迭代参数可以是任何实现了IntoIterator<Item = T>的类型。这个方法非常有用,为此有一个标准特性Extend,所有标准集合都实现了该特性。不幸的是,这会导致rustdoc将.extend()与其他特性方法一起堆放在生成的HTML底部的一大堆方法中,因此在需要时很难找到它。你只需记住它的存在即可!更多内容请参见 “The Extend Trait”(Extend特性)。vec.split_off(index):与vec.truncate(index)类似,但它返回一个Vec<T>,其中包含从vec末尾删除的值,就像是多值版本的.pop()。vec.append(&mut vec2):将vec2中的所有元素移动到vec中,其中vec2是另一个Vec<T>类型的向量。之后,vec2为空。这类似于vec.extend(vec2),但vec2在操作后仍然存在,且其容量不受影响 。vec.drain(range):从vec中删除vec[range]范围的元素,并返回一个对删除元素的迭代器,其中range是一个范围值,如..或0..4。
还有一些特殊的方法用于有选择地删除向量中的某些元素:
vec.retain(test):删除所有未通过给定测试的元素。test参数是一个实现了FnMut(&T) -> bool的函数或闭包。对于vec中的每个元素,都会调用test(&element),如果返回false,则从向量中删除该元素并释放其内存。除了性能方面,这类似于编写:vec = vec.into_iter().filter(test).collect();vec.dedup():删除重复的元素,类似于Unix系统中的uniqshell工具。它扫描vec,查找相邻元素相等的位置,并删除多余的相等值,只保留一个:
let mut byte_vec = b"Misssssssissippi".to_vec();
byte_vec.dedup();
assert_eq!(&byte_vec, b"Misisipi");
2
3
注意,输出中仍然有两个s字符。此方法仅删除相邻的重复项。要消除所有重复项,有三种选择:在调用.dedup()之前对向量进行排序、将数据移动到集合中,或者(为了保持元素的原始顺序)使用这个.retain()技巧:
let mut byte_vec = b"Misssssssissippi".to_vec();
let mut seen = HashSet::new();
byte_vec.retain(|r| seen.insert(*r));
assert_eq!(&byte_vec, b"Misp");
2
3
4
这是因为当集合已经包含我们要插入的项时,.insert()会返回false。
vec.dedup_by(same):与vec.dedup()相同,但它使用函数或闭包same(&mut elem1, &mut elem2)而不是==运算符来检查两个元素是否应被视为相等。vec.dedup_by_key(key):与vec.dedup()相同,但如果key(&mut elem1) == key(&mut elem2),则将两个元素视为相等。例如,如果errors是Vec<Box<dyn Error>>类型,你可以这样写:
// 删除具有重复消息的错误
errors.dedup_by_key(|err| err.to_string());
2
在本节介绍的所有方法中,只有.resize()会克隆值。其他方法都是通过将值从一个地方移动到另一个地方来工作的。
# 连接
有两个方法用于处理数组的数组,这里的数组的数组指的是任何元素本身是数组、切片或向量的数组、切片或向量:
slices.concat():返回一个新向量,该向量由连接所有切片而得:
assert_eq!([[1, 2], [3, 4], [5, 6]].concat(),
vec![1, 2, 3, 4, 5, 6]);
2
slices.join(&separator):与concat()类似,只是在切片之间插入separator值的副本:
assert_eq!([[1, 2], [3, 4], [5, 6]].join(&0),
vec![1, 2, 0, 3, 4, 0, 5, 6]);
2
# 拆分
一次性获取数组、切片或向量的多个不可变引用很容易:
let v = vec![0, 1, 2, 3];
let a = &v[i];
let b = &v[j];
let mid = v.len() / 2;
let front_half = &v[..mid];
let back_half = &v[mid..];
2
3
4
5
6
获取多个可变引用就没那么容易了:
let mut v = vec![0, 1, 2, 3];
let a = &mut v[i];
let b = &mut v[j]; // 错误: 不能同时多次可变借用`v`
*a = 6; // 这里使用了引用`a`和`b`
*b = 7; // 所以它们的生命周期必须重叠
2
3
4
5
Rust禁止这样做,因为如果i == j,那么a和b将是对同一个整数的两个可变引用,这违反了Rust的安全规则(参见 “Sharing Versus Mutation”(共享与变异))。
Rust有几个方法可以一次性借用数组、切片或向量中两个或更多部分的可变引用。与前面的代码不同,这些方法是安全的,因为从设计上看,它们总是将数据拆分为不重叠的区域。这些方法中的许多方法对于处理不可变切片也很方便,所以每个方法都有可变和不可变版本。
图16-2说明了这些方法。
 图16-2. 拆分方法示例(注意:
图16-2. 拆分方法示例(注意:slice.split()输出中的小矩形是由两个相邻分隔符导致的空切片,rsplitn与其他方法不同,它按从后向前的顺序生成输出)
这些方法都不会直接修改数组、切片或向量,它们只是返回对内部数据部分的新引用:
slice.iter()、slice.iter_mut():生成对切片中每个元素的引用,我们在 “Iteration”(迭代)中介绍过它们。slice.split_at(index)、slice.split_at_mut(index):将切片分成两部分,返回一个元组。slice.split_at(index)等同于(&slice[..index], &slice[index..])。如果index超出范围,这些方法会导致程序恐慌(panic)。slice.split_first()、slice.split_first_mut():也返回一个元组:对第一个元素(slice[0])的引用和对其余所有元素(slice[1..])的切片引用。.split_first()的返回类型是Option<(&T, &[T])>,如果切片为空,结果为None。slice.split_last()、slice.split_last_mut():与split_first()类似,但拆分的是最后一个元素而不是第一个元素。.split_last()的返回类型是Option<(&T, &[T])>。slice.split(is_sep)、slice.split_mut(is_sep):使用函数或闭包is_sep来确定拆分位置,将切片拆分为一个或多个子切片,并返回一个对子切片的迭代器。在消耗迭代器时,它会为切片中的每个元素调用is_sep(&element)。如果is_sep(&element)为true,则该元素是分隔符。分隔符不会包含在任何输出子切片中。输出始终至少包含一个子切片,并且每个分隔符会额外产生一个子切片。每当分隔符彼此相邻或与切片的两端相邻时,都会包含空子切片。slice.rsplit(is_sep)、slice.rsplit_mut(is_sep):与slice.split和slice.split_mut类似,但从切片的末尾开始。slice.splitn(n, is_sep)、slice.splitn_mut(n, is_sep):与slice.split类似,但最多生成n个子切片。在找到前n - 1个子切片后,不再调用is_sep。最后一个子切片包含所有剩余元素。slice.rsplitn(n, is_sep)、slice.rsplitn_mut(n, is_sep):与.splitn()和.splitn_mut()类似,只是按相反的顺序扫描切片。也就是说,这些方法在切片的最后n - 1个分隔符处进行拆分,而不是在第一个分隔符处,并且子切片从末尾开始生成。slice.chunks(n)、slice.chunks_mut(n):返回一个对长度为n的不重叠子切片的迭代器。如果n不能整除slice.len(),则最后一个块包含的元素将少于n个。slice.rchunks(n)、slice.rchunks_mut(n):与slice.chunks和slice.chunks_mut类似,但从切片的末尾开始。slice.chunks_exact(n)、slice.chunks_exact_mut(n):返回一个对长度为n的不重叠子切片的迭代器。如果n不能整除slice.len(),则最后一个块(包含少于n个元素)可通过结果的remainder()方法获取。slice.rchunks_exact(n)、slice.rchunks_exact_mut(n):与slice.chunks_exact和slice.chunks_exact_mut类似,但从切片的末尾开始。
还有一个用于迭代子切片的方法:
slice.windows(n):返回一个迭代器,其行为就像在切片数据上的 “滑动窗口”。它生成跨越切片中n个连续元素的子切片。生成的第一个值是&slice[0..n],第二个值是&slice[1..n + 1],依此类推。如果n大于切片的长度,则不会生成任何切片。如果n为0,则该方法会导致程序恐慌(panic)。例如,如果days.len() == 31,那么我们可以通过调用days.windows(7)生成days中所有为期七天的时间段。大小为2的滑动窗口对于探索数据系列从一个数据点到下一个数据点的变化很有用:
let changes = daily_high_temperatures
.windows(2) // 获取相邻两天的温度
.map(|w| w[1] - w[0]) // 温度变化了多少?
.collect::<Vec<_>>();
2
3
4
由于子切片是重叠的,因此该方法没有返回可变引用的版本。
# 交换
有一些方便的方法用于交换切片的内容:
slice.swap(i, j):交换切片中slice[i]和slice[j]这两个元素。slice_a.swap(&mut slice_b):交换slice_a和slice_b的全部内容。slice_a和slice_b的长度必须相同。
向量有一个相关的方法,可高效删除任意元素:
vec.swap_remove(i):删除并返回vec[i]。这与vec.remove(i)类似,但它不是将向量的其余元素移动来填补空缺,而是直接将向量的最后一个元素移动到空缺处。当你不关心留在向量中的元素顺序时,这个方法很有用。
# 排序和搜索
切片提供了三种排序方法:
slice.sort():将元素按升序排序。只有当元素类型实现了Ord时,这个方法才可用。slice.sort_by(cmp):使用函数或闭包cmp来指定排序顺序,对切片中的元素进行排序。cmp必须实现Fn(&T, &T) -> std::cmp::Ordering。除非委托给.cmp()方法,否则手动实现cmp很麻烦:
students.sort_by(|a, b| a.last_name.cmp(&b.last_name));
要按一个字段排序,并使用第二个字段作为平局决胜条件,可以比较元组:
students.sort_by(|a, b| {
let a_key = (&a.last_name, &a.first_name);
let b_key = (&b.last_name, &b.first_name);
a_key.cmp(&b_key)
});
2
3
4
5
slice.sort_by_key(key):根据函数或闭包key给出的排序键,将切片中的元素按升序排序。key的类型必须实现Fn(&T) -> K,其中K: Ord。当T包含一个或多个有序字段,从而可以用多种方式排序时,这个方法很有用:
// 按平均绩点排序,从低到高
students.sort_by_key(|s| s.grade_point_average());
2
注意,在排序过程中不会缓存这些排序键值,因此键函数可能会被调用超过n次。由于技术原因,key(element)不能返回从元素中借用的任何引用。下面这样写是不行的:
students.sort_by_key(|s| &s.last_name); // 错误: 无法推断生命周期
Rust无法确定生命周期。但在这种情况下,使用.sort_by()就足够简单了。
这三种方法都执行稳定排序。
要按降序排序,你可以使用sort_by和一个交换两个参数的cmp闭包。使用|b, a|而不是|a, b|实际上会产生相反的顺序。或者,你也可以在排序后直接调用.reverse()方法:
slice.reverse():就地反转切片。
一旦切片被排序,就可以高效地进行搜索:
slice.binary_search(&value)slice.binary_search_by(&value, cmp)slice.binary_search_by_key(&value, key)
这些方法都在给定的已排序切片中搜索value。注意,value是通过引用传递的。这些方法的返回类型是Result<usize, usize>。如果在指定的排序顺序下,slice[index]等于value,它们就返回Ok(index)。如果不存在这样的index,则返回Err(insertion_point),在insertion_point处插入value可以保持顺序。
当然,二分查找只有在切片实际上按指定顺序排序时才有效。否则,结果是任意的——输入错误,输出也错误。
由于f32和f64有NaN值,它们没有实现Ord,不能直接作为排序和二分查找方法的键。要在浮点数据上使用类似的方法,可以使用ord_subset库。
有一个方法可以在未排序的向量中进行搜索:
slice.contains(&value):如果切片中的任何元素等于value,则返回true。这个方法只是逐个检查切片中的元素,直到找到匹配项。同样,value是通过引用传递的。
要在切片中查找值的位置,就像JavaScript中的array.indexOf(value)一样,可以使用迭代器:
slice.iter().position(|x| *x == value)
这将返回一个Option<usize>。
# 比较切片
如果类型T支持==和!=运算符(PartialEq特性,在“等价比较”中描述),那么数组[T; N]、切片[T]和向量Vec<T>也支持。如果两个切片长度相同且对应元素相等,则它们相等。数组和向量也是如此。
如果T支持<、<=、>和>=运算符(PartialOrd特性,在“有序比较”中描述),那么T类型的数组、切片和向量也支持。切片比较是按字典顺序进行的。
有两个便捷方法用于执行常见的切片比较:
slice.starts_with(other):如果切片以other切片中的元素序列开头,则返回true:
assert_eq!([1, 2, 3, 4].starts_with(&[1, 2]), true);
assert_eq!([1, 2, 3, 4].starts_with(&[2, 3]), false);
2
slice.ends_with(other):与starts_with类似,但检查切片的末尾:
assert_eq!([1, 2, 3, 4].ends_with(&[3, 4]), true);
# 随机元素
Rust标准库中没有内置随机数功能。提供随机数功能的rand库,为从数组、切片或向量中获取随机输出提供了以下两个方法:
slice.choose(&mut rng):返回对切片中随机元素的引用。与slice.first()和slice.last()类似,它返回一个Option<&T>,只有当切片为空时才返回None。slice.shuffle(&mut rng):就地随机重新排列切片中的元素。切片必须通过可变引用传递。
这些是rand::Rng特性的方法,所以你需要一个随机数生成器Rng才能调用它们。幸运的是,通过调用rand::thread_rng()很容易获得一个。要打乱向量my_vec,我们可以这样写:
use rand::seq::SliceRandom;
use rand::thread_rng;
my_vec.shuffle(&mut thread_rng());
2
3
4
# Rust 杜绝失效错误
大多数主流编程语言都有集合和迭代器,并且它们都有类似的规则:在迭代集合时,不要修改它。例如,Python中与向量等价的是列表:
my_list = [1, 3, 5, 7, 9]
假设我们试图从my_list中删除所有大于4的值:
for index, val in enumerate(my_list):
if val > 4:
del my_list[index] # 错误: 在迭代时修改列表
print(my_list)
2
3
4
(enumerate函数相当于Rust中的.enumerate()方法,在“enumerate”中描述。)
令人惊讶的是,这个程序输出[1, 3, 7]。但7大于4,它是怎么漏网的呢?这是一个失效错误:程序在迭代数据时修改了数据,使迭代器失效。在Java中,结果会是抛出一个异常;在C++中,这是未定义行为。在Python中,虽然行为是定义明确的,但不符合直觉:迭代器跳过了一个元素。val永远不会是7。
让我们在Rust中尝试重现这个错误:
fn main() {
let mut my_vec = vec![1, 3, 5, 7, 9];
for (index, &val) in my_vec.iter().enumerate() {
if val > 4 {
my_vec.remove(index); // 错误: 不能可变借用`my_vec`
}
}
println!("{:?}", my_vec);
}
2
3
4
5
6
7
8
9
自然地,Rust在编译时就会拒绝这个程序。当我们调用my_vec.iter()时,它借用了向量的一个共享(不可变)引用。这个引用的生命周期和迭代器一样长,直到for循环结束。在存在不可变引用的情况下,我们不能通过调用my_vec.remove(index)来修改向量。
能指出错误固然很好,但当然,你仍然需要找到一种方法来实现期望的行为!这里最简单的解决方法是这样写:
my_vec.retain(|&val| val <= 4);
或者,你可以像在Python或其他任何语言中那样做:使用过滤器创建一个新向量。
# VecDeque<T>
Vec仅支持在末尾高效地添加和删除元素。当程序需要一个地方来存储 “排队等待” 的值时,Vec可能会很慢。
Rust的std::collections::VecDeque<T>是一个双端队列(发音为 “deck”)。它支持在前端和后端高效地进行添加和删除操作:
deque.push_front(value):在队列前端添加一个值。deque.push_back(value):在队列末尾添加一个值。(这个方法比.push_front()使用得更多,因为队列的通常约定是在末尾添加值,在前端删除值,就像人们排队一样。)deque.pop_front():删除并返回队列的前端值,返回一个Option<T>,如果队列为空则返回None,和vec.pop()类似。deque.pop_back():删除并返回队列末尾的值,同样返回一个Option<T>。deque.front()、deque.back():和vec.first()、vec.last()的功能类似。它们返回对队列前端或后端元素的引用。返回值是Option<&T>,如果队列为空则返回None。deque.front_mut()、deque.back_mut():和vec.first_mut()、vec.last_mut()的功能类似,返回Option<&mut T>。
VecDeque的实现是一个环形缓冲区,如图16-3所示。
和Vec一样,它在堆上有一个单独的分配空间来存储元素。与Vec不同的是,数据并不总是从这个区域的开头开始,并且它可以如图所示那样 “环绕” 到末尾。这个双端队列中的元素依次是['A', 'B', 'C', 'D', 'E']。VecDeque有一些私有字段,在图中标记为start和stop,用于记录数据在缓冲区中的起始和结束位置。
在队列的任一端添加一个值,意味着占用一个未使用的槽位(图中用较深的块表示),如果需要,还会环绕或分配更大的内存块。
VecDeque会管理环绕操作,所以你不必考虑这些。图16-3展示了Rust如何实现快速的.pop_front()操作的内部原理。
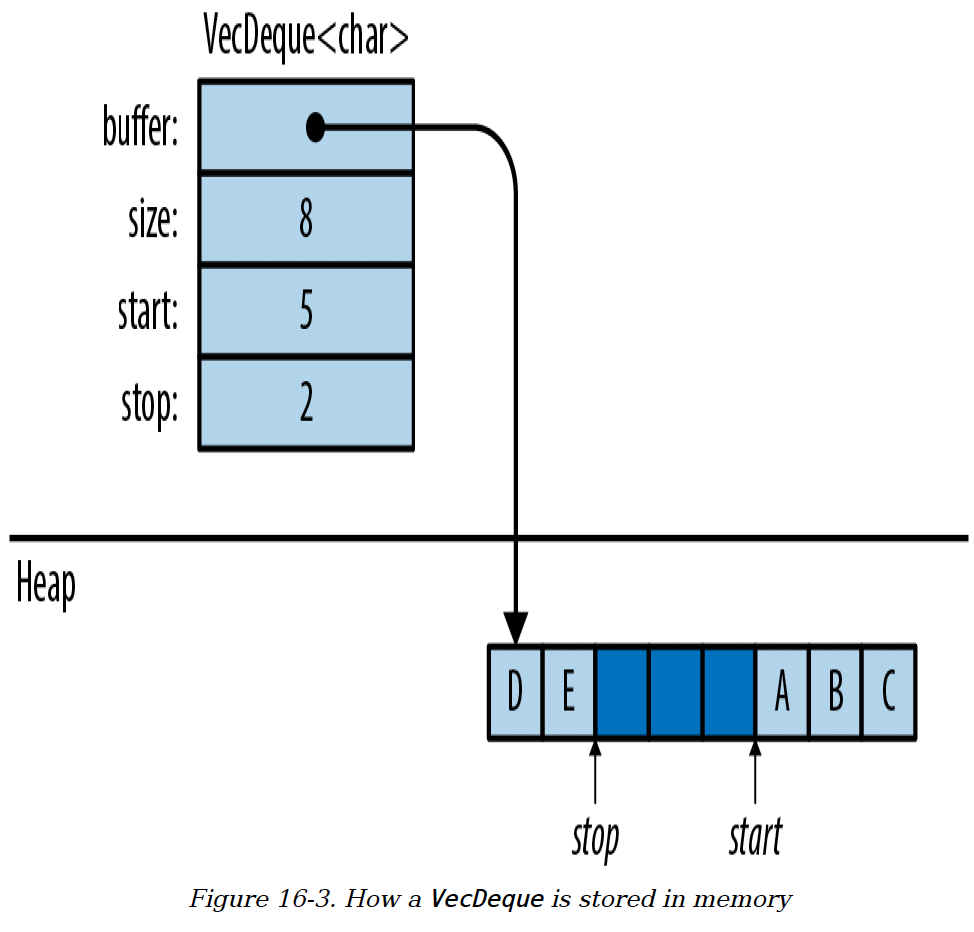 图16-3. VecDeque在内存中的存储方式
图16-3. VecDeque在内存中的存储方式
通常,当你需要一个双端队列时,.push_back()和.pop_front()是你唯一需要的两个方法。用于创建队列的类型关联函数VecDeque::new()和VecDeque::with_capacity(n),与Vec中的对应函数类似。Vec的许多方法也在VecDeque中实现了,比如.len()、.is_empty()、.insert(index, value)、.remove(index)、.extend(iterable)等等。
和向量一样,双端队列可以按值、按共享引用或按可变引用进行迭代。它们有.into_iter()、.iter()和.iter_mut()这三个迭代器方法。它们也可以像平常一样进行索引:deque[index]。
由于双端队列不会在内存中连续存储元素,所以它们不能继承切片的所有方法。但是,如果你愿意付出移动内容的代价,VecDeque提供了一个方法来解决这个问题:
deque.make_contiguous():接受&mut self,将VecDeque重新排列到连续内存中,并返回&mut [T]。
Vec和VecDeque密切相关,标准库提供了两个特性实现,方便在两者之间进行转换:
Vec::from(deque):Vec<T>实现了From<VecDeque<T>>,所以这会将一个双端队列转换为向量。这需要$O(n)$的时间,因为可能需要重新排列元素。VecDeque::from(vec):VecDeque<T>实现了From<Vec<T>>,所以这会将一个向量转换为双端队列。这也是$O(n)$的时间,但通常很快,即使向量很大,因为向量在堆上的分配空间可以直接移动到新的双端队列中。
这个方法使得创建一个包含指定元素的双端队列变得很容易,尽管没有标准的vec_deque![]宏:
use std::collections::VecDeque;
let v = VecDeque::from(vec![1, 2, 3, 4]);
2
3
# BinaryHeap<T>
BinaryHeap是一种集合,其元素保持松散的组织方式,使得最大的值总是会 “冒泡” 到队列的前端。以下是BinaryHeap最常用的三个方法:
heap.push(value):向堆中添加一个值。heap.pop():从堆中删除并返回最大的值。它返回一个Option<T>,如果堆为空则返回None。heap.peek():返回对堆中最大的值的引用。返回类型是Option<&T>。heap.peek_mut():返回一个PeekMut<T>,它相当于对堆中最大的值的可变引用,并提供类型关联函数pop(),用于从堆中弹出这个值。使用这个方法,我们可以根据最大值来选择是否从堆中弹出值:
use std::collections::binary_heap::PeekMut;
if let Some(top) = heap.peek_mut() {
if *top > 10 {
PeekMut::pop(top);
}
}
2
3
4
5
6
7
BinaryHeap还支持Vec的部分方法,包括BinaryHeap::new()、.len()、.is_empty()、.capacity()、.clear()和.append(&mut heap2)。
例如,假设我们用一些数字填充一个BinaryHeap:
use std::collections::BinaryHeap;
let mut heap = BinaryHeap::from(vec![2, 3, 8, 6, 9, 5, 4]);
2
3
值9位于堆的顶部:
assert_eq!(heap.peek(), Some(&9));
assert_eq!(heap.pop(), Some(9));
2
删除值9也会对其他元素进行轻微的重新排列,使得8现在位于前端,依此类推:
assert_eq!(heap.pop(), Some(8));
assert_eq!(heap.pop(), Some(6));
assert_eq!(heap.pop(), Some(5));
...
2
3
4
当然,BinaryHeap并不局限于数字。它可以存储任何实现了内置Ord特性的类型的值。这使得BinaryHeap作为工作队列很有用。你可以定义一个task结构体,根据优先级实现Ord,以便高优先级的任务大于低优先级的任务。然后,创建一个BinaryHeap来存储所有待处理的任务。它的.pop()方法将始终返回最重要的项目,即你的程序接下来应该处理的任务。
注意:BinaryHeap是可迭代的,并且有一个.iter()方法,但迭代器以任意顺序生成堆中的元素,而不是从大到小。要按优先级顺序消费BinaryHeap中的值,可以使用while循环:
while let Some(task) = heap.pop() {
handle(task);
}
2
3
# HashMap<K, V> 和 BTreeMap<K, V>
映射(map)是键值对(称为条目)的集合。没有两个条目具有相同的键,并且条目被组织起来,这样如果你有一个键,就可以在映射中高效地查找相应的值。简而言之,映射就是一个查找表。
Rust提供了两种映射类型:HashMap<K, V>和BTreeMap<K, V>。这两种类型有很多相同的方法;它们的区别在于如何组织条目以实现快速查找。
HashMap将键和值存储在哈希表中,因此它要求键类型K实现Hash和Eq,这是用于哈希和相等比较的标准特性。
图16-4展示了HashMap在内存中的布局。较深的区域是未使用的。所有的键、值和缓存的哈希码都存储在一个堆分配的表中。添加条目最终会迫使HashMap分配一个更大的表,并将所有数据移动到新表中。
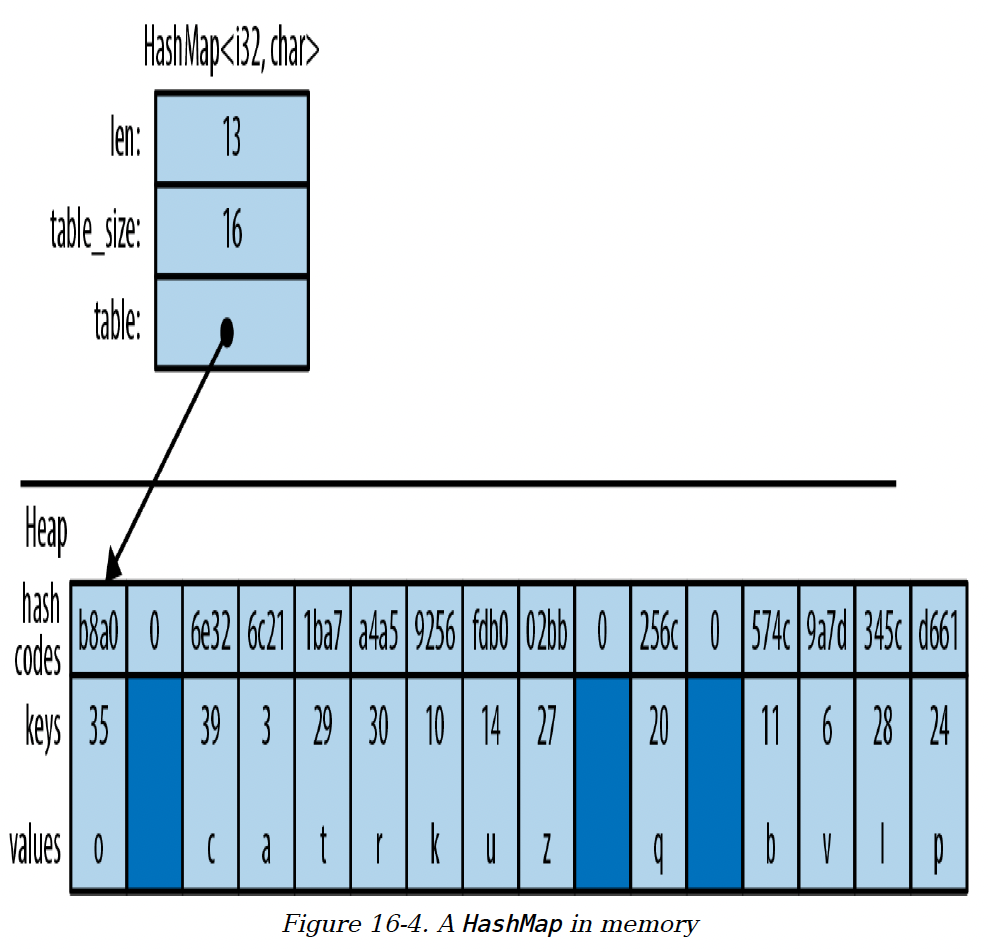
图16-4. 内存中的HashMap
BTreeMap按键的顺序将条目存储在树结构中,因此它要求键类型K实现Ord。图16-5展示了一个BTreeMap。同样,较深的区域是未使用的空闲容量。
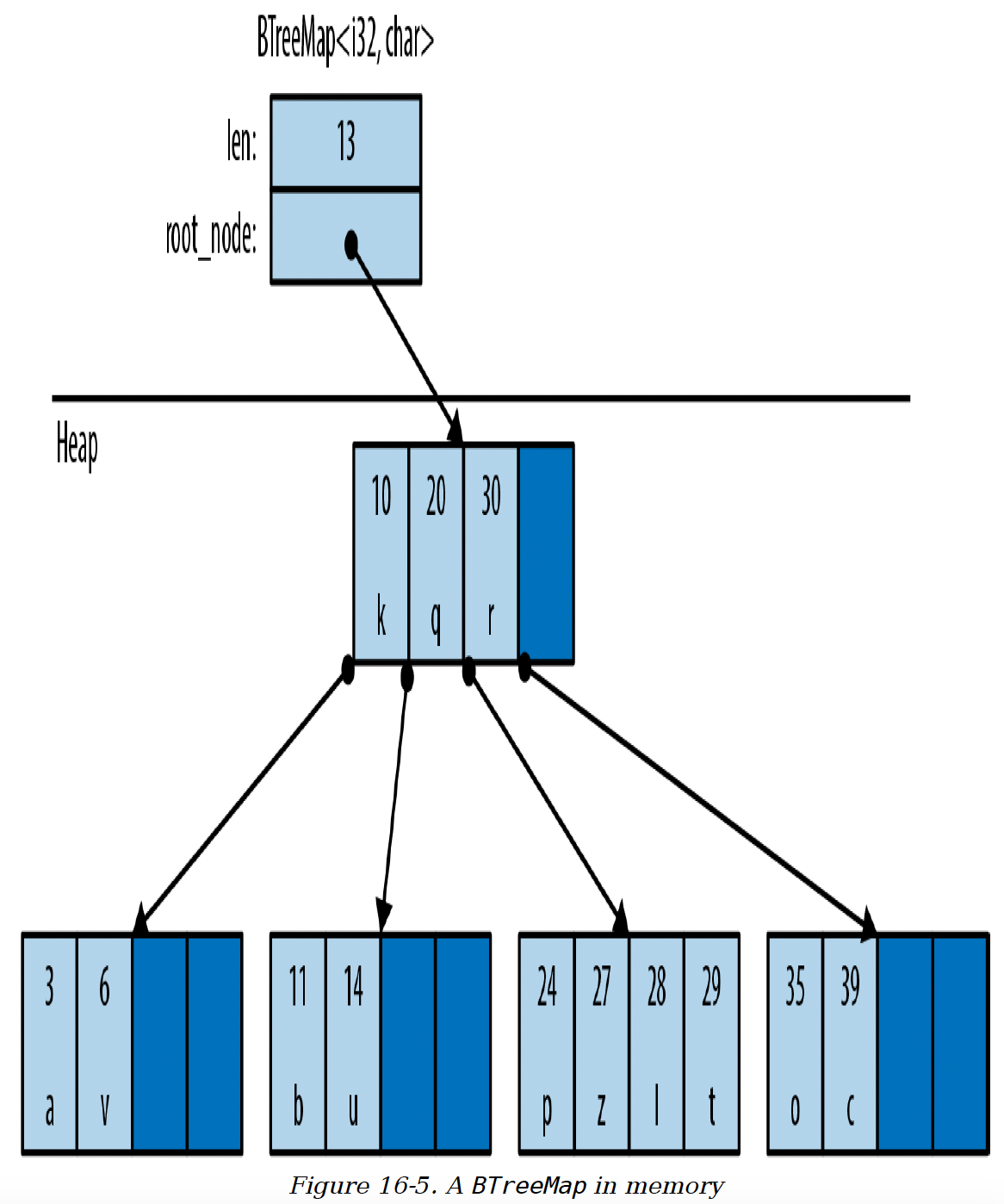 图16-5. 内存中的BTreeMap
图16-5. 内存中的BTreeMap
BTreeMap将其条目存储在节点中。BTreeMap中的大多数节点只包含键值对。非叶节点(如图中所示的根节点)也有空间存储指向子节点的指针。在(20, 'q')和(30, 'r')之间的指针指向一个包含20到30之间键的子节点。
添加条目通常需要将某个节点的现有条目向右移动,以保持它们的排序,偶尔还需要分配新的节点。
为了在页面上展示,这个图做了一些简化。例如,实际的BTreeMap节点有空间存储11个条目,而不是4个。
Rust标准库使用B树而不是平衡二叉树,因为在现代硬件上B树速度更快。二叉树每次搜索可能比B树使用更少的比较次数,但搜索B树具有更好的局部性,也就是说,内存访问是集中在一起的,而不是分散在整个堆中。这使得CPU缓存未命中的情况更少见,从而显著提高了速度。
有几种创建映射的方法:
HashMap::new()、BTreeMap::new():创建新的空映射。iter.collect():可用于从键值对创建并填充新的HashMap或BTreeMap。iter必须是Iterator<Item=(K, V)>类型。HashMap::with_capacity(n):创建一个新的空哈希映射,至少有容纳n个条目的空间。与向量类似,HashMap将数据存储在单个堆分配中,因此它们有容量以及相关的方法hash_map.capacity()、hash_map.reserve(additional)和hash_map.shrink_to_fit()。BTreeMap没有这些。
HashMap和BTreeMap有相同的核心方法来处理键和值:
map.len():返回条目的数量。map.is_empty():如果映射没有条目,则返回true。map.contains_key(&key):如果映射中有给定键的条目,则返回true。map.get(&key):在映射中搜索具有给定键的条目。如果找到匹配的条目,则返回Some(r),其中r是对相应值的引用。否则,返回None。map.get_mut(&key):与map.get(&key)类似,但返回对值的可变引用。
一般来说,映射允许你对存储在其中的值进行可变访问,但不能对键进行可变访问。你可以随意修改值。键属于映射本身,映射需要确保键不会改变,因为条目是根据键来组织的。就地修改键是一个错误。
map.insert(key, value):将条目(key, value)插入到映射中,并返回旧值(如果有的话)。返回类型是Option<V>。如果映射中已经有key的条目,新插入的值将覆盖旧值。map.extend(iterable):遍历iterable中的(K, V)项,并将每个键值对插入到映射中。map.append(&mut map2):将map2中的所有条目移动到map中。之后,map2为空。map.remove(&key):在映射中查找并删除具有给定键的任何条目,如果找到则返回删除的值。返回类型是Option<V>。map.remove_entry(&key):在映射中查找并删除具有给定键的任何条目,如果找到则返回删除的键和值。返回类型是Option<(K, V)>。map.retain(test):删除所有未通过给定测试的元素。test参数是一个实现了FnMut(&K, &mut V) -> bool的函数或闭包。对于映射中的每个元素,都会调用test(&key, &mut value),如果返回false,则从映射中删除该元素并释放其内存。除了性能方面,这类似于编写:map = map.into_iter().filter(test).collect();map.clear():删除所有条目。
映射也可以使用方括号进行查询:map[&key]。也就是说,映射实现了内置的Index特性。然而,如果没有给定键的条目,这会导致程序恐慌(panic),就像数组越界访问一样,所以只有在确定要查找的条目已被填充的情况下,才使用这种语法。
.contains_key()、.get()、.get_mut()和.remove()的键参数不一定必须是精确的&K类型。这些方法对于可以从K借用的类型是泛型的。在HashMap<String, Fish>上调用fish_map.contains_key("conger")是可以的,即使"conger"并不完全是String类型,因为String实现了Borrow<&str>。详细信息,请参见 “Borrow and BorrowMut”(Borrow和BorrowMut)。
因为BTreeMap<K, V>按键对其条目进行排序,所以它支持一个额外的操作:
btree_map.split_off(&key):将btree_map分成两部分。键小于key的条目留在btree_map中。返回一个新的BTreeMap<K, V>,其中包含其他条目。
# 条目
HashMap和BTreeMap都有对应的Entry类型。条目(Entry)的意义在于消除重复的映射查找。
例如,下面这段代码用于获取或创建学生记录:
// 我们已经有这个学生的记录了吗?
if!student_map.contains_key(name) {
// 没有:创建一个。
student_map.insert(name.to_string(), Student::new());
}
// 现在肯定有记录了。
let record = student_map.get_mut(name).unwrap();
...
2
3
4
5
6
7
8
这段代码可以正常工作,但它访问student_map两到三次,每次都进行相同的查找操作。
使用条目(Entry)的思路是,我们只进行一次查找,生成一个Entry值,然后用于所有后续操作。下面这一行代码与前面的所有代码等效,但它只进行了一次查找:
let record = student_map.entry(name.to_string()).or_insert_with(Student::new);
student_map.entry(name.to_string())返回的Entry值,就像是对映射中某个位置的可变引用,这个位置要么被一个键值对占据,要么为空,即还没有条目。如果为空,条目的.or_insert_with()方法会插入一个新的Student。大多数对条目的使用都是这样:简洁明了。
所有的Entry值都是由同一个方法创建的:
map.entry(key):返回给定键的Entry。如果映射中没有这个键,就返回一个空的Entry。这个方法通过可变引用接收self参数,并返回一个具有匹配生命周期的Entry:
pub fn entry<'a>(&'a mut self, key: K) -> Entry<'a, K, V>
Entry类型有一个生命周期参数'a,因为它实际上是一种对映射的特殊借用可变引用。只要Entry存在,它就对映射具有独占访问权。
在 “Structs Containing References”(包含引用的结构体)中,我们了解了如何在类型中存储引用以及这对生命周期的影响。现在我们从用户的角度来看这是怎样的。这就是Entry的工作原理。
遗憾的是,如果映射的键类型是String,就不能将&str类型的引用传递给这个方法。在这种情况下,.entry()方法需要一个真正的String。
Entry值提供了三个方法来处理空条目:
map.entry(key).or_insert(value):确保映射包含具有给定键的条目,如果需要则插入一个具有给定值的新条目。它返回对新值或现有值的可变引用。假设我们需要统计选票,我们可以这样写:
let mut vote_counts: HashMap<String, usize> = HashMap::new();
for name in ballots {
let count = vote_counts.entry(name).or_insert(0);
*count += 1;
}
2
3
4
5
.or_insert()返回一个可变引用,所以count的类型是&mut usize。
map.entry(key).or_default():确保映射包含具有给定键的条目,如果需要则插入一个值,该值由Default::default()返回。这只对实现了Default的类型有效。与or_insert类似,这个方法返回对新值或现有值的可变引用。map.entry(key).or_insert_with(default_fn):与or_default类似,只是如果需要创建新条目,它会调用default_fn()来生成默认值。如果映射中已经有给定键的条目,就不会使用default_fn。假设我们想知道哪些单词出现在哪些文件中,我们可以这样写:
// 这个映射包含每个单词以及它出现的文件集合。
let mut word_occurrence: HashMap<String, HashSet<String>> = HashMap::new();
for file in files {
for word in read_words(file)? {
let set = word_occurrence
.entry(word)
.or_insert_with(HashSet::new);
set.insert(file.clone());
}
}
2
3
4
5
6
7
8
9
10
Entry还提供了一种方便的方式,仅修改现有字段。
map.entry(key).and_modify(closure):如果存在具有给定键的条目,则调用闭包,并传入对值的可变引用。它返回Entry,因此可以与其他方法链式调用。例如,我们可以用这个方法统计字符串中单词的出现次数:
// 这个映射包含给定字符串中的所有单词,以及它们出现的次数。
let mut word_frequency: HashMap<&str, u32> = HashMap::new();
for c in text.split_whitespace() {
word_frequency.entry(c)
.and_modify(|count| *count += 1)
.or_insert(1);
}
2
3
4
5
6
7
Entry类型是一个枚举,HashMap的定义如下(BTreeMap类似):
// (在std::collections::hash_map中)
pub enum Entry<'a, K, V> {
Occupied(OccupiedEntry<'a, K, V>),
Vacant(VacantEntry<'a, K, V>)
}
2
3
4
5
OccupiedEntry和VacantEntry类型具有用于插入、删除和访问条目的方法,而无需重复初始查找。你可以在在线文档中找到它们。这些额外的方法偶尔可以用于消除一两个重复的查找,但.or_insert()和.or_insert_with()涵盖了常见的情况。
# 映射迭代
有几种迭代映射的方式:
- 按值迭代(
for (k, v) in map)生成(K, V)对。这会消耗映射。 - 对共享引用进行迭代(
for (k, v) in &map)生成(&K, &V)对。 - 对可变引用进行迭代(
for (k, v) in &mut map)生成(&K, &mut V)对。(同样,无法对存储在映射中的键进行可变访问,因为条目是根据键来组织的。)
与向量类似,映射有.iter()和.iter_mut()方法,它们返回按引用的迭代器,就像对&map或&mut map进行迭代一样。此外:
map.keys():返回一个仅对键进行引用的迭代器。map.values():返回一个对值进行引用的迭代器。map.values_mut():返回一个对值进行可变引用的迭代器。
所有HashMap迭代器以任意顺序访问映射的条目。BTreeMap迭代器按键的顺序访问它们。
# HashSet<T> 和 BTreeSet<T>
集合是为快速成员测试而组织的值的集合:
let b1 = large_vector.contains(&"needle"); // 慢,检查每个元素
let b2 = large_hash_set.contains(&"needle"); // 快,哈希查找
2
集合中永远不会包含同一个值的多个副本。
映射和集合有不同的方法,但在底层,集合就像是只有键而没有键值对的映射。实际上,Rust的两种集合类型HashSet<T>和BTreeSet<T>,是对HashMap<T, ()>和BTreeMap<T, ()>的简单包装。
HashSet::new()、BTreeSet::new():创建新的集合。iter.collect():可用于从任何迭代器创建新的集合。如果迭代器生成的任何值出现多次,重复的值将被丢弃。HashSet::with_capacity(n):创建一个空的HashSet,至少有容纳n个值的空间。
HashSet<T>和BTreeSet<T>有所有相同的基本方法:
set.len():返回集合中的值的数量。set.is_empty():如果集合不包含任何元素,则返回true。set.contains(&value):如果集合包含给定值,则返回true。set.insert(value):向集合中添加一个值。如果添加了一个值,则返回true;如果该值已经是集合的成员,则返回false。set.remove(&value):从集合中删除一个值。如果删除了一个值,则返回true;如果该值本来就不是集合的成员,则返回false。set.retain(test):删除所有未通过给定测试的元素。test参数是一个实现了FnMut(&T) -> bool的函数或闭包。对于集合中的每个元素,都会调用test(&value),如果返回false,则从集合中删除该元素并释放其内存。除了性能方面,这类似于编写:set = set.into_iter().filter(test).collect();
与映射一样,通过引用查找值的方法对于可以从T借用的类型是泛型的。详细信息,请参见 “Borrow and BorrowMut”(Borrow和BorrowMut)。
# 集合迭代
有两种迭代集合的方式:
- 按值迭代(
for v in set)生成集合的成员(并消耗集合)。 - 按共享引用迭代(
for v in &set)生成对集合成员的共享引用。
不支持按可变引用迭代集合。无法获取对存储在集合中的值的可变引用。
set.iter():返回一个对集合成员进行引用的迭代器。
HashSet迭代器与HashMap迭代器一样,以任意顺序生成它们的值。BTreeSet迭代器按顺序生成值,就像排序后的向量一样。
# 当相等的值有差异时
集合有一些特殊的方法,只有在你关心 “相等” 值之间的差异时才需要使用。
这样的差异确实经常存在。例如,两个相同的String值,它们的字符存储在内存中的不同位置:
let s1 = "hello".to_string();
let s2 = "hello".to_string();
println!("{:p}", &s1 as &str); // 0x7f8b32060008
println!("{:p}", &s2 as &str); // 0x7f8b32060010
2
3
4
通常,我们并不在意这些。
但如果你确实在意,可以使用以下方法访问存储在集合中的实际值。如果集合不包含匹配的值,每个方法都返回一个Option类型的值,且值为None:
set.get(&value):返回对集合中等于value的成员的共享引用(如果有的话)。返回Option<&T>。set.take(&value):与set.remove(&value)类似,但它返回被删除的值(如果有的话)。返回Option<T>。set.replace(value):与set.insert(value)类似,但如果集合中已经包含等于value的值,这个方法会替换并返回旧值。返回Option<T>。
# 集合的整体操作
到目前为止,我们看到的大多数集合方法都集中在单个集合中的单个值上。集合也有对整个集合进行操作的方法:
set1.intersection(&set2):返回一个迭代器,它会遍历同时存在于set1和set2中的所有值。例如,如果我们想打印所有既上脑外科手术课又上火箭科学课的学生的名字,我们可以这样写:
for student in &brain_class {
if rocket_class.contains(student) {
println!("{}", student);
}
}
2
3
4
5
或者,更简短的写法:
for student in brain_class.intersection(&rocket_class) {
println!("{}", student);
}
2
3
令人惊讶的是,有一个运算符也能实现这个功能。&set1 & &set2会返回一个新集合,它是set1和set2的交集。这是二进制按位与运算符,应用于两个引用。它会找出同时在set1和set2中的值:
let overachievers = &brain_class & &rocket_class;
set1.union(&set2):返回一个迭代器,它会遍历存在于set1或set2中,或者同时存在于两者中的值。&set1 | &set2会返回一个包含所有这些值的新集合。它会找出在set1或set2中的值。set1.difference(&set2):返回一个迭代器,它会遍历存在于set1但不存在于set2中的值。&set1 - &set2会返回一个包含所有这些值的新集合。set1.symmetric_difference(&set2):返回一个迭代器,它会遍历存在于set1或set2中,但不同时存在于两者中的值。&set1 ^ &set2会返回一个包含所有这些值的新集合。
还有三个用于测试集合之间关系的方法:
set1.is_disjoint(set2):如果set1和set2没有共同的值,即它们的交集为空,则返回true。set1.is_subset(set2):如果set1是set2的子集,即set1中的所有值也都在set2中,则返回true。set1.is_superset(set2):与is_subset相反,如果set1是set2的超集,则返回true。
集合也支持使用==和!=进行相等性测试;如果两个集合包含相同的值,则它们相等。
# 哈希
std::hash::Hash是标准库中用于可哈希类型的特性。HashMap的键和HashSet的元素必须同时实现Hash和Eq。
大多数实现了Eq的内置类型也实现了Hash。整数类型、char和String都是可哈希的;只要元组、数组、切片和向量的元素是可哈希的,它们也是可哈希的。
标准库的一个原则是,一个值无论存储在哪里或如何指向它,都应该具有相同的哈希码。因此,一个引用与其所引用的值具有相同的哈希码,一个Box与其装箱的值具有相同的哈希码。一个向量vec与包含其所有数据的切片&vec[..]具有相同的哈希码。一个String与具有相同字符的&str具有相同的哈希码。
结构体和枚举默认不实现Hash,但可以派生实现:
/// 大英博物馆藏品的编号。
#[derive(Clone, PartialEq, Eq, Hash)]
enum MuseumNumber {
...
}
2
3
4
5
只要类型的字段都是可哈希的,这样就能正常工作。
如果你手动为一个类型实现PartialEq,也应该手动实现Hash。例如,假设我们有一个表示无价历史珍宝的类型:
struct Artifact {
id: MuseumNumber,
name: String,
cultures: Vec<Culture>,
date: RoughTime,
...
}
2
3
4
5
6
7
如果两个Artifact具有相同的id,则认为它们相等:
impl PartialEq for Artifact {
fn eq(&self, other: &Artifact) -> bool {
self.id == other.id
}
}
impl Eq for Artifact {}
2
3
4
5
6
由于我们仅根据id来比较Artifact,所以必须以相同的方式对它们进行哈希:
use std::hash::{Hash, Hasher};
impl Hash for Artifact {
fn hash<H: Hasher>(&self, hasher: &mut H) {
// 将哈希委托给MuseumNumber。
self.id.hash(hasher);
}
}
2
3
4
5
6
7
8
(否则,HashSet<Artifact>将无法正常工作;与所有哈希表一样,它要求如果a == b,则hash(a) == hash(b)。)
这使我们能够创建一个Artifact的HashSet:
let mut collection = HashSet::<Artifact>::new();
如这段代码所示,即使你手动实现Hash,也不需要了解任何哈希算法的知识。.hash()接收一个指向Hasher的引用,Hasher代表哈希算法。你只需将与==运算符相关的所有数据提供给这个Hasher。Hasher会根据你提供的数据计算出一个哈希码。
# 使用自定义哈希算法
hash方法是泛型的,所以前面展示的Hash实现可以将数据提供给任何实现了Hasher的类型。这就是Rust支持可插拔哈希算法的方式。
第三个特性std::hash::BuildHasher,是用于表示哈希算法初始状态的类型的特性。每个Hasher都是一次性的,就像迭代器一样:你使用一次后就丢弃它。BuildHasher是可复用的。
每个HashMap都包含一个BuildHasher,每次需要计算哈希码时都会使用它。BuildHasher值包含哈希算法每次运行所需的键、初始状态或其他参数。
计算哈希码的完整流程如下:
use std::hash::{Hash, Hasher, BuildHasher};
fn compute_hash<B, T>(builder: &B, value: &T) -> u64
where
B: BuildHasher,
T: Hash
{
let mut hasher = builder.build_hasher(); // 1. 启动算法
value.hash(&mut hasher); // 2. 向其提供数据
hasher.finish() // 3. 完成计算,生成一个u64类型的值
}
2
3
4
5
6
7
8
9
10
11
HashMap每次需要计算哈希码时都会调用这三个方法。所有这些方法都是内联的,所以速度非常快。
Rust的默认哈希算法是一种名为SipHash - 1 - 3的知名算法。SipHash速度很快,并且在最小化哈希冲突方面表现出色。实际上,它是一种加密算法:目前还没有已知的有效方法来生成SipHash - 1 - 3冲突。只要为每个哈希表使用不同的、不可预测的键,Rust就可以抵御一种称为HashDoS的拒绝服务攻击,在这种攻击中,攻击者故意利用哈希冲突来触发服务器的最坏性能。
但也许你的应用程序不需要这样的安全性。如果你存储的是许多小键,比如整数或非常短的字符串,有可能实现一种更快的哈希函数,不过要以牺牲HashDoS安全性为代价。fnv库实现了一种这样的算法,即Fowler - Noll - Vo(FNV)哈希。要尝试使用它,在你的Cargo.toml文件中添加这一行:
[dependencies]
fnv = "1.0"
2
然后从fnv导入映射和集合类型:
use fnv::{FnvHashMap, FnvHashSet};
你可以用这两种类型直接替换HashMap和HashSet。查看fnv源代码可以发现它们的定义方式:
/// 使用默认FNV哈希器的`HashMap`。
pub type FnvHashMap<K, V> = HashMap<K, V, FnvBuildHasher>;
/// 使用默认FNV哈希器的`HashSet`。
pub type FnvHashSet<T> = HashSet<T, FnvBuildHasher>;
2
3
4
标准的HashMap和HashSet集合接受一个可选的额外类型参数,用于指定哈希算法;FnvHashMap和FnvHashSet是HashMap和HashSet的泛型类型别名,为该参数指定了FNV哈希器。
# 标准集合之外
在Rust中创建一个新的自定义集合类型与在其他语言中大致相同。你通过组合语言提供的部分来组织数据:结构体、枚举、标准集合、Option、Box等等。例如,参见 “Generic Enums”(泛型枚举)中定义的BinaryTree<T>类型。
如果你习惯在C++中使用原始指针、手动内存管理、定位新对象和显式调用析构函数来实现数据结构以获得最佳性能,你无疑会觉得安全的Rust相当受限。所有这些工具本质上都是不安全的。在Rust中它们是可用的,但只有在你选择使用不安全代码时才行。第22章展示了如何使用;其中包括一个使用一些不安全代码来实现一个安全的自定义集合的示例。
目前,我们只需享受标准集合及其安全、高效的API带来的便利。与Rust标准库的许多部分一样,它们的设计目的是尽可能减少编写不安全代码的需求。