 第17章 字符串和文本
第17章 字符串和文本
# 第17章 字符串和文本
字符串是一种简单的数据结构,无论它传递到哪里,都伴随着大量重复的处理过程。它是隐藏信息的绝佳载体。
——艾伦·佩利斯,警句#34
在本书中,我们一直在使用Rust的主要文本类型:String、str和char。在 “字符串类型” 中,我们描述了字符和字符串字面值的语法,并展示了字符串在内存中的表示方式。在本章中,我们将更详细地介绍文本处理。
在本章中:
- 我们会介绍一些Unicode的背景知识,这有助于你理解标准库的设计。
- 我们将描述
char类型,它表示单个Unicode码点。 - 我们将描述
String和str类型,它们分别表示拥有所有权和借用的Unicode字符序列。这些类型具有各种各样的方法,用于构建、搜索、修改和迭代其内容。 - 我们将介绍Rust的字符串格式化功能,例如
println!和format!宏。你可以编写自己的宏来处理格式化字符串,并扩展它们以支持自己的类型。 - 我们将概述Rust对正则表达式的支持。
- 最后,我们将讨论Unicode规范化的重要性,并展示如何在Rust中进行规范化。
# 一些Unicode背景知识
本书是关于Rust的,而不是关于Unicode的,已经有专门的书籍来介绍Unicode。但是Rust的字符和字符串类型是围绕Unicode设计的。以下是一些有助于理解Rust的Unicode知识。
# ASCII、Latin-1和Unicode
Unicode和ASCII在ASCII的所有码点(从0到0x7f)上是匹配的:例如,两者都将字符*的码点指定为42。类似地,Unicode将0到0xff的码点分配给与ISO/IEC 8859 - 1字符集相同的字符,ISO/IEC 8859 - 1是ASCII的一个八位超集,用于西欧语言。Unicode将这个码点范围称为Latin - 1码块,所以我们将使用更形象的名称Latin - 1来指代ISO/IEC 8859 - 1。
由于Unicode是Latin - 1的超集,将Latin - 1转换为Unicode甚至不需要查找表:
fn latin1_to_char(latin1: u8) -> char {
latin1 as char
}
2
3
假设码点在Latin - 1范围内,反向转换也很简单:
fn char_to_latin1(c: char) -> Option<u8> {
if c as u32 <= 0xff {
Some(c as u8)
} else {
None
}
}
2
3
4
5
6
7
# UTF-8
Rust的String和str类型使用UTF - 8编码形式来表示文本。UTF - 8将一个字符编码为1到4个字节的序列(图17-1)。
 图17-1. UTF-8编码
图17-1. UTF-8编码
格式良好的UTF - 8序列有两个限制。第一,对于任何给定的码点,只有最短的编码才被认为是格式良好的;你不能用4个字节来编码一个用3个字节就能表示的码点。这条规则确保了对于给定的码点只有一种UTF - 8编码。第二,格式良好的UTF - 8不能对0xd800到0xdfff或超过0x10ffff的数字进行编码:这些要么是为非字符目的保留的,要么完全超出了Unicode的范围。
图17-2展示了一些示例。
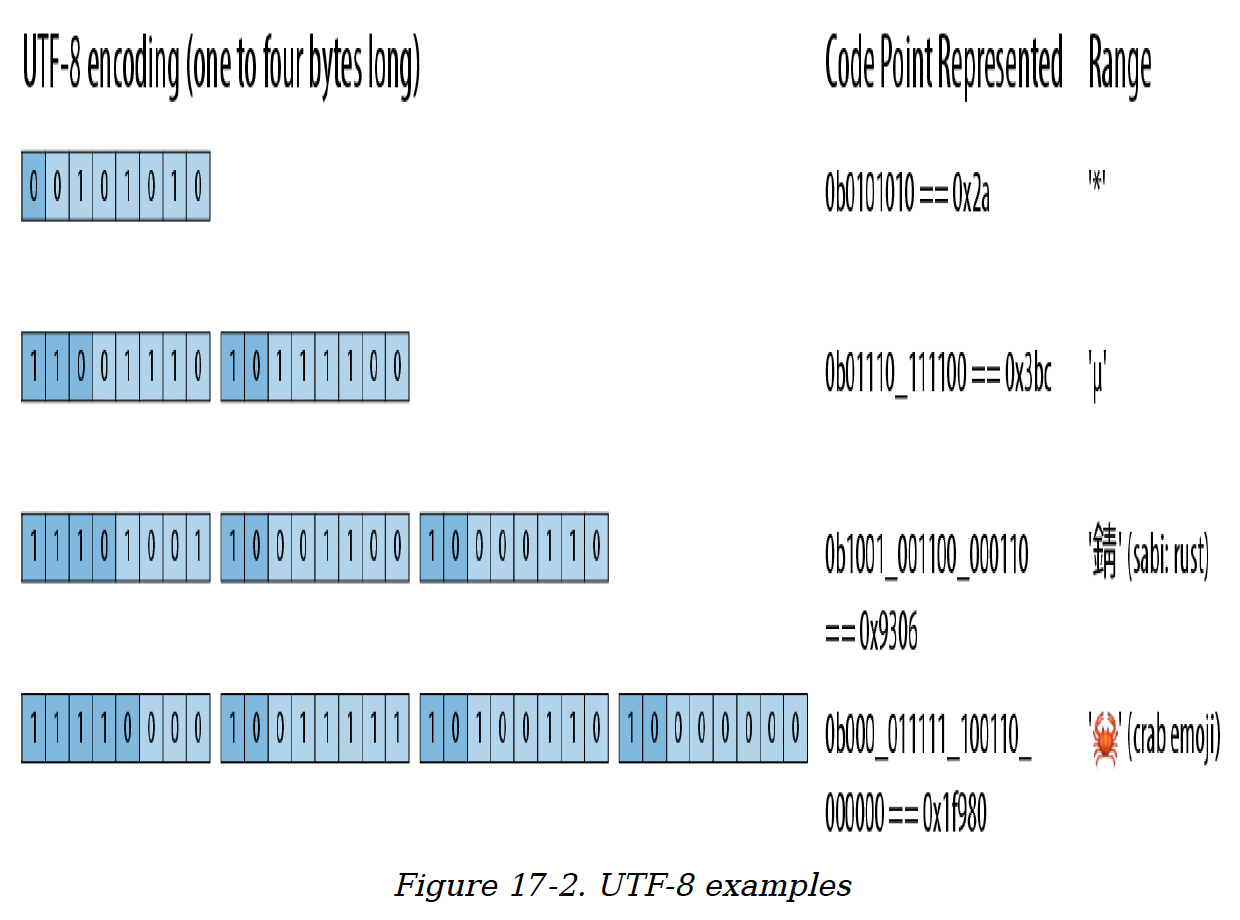 图17-2. UTF-8示例
图17-2. UTF-8示例
注意,即使螃蟹表情符号的编码中,其首字节对码点只贡献了零,但它仍然需要一个4字节的编码:3字节的UTF - 8编码只能表示16位的码点,而0x1f980是17位长。
下面是一个包含不同长度编码字符的字符串示例:
assert_eq!("うどん : udon".as_bytes(), &[
0xe3, 0x81, 0x86, // う
0xe3, 0x81, 0xa9, // ど
0xe3, 0x82, 0x93, // ん
0x3a, 0x20, 0x75, 0x64, 0x6f, 0x6e // : udon
]);
2
3
4
5
6
图17-2还展示了UTF - 8的一些非常有用的特性:
- 由于UTF - 8将0到0x7f的码点编码为0到0x7f的字节,所以包含ASCII文本的字节范围是有效的UTF - 8。并且,如果一个UTF - 8字符串只包含ASCII字符,反之亦然:其UTF - 8编码是有效的ASCII。但Latin - 1并非如此:例如,Latin - 1将
é编码为字节0xe9,而UTF - 8会将其解释为一个3字节编码的首字节。 - 从任何一个字节的高位比特,你可以立即判断它是某个字符的UTF - 8编码的开始,还是编码中间的一个字节。
- 仅通过编码的首字节的前导比特,你就能知道整个编码的长度。
- 由于没有编码超过4字节,处理UTF - 8时永远不需要无边界的循环,在处理不可信数据时这很有用。
- 在格式良好的UTF - 8中,即使从字节中间的任意位置开始,你也总能明确地判断字符编码的起止位置。UTF - 8的首字节和后续字节总是不同的,所以一个编码不可能在另一个编码的中间开始。首字节决定了编码的总长度,所以一个编码不可能是另一个编码的前缀。这有很多好处。例如,在UTF - 8字符串中搜索ASCII分隔符字符,只需要简单地扫描分隔符的字节即可。它永远不会作为多字节编码的一部分出现,所以根本不需要跟踪UTF - 8的结构。同样,在一个字符串中搜索另一个字节串的算法,即使有些算法甚至不会检查被搜索文本的每个字节,也可以直接用于UTF - 8字符串,无需修改。
虽然可变宽度编码比固定宽度编码更复杂,但这些特性使UTF - 8比你想象的更容易使用。标准库会为你处理大部分相关操作。
# 文本方向
像拉丁字母、西里尔字母和泰语这样的文字是从左到右书写的,而像希伯来语和阿拉伯语这样的文字则是从右到左书写的。Unicode按照字符正常书写或阅读的顺序存储字符,所以包含希伯来语文本的字符串的起始字节,编码的是正常书写时最右边的字符:
assert_eq!("טוב ערב ".chars().next(), Some('ע'));
# 字符(char)
Rust中的char是一个32位的值,用于存储一个Unicode码点。char的值被保证在0到0xd7ff或0xe000到0x10ffff的范围内;所有创建和操作char值的方法都确保这一点。char类型实现了Copy和Clone,以及所有常见的比较、哈希和格式化特性。
字符串切片可以使用slice.chars()生成一个字符迭代器:
assert_eq!("カニ ".chars().next(), Some('カ'));
在接下来的描述中,变量ch的类型始终是char。
# 字符分类
char类型有一些方法,用于将字符分类为几个常见的类别,如表17-1所示。这些分类定义均来自Unicode。
表17-1. char类型的分类方法
| 方法 | 描述 | 示例 |
|---|---|---|
ch.is_numeric() | 一个数字字符。这包括Unicode通用类别中的“数字;数字”和“数字;字母”,但不包括“数字;其他” | '4'.is_numeric()'O'.is_numeric()'⑧'.is_numeric() |
ch.is_alphabetic() | 一个字母字符:Unicode的“字母”派生属性 | 'q'.is_alphabetic()'七'.is_alphabetic() |
ch.is_alphanumeric() | 如前所述,要么是数字,要么是字母 | '9'.is_alphanumeric()'醞'.is_alphanumeric()!'*'.is_alphanumeric() |
ch.is_whitespace() | 一个空白字符:Unicode字符属性“WSpace=Y” | '\n'.is_whitespace()'\u{A0}'.is_whitespace()' '.is_whitespace() |
ch.is_control() | 一个控制字符:Unicode的“其他,控制”通用类别 | '\n'.is_control()'\u{85}'.is_control() |
还有一组并行的方法,仅适用于ASCII字符,对于任何非ASCII字符返回false(表17-2)。
表17-2. char类型的ASCII分类方法
| 方法 | 描述 | 示例 |
|---|---|---|
ch.is_ascii() | 一个ASCII字符:码点在0到127(含)之间的字符 | 'n'.is_ascii()!'ñ'.is_ascii() |
ch.is_ascii_alphabetic() | 一个ASCII大写或小写字母,范围是'A'..='Z'或'a'..='z' | 'n'.is_ascii_alphabetic()!'1'.is_ascii_alphabetic()!'ñ'.is_ascii_alphabetic() |
ch.is_ascii_digit() | 一个ASCII数字,范围是'0'..='9' | '8'.is_ascii_digit()!'-'.is_ascii_digit()!'⑧'.is_ascii_digit() |
ch.is_ascii_hexdigit() | 范围在'0'..='9'、'A'..='F'或'a'..='f'内的任何字符 | - |
ch.is_ascii_alphanumeric() | 一个ASCII数字或ASCII大写或小写字母 | 'q'.is_ascii_alphanumeric()'0'.is_ascii_alphanumeric() |
ch.is_ascii_control() | 一个ASCII控制字符,包括DEL | '\n'.is_ascii_control()'\x7f'.is_ascii_control() |
ch.is_ascii_graphic() | 任何能在页面上留下痕迹的ASCII字符:既不是空格也不是控制字符 | 'Q'.is_ascii_graphic()'~'.is_ascii_graphic()!' '.is_ascii_graphic() |
ch.is_ascii_uppercase()ch.is_ascii_lowercase() | ASCII大写和小写字母 | 'z'.is_ascii_lowercase()'Z'.is_ascii_uppercase() |
ch.is_ascii_punctuation() | 任何既不是字母也不是数字的ASCII图形字符 | - |
ch.is_ascii_whitespace() | 一个ASCII空白字符:空格、水平制表符、换行符、换页符或回车符 | ' '.is_ascii_whitespace()'\n'.is_ascii_whitespace()!'\u{A0}'.is_ascii_whitespace() |
所有is_ascii_...方法在u8字节类型上也可用:
assert!(32u8.is_ascii_whitespace());
assert!(b'9'.is_ascii_digit());
2
在使用这些函数实现现有规范(如编程语言标准或文件格式)时要小心,因为不同规范的分类方式可能会有惊人的差异。例如,注意is_whitespace和is_ascii_whitespace在处理某些字符时有所不同:
let line_tab = '\u{000b}'; // 'line tab',也称为'vertical tab'
assert_eq!(line_tab.is_whitespace(), true);
assert_eq!(line_tab.is_ascii_whitespace(), false);
2
3
char::is_ascii_whitespace函数实现了许多网络标准中常见的空白字符定义,而char::is_whitespace遵循Unicode标准。
# 处理数字
处理数字时,你可以使用以下方法:
ch.to_digit(radix):判断ch是否是radix进制的数字。如果是,返回Some(num),其中num是一个u32类型的值。否则,返回None。这个方法只识别ASCII数字,不包括char::is_numeric涵盖的更广泛的字符类别。radix参数的取值范围是2到36。对于大于10的进制,ASCII字母(无论大小写)都被视为值为10到35的数字。std::char::from_digit(num, radix):这是一个自由函数,如果可能的话,它将u32类型的数字值num转换为char。如果num可以用radix进制表示为单个数字,from_digit返回Some(ch),其中ch就是这个数字。当radix大于10时,ch可能是小写字母。否则,返回None。这是to_digit的反向操作。如果std::char::from_digit(num, radix)返回Some(ch),那么ch.to_digit(radix)就返回Some(num)。如果ch是ASCII数字或小写字母,反之亦然。ch.is_digit(radix):如果ch是radix进制的ASCII数字,返回true。这等同于ch.to_digit(radix) != None。例如:
assert_eq!('F'.to_digit(16), Some(15));
assert_eq!(std::char::from_digit(15, 16), Some('f'));
assert!(char::is_digit('f', 16));
2
3
# 字符大小写转换
处理字符大小写时:
ch.is_lowercase()、ch.is_uppercase():判断ch是小写还是大写字母字符。这些方法遵循Unicode的“小写”和“大写”派生属性,因此它们涵盖了像希腊字母和西里尔字母这样的非拉丁字母,并且对ASCII字符也能给出预期的结果。ch.to_lowercase()、ch.to_uppercase():根据Unicode默认的大小写转换算法,返回生成ch的小写或大写等效字符的迭代器:
let mut upper = 's'.to_uppercase();
assert_eq!(upper.next(), Some('S'));
assert_eq!(upper.next(), None);
2
3
这些方法返回迭代器而不是单个字符,因为Unicode中的大小写转换并不总是一对一的过程:
// 德语字母“sharp S”的大写形式是“SS”:
let mut upper = 'ß'.to_uppercase();
assert_eq!(upper.next(), Some('S'));
assert_eq!(upper.next(), Some('S'));
assert_eq!(upper.next(), None);
// Unicode规定将带点的土耳其大写字母“İ”小写为“i”,后面跟着`'\u{307}'`(COMBINING DOT ABOVE),以便后续再转换为大写时能保留这个点。
let ch = 'İ'; // `'\u{130}'`
let mut lower = ch.to_lowercase();
assert_eq!(lower.next(), Some('i'));
assert_eq!(lower.next(), Some('\u{307}'));
assert_eq!(lower.next(), None);
2
3
4
5
6
7
8
9
10
11
12
为了方便使用,这些迭代器实现了std::fmt::Display特性,所以你可以直接将它们传递给println!或write!宏。
# 与整数的相互转换
Rust的as运算符可以将char转换为任何整数类型,会自动屏蔽高位比特位:
assert_eq!('B' as u32, 66);
assert_eq!('饂' as u8, 66); // 高位比特被截断
assert_eq!('二' as i8, -116); // 同理
2
3
as运算符可以将任何u8值转换为char,并且char也实现了From<u8>。但是更宽的整数类型可能表示无效的码点,所以对于这些类型,你必须使用std::char::from_u32,它返回Option<char>:
assert_eq!(char::from(66), 'B');
assert_eq!(std::char::from_u32(0x9942), Some('饂'));
assert_eq!(std::char::from_u32(0xd800), None); // 为UTF - 16保留
2
3
# String 和 str
Rust的String和str类型保证只包含格式良好的UTF - 8编码。标准库通过限制创建String和str值的方式以及对它们执行的操作,确保在引入这些值时它们的格式是良好的,并且在后续操作中保持良好格式。它们所有的方法都维护这一保证:对它们进行的任何安全操作都不会引入格式错误的UTF - 8。这简化了处理文本的代码。
Rust根据方法是否需要可调整大小的缓冲区,或者是否仅对文本进行原地操作,将文本处理方法放在str或String类型上。由于String可以解引用为&str,所以在str上定义的每个方法也可以直接在String上使用。本节将根据大致功能对这两种类型的方法进行分组介绍。
这些方法通过字节偏移量对文本进行索引,并以字节为单位测量文本长度,而不是以字符为单位。实际上,考虑到Unicode的特性,按字符索引并不像看起来那么有用,而字节偏移量更快且更简单。如果你尝试使用落在某个字符的UTF - 8编码中间的字节偏移量,方法会引发恐慌(panic),所以你不会以这种方式引入格式错误的UTF - 8。
String被实现为对Vec<u8>的包装,以确保向量的内容始终是格式良好的UTF - 8。Rust永远不会更改String的表示形式使其变得更复杂,所以你可以认为String具有与Vec相同的性能特征。
在以下解释中,变量的类型如表17-3所示。 表17-3. 解释中使用的变量类型
| 变量 | 假定类型 |
|---|---|
string | String |
slice | &str 或可解引用为 &str 的类型,如 String 或 Rc<String> |
ch | char |
n | usize,表示长度 |
i, j | usize,表示字节偏移量 |
range | usize 类型字节偏移量的范围,既可以是完全限定的,如 i..j,也可以是部分限定的,如 i..、..j 或 .. |
pattern | 任意模式类型:char、String、&str、&[char] 或 FnMut(char) -> bool |
我们将在 “搜索文本的模式” 中描述模式类型。
# 创建String值
创建String值有几种常见的方法:
String::new():返回一个全新的空字符串。它没有在堆上分配缓冲区,但会根据需要进行分配。String::with_capacity(n):返回一个全新的空字符串,并预先分配一个至少能容纳n字节的缓冲区。如果你事先知道要构建的字符串的长度,这个构造函数可以让你从一开始就正确设置缓冲区的大小,而不是在构建字符串的过程中调整缓冲区大小。如果字符串的长度超过n字节,它仍然会根据需要扩展缓冲区。与向量类似,字符串也有capacity、reserve和shrink_to_fit方法,但通常默认的分配逻辑就足够了。str_slice.to_string():分配一个新的String,其内容是str_slice的副本。在本书中,我们一直在使用类似"literal text".to_string()这样的表达式,从字符串字面量创建String。iter.collect():通过连接迭代器中的项来构造一个字符串,这些项可以是char、&str或String类型的值。例如,要从字符串中删除所有空格,可以这样写:
let spacey = "man hat tan";
let spaceless: String = spacey.chars().filter(|c|!c.is_whitespace()).collect();
assert_eq!(spaceless, "manhattan");
2
3
以这种方式使用collect,利用了String对std::iter::FromIterator特性的实现。
slice.to_owned():返回slice的副本,作为新分配的String。str类型不能实现Clone特性,因为该特性要求对&str调用clone时返回str值,但str是未 Sized 类型。然而,&str实现了ToOwned,这使得实现者可以指定其拥有所有权的等效类型。
# 简单检查
这些方法用于从字符串切片中获取基本信息:
slice.len():返回slice的长度,以字节为单位。slice.is_empty():如果slice.len() == 0,返回true。slice[range]:返回借用slice给定部分的切片。部分限定和不限定范围都是允许的;例如:
let full = "bookkeeping";
assert_eq!(&full[..4], "book");
assert_eq!(&full[5..], "eeping");
assert_eq!(&full[2..4], "ok");
assert_eq!(full[..].len(), 11);
assert_eq!(full[5..].contains("boo"), false);
2
3
4
5
6
注意,你不能像slice[i]这样用单个位置对字符串切片进行索引。在给定的字节偏移量处获取单个字符有点麻烦:你必须在切片上生成一个chars迭代器,并让它解析一个字符的UTF - 8编码:
let parenthesized = "Rust (醞)";
assert_eq!(parenthesized[6..].chars().next(), Some('醞'));
2
不过,你很少需要这样做。Rust有更好的方法来迭代切片,我们将在 “迭代文本” 中介绍。
slice.split_at(i):返回一个由两个共享切片组成的元组,这两个切片均从slice借用:一个是到字节偏移量i之前的部分,另一个是i之后的部分。换句话说,它返回(slice[..i], slice[i..])。slice.is_char_boundary(i):如果字节偏移量i落在字符边界之间,因此适合作为slice的偏移量,则返回true。
自然地,切片可以进行相等性比较、排序和哈希操作。排序比较只是将字符串视为Unicode码点的序列,并按字典顺序进行比较。
# 追加和插入文本
以下方法用于向String中添加文本:
string.push(ch):将字符ch追加到string的末尾。string.push_str(slice):将slice的全部内容追加到string。string.extend(iter):将迭代器iter生成的项追加到string。迭代器可以生成char、str或String类型的值。这些是String对std::iter::Extend特性的实现:
let mut also_spaceless = "con".to_string();
also_spaceless.extend("tri but ion".split_whitespace());
assert_eq!(also_spaceless, "contribution");
2
3
string.insert(i, ch):在string的字节偏移量i处插入单个字符ch。这需要将i之后的所有字符向后移动,为ch腾出空间,所以用这种方式构建字符串的时间复杂度可能与字符串长度的平方成正比。string.insert_str(i, slice):对slice执行相同的操作,同样存在性能方面的问题。
String实现了std::fmt::Write,这意味着write!和writeln!宏可以将格式化的文本追加到String中:
use std::fmt::Write;
let mut letter = String::new();
writeln!(letter, "Whose {} these are I think I know", "rutabagas")?;
writeln!(letter, "His house is in the village though;")?;
assert_eq!(letter, "Whose rutabagas these are I think I know\nHis house is in the village though;\n");
2
3
4
5
6
由于write!和writeln!是为写入输出流而设计的,它们会返回一个Result,如果忽略这个结果,Rust会报错。这段代码使用?操作符来处理它,但实际上写入String是不会出错的,所以在这种情况下调用.unwrap()也可以。
由于String实现了Add<&str>和AddAssign<&str>,你可以编写如下代码:
let left = "partners".to_string();
let mut right = "crime".to_string();
assert_eq!(left + " in " + &right, "partners in crime");
right += " doesn't pay";
assert_eq!(right, "crime doesn't pay");
2
3
4
5
当应用于字符串时,+操作符按值获取其左操作数,所以它实际上可以将该String重用作加法的结果。因此,如果左操作数的缓冲区足够大,能够容纳结果,就不需要进行分配。
不太对称的是,+的左操作数不能是&str,所以你不能这样写:
let parenthetical = "(" + string + ")";
你必须这样写:
let parenthetical = "(".to_string() + &string + ")";
然而,这个限制确实不鼓励从后向前构建字符串。这种方法性能较差,因为文本必须不断地向缓冲区末尾移动。
不过,通过从前向后追加小片段来构建字符串是高效的。String的行为与向量类似,当需要更多容量时,其缓冲区大小总是至少翻倍。这使得重新复制的开销与最终大小成比例。即便如此,使用String::with_capacity从一开始就创建具有合适缓冲区大小的字符串,可以完全避免调整大小,并且可以减少对堆分配器的调用次数。
# 删除和替换文本
String有一些用于删除文本的方法(这些方法不会影响字符串的容量;如果你需要释放内存,可以使用shrink_to_fit):
string.clear():将string重置为空字符串。string.truncate(n):丢弃字节偏移量n之后的所有字符,使string的长度最多为n。如果string的长度小于n字节,则此操作无效。string.pop():如果string有最后一个字符,则将其删除并作为Option<char>返回。string.remove(i):从string中删除字节偏移量i处的字符并返回它,将后面的字符向前移动。这一步的时间复杂度与后面字符的数量成线性关系。string.drain(range):返回给定字节索引范围的迭代器,当迭代器被丢弃时,会删除这些字符。范围之后的字符会向前移动:
let mut choco = "chocolate".to_string();
assert_eq!(choco.drain(3..6).collect::<String>(), "col");
assert_eq!(choco, "choate");
2
3
如果你只想删除该范围,可以立即丢弃迭代器,而无需从中提取任何项:
let mut winston = "Churchill".to_string();
winston.drain(2..6);
assert_eq!(winston, "Chill");
2
3
string.replace_range(range, replacement):用给定的替换字符串切片替换string中的给定范围。切片的长度不一定与被替换的范围相同,但除非被替换的范围一直到string的末尾,否则这将需要移动该范围之后的所有字节:
let mut beverage = "a piña colada".to_string();
beverage.replace_range(2..7, "kahlua"); // 'ñ' 占两个字节!
assert_eq!(beverage, "a kahlua colada");
2
3
# 搜索和迭代的约定
Rust标准库中用于搜索文本和迭代文本的函数遵循一些命名约定,以便于记忆:
- r:大多数操作从文本的开头到结尾进行处理,但名称以
r开头的操作则从结尾到开头处理。例如,rsplit是split从后向前处理的版本。在某些情况下,改变方向不仅会影响生成值的顺序,还会影响值本身。图17-3中的示例展示了这种情况。 - n:名称以
n结尾的迭代器将自身限制为给定数量的匹配项。 - _indices:名称以
_indices结尾的迭代器,除了生成正常的迭代值外,还会生成它们在切片中出现的字节偏移量。
标准库并没有为每个操作提供所有可能的组合。例如,许多操作不需要n变体,因为提前结束迭代就足够简单了。
# 搜索文本的模式
当标准库函数需要搜索、匹配、拆分或修剪文本时,它接受几种不同的类型来表示要查找的内容:
let haystack = "One fine day, in the middle of the night";
assert_eq!(haystack.find(','), Some(12));
assert_eq!(haystack.find("night"), Some(35));
assert_eq!(haystack.find(char::is_whitespace), Some(3));
2
3
4
这些类型被称为模式,大多数操作都支持它们:
assert_eq!("## Elephants"
.trim_start_matches(|ch: char| ch == '#' || ch.is_whitespace()),
"Elephants");
2
3
标准库支持四种主要的模式类型:
- 一个
char类型的模式匹配该字符。 - 一个
String、&str或&&str类型的模式匹配与该模式相等的子字符串。 - 一个
FnMut(char) -> bool类型的闭包作为模式,匹配闭包返回true的单个字符。 - 一个
&[char]类型的模式(不是&str,而是char值的切片)匹配列表中出现的任何单个字符。请注意,如果你将列表写为数组字面量,可能需要调用as_ref()来确保类型正确:
let code = "\t function noodle() { ";
assert_eq!(code.trim_start_matches([' ', '\t'].as_ref()), "function noodle() { ");
// 更简短的等效写法:&[' ', '\t'][..]
2
3
否则,Rust会对固定大小的数组类型&[char; 2]感到困惑,遗憾的是它不是一种模式类型。
在标准库自身的代码中,模式是任何实现了std::str::Pattern特性的类型。Pattern的细节目前还不稳定,所以在稳定版的Rust中,你不能为自己的类型实现它,但这为将来支持正则表达式和其他复杂模式打开了大门。Rust保证现在支持的模式类型在未来仍然可用。
# 搜索和替换
Rust有一些方法用于在切片中搜索模式,并可能用新文本替换它们:
slice.contains(pattern):如果slice中包含与pattern匹配的内容,则返回true。slice.starts_with(pattern)、slice.ends_with(pattern):如果slice的起始或结尾文本与pattern匹配,则返回true:
assert!("2017".starts_with(char::is_numeric));
slice.find(pattern)、slice.rfind(pattern):如果slice中包含与pattern匹配的内容,则返回Some(i),其中i是模式出现的字节偏移量。find方法返回第一个匹配项,rfind返回最后一个:
let quip = "We also know there are known unknowns";
assert_eq!(quip.find("know"), Some(8));
assert_eq!(quip.rfind("know"), Some(31));
assert_eq!(quip.find("ya know"), None);
assert_eq!(quip.rfind(char::is_uppercase), Some(0));
2
3
4
5
slice.replace(pattern, replacement):返回一个新的String,通过立即用replacement替换pattern的所有匹配项来形成:
assert_eq!("The only thing we have to fear is fear itself"
.replace("fear", "spin"),
"The only thing we have to spin is spin itself");
assert_eq!("`Borrow` and `BorrowMut`"
.replace(|ch: char|!ch.is_alphanumeric(), ""),
"BorrowandBorrowMut");
2
3
4
5
6
由于替换是立即进行的,.replace()在处理重叠匹配时的行为可能会让人意外。这里有四个"aba"模式的实例,但在替换了第一个和第三个之后,第二个和第四个就不再匹配了:
assert_eq!("cabababababbage"
.replace("aba", "***"),
"c***b***babbage")
2
3
slice.replacen(pattern, replacement, n):与replace方法类似,但最多只替换前n个匹配项。
# 迭代文本
标准库提供了几种迭代切片文本的方式。图17-3展示了一些示例。
你可以将split和match系列方法视为彼此的补充:split得到的是匹配项之间的范围。
 图17-3. 迭代切片的一些方式
图17-3. 迭代切片的一些方式
这些方法中的大多数返回的迭代器是可反转的(也就是说,它们实现了DoubleEndedIterator):调用它们的.rev()适配器方法,你会得到一个生成相同项但顺序相反的迭代器。
slice.chars():返回一个迭代器,用于遍历slice中的字符。slice.char_indices():返回一个迭代器,遍历slice中的字符及其字节偏移量:
assert_eq!("élan".char_indices().collect::<Vec<_>>(),
vec![(0, 'é'), // 有一个两字节的UTF - 8编码
(2, 'l'),
(3, 'a'),
(4, 'n')]);
2
3
4
5
注意,这与.chars().enumerate()并不等效,因为它提供的是每个字符在切片中的字节偏移量,而不仅仅是对字符进行编号。
slice.bytes():返回一个迭代器,遍历slice中的单个字节,展示UTF - 8编码:
assert_eq!("élan".bytes().collect::<Vec<_>>(),
vec![195, 169, b'l', b'a', b'n']);
2
slice.lines():返回一个迭代器,遍历slice中的行。行以"\n"或"\r\n"结尾。生成的每个项都是从slice借用的&str。这些项不包括行的终止字符。slice.split(pattern):返回一个迭代器,遍历slice中由pattern匹配项分隔的部分。在紧邻的匹配项之间,以及切片开头和结尾的匹配项处,会生成空字符串。如果pattern是&str类型,返回的迭代器是不可反转的。这种模式根据扫描方向的不同,可能会产生不同的匹配序列,而可反转迭代器不允许这样做。相反,你可以使用接下来要介绍的rsplit方法。slice.rsplit(pattern):此方法与split类似,但从slice的末尾开始扫描,按此顺序生成匹配项。slice.split_terminator(pattern)、slice.rsplit_terminator(pattern):这两个方法与split和rsplit类似,不同之处在于pattern被视为终止符,而不是分隔符:如果pattern在slice的末尾匹配,迭代器不会像split和rsplit那样生成一个表示该匹配项与切片末尾之间空字符串的空切片。例如:
// 这里的':'字符是分隔符。注意最后的""。
assert_eq!("jimb:1000:Jim Blandy:".split(':').collect::<Vec<_>>(),
vec!["jimb", "1000", "Jim Blandy", ""]);
// 这里的'\n'字符是终止符。
assert_eq!("127.0.0.1 localhost\n127.0.0.1 www.reddit.com\n"
.split_terminator('\n').collect::<Vec<_>>(),
vec!["127.0.0.1 localhost", "127.0.0.1 www.reddit.com"]);
// 注意,没有最后的""!
2
3
4
5
6
7
8
slice.splitn(n, pattern)、slice.rsplitn(n, pattern):这两个方法与split和rsplit类似,只是它们将字符串最多分割成n个切片,在pattern的前n - 1个或后n - 1个匹配项处进行分割。slice.split_whitespace()、slice.split_ascii_whitespace():返回一个迭代器,遍历slice中由空白字符分隔的部分。多个连续的空白字符被视为单个分隔符。尾随的空白字符将被忽略。split_whitespace方法使用char类型的is_whitespace方法实现的Unicode空白字符定义。split_ascii_whitespace方法则使用char::is_ascii_whitespace,它只识别ASCII空白字符。
let poem = "This is just to say\nI have eaten\n the plums\nagain\n ";
assert_eq!(poem.split_whitespace().collect::<Vec<_>>(),
vec!["This", "is", "just", "to", "say", "I", "have", "eaten", "the", "plums", "again"]);
2
3
slice.matches(pattern):返回一个迭代器,遍历slice中与pattern匹配的内容。slice.rmatches(pattern)与之相同,但从末尾开始迭代。slice.match_indices(pattern)、slice.rmatch_indices(pattern):这两个方法与matches类似,不同之处在于生成的项是(offset, match)对,其中offset是匹配开始的字节偏移量,match是匹配的切片。
# 修剪
修剪字符串指的是从字符串的开头或结尾删除文本,通常删除的是空白字符。在清理从文件中读取的输入时,这个操作很有用,因为用户可能为了便于阅读而缩进了文本,或者不小心在一行的末尾留下了尾随的空白字符。
slice.trim():返回slice的一个子切片,该子切片会省略所有前导和尾随的空白字符。slice.trim_start()仅省略前导空白字符,slice.trim_end()仅省略尾随空白字符:
assert_eq!("\t* .rs ".trim(), "* .rs");
assert_eq!("\t* .rs ".trim_start(), "* .rs ");
assert_eq!("\t* .rs ".trim_end(), "\t* .rs");
2
3
slice.trim_matches(pattern):返回slice的一个子切片,该子切片会省略开头和结尾所有与pattern匹配的内容。trim_start_matches和trim_end_matches方法分别仅对前导或尾随的匹配项执行相同操作:
assert_eq!("001990".trim_start_matches('0'), "1990");
# 字符串的大小写转换
slice.to_uppercase()和slice.to_lowercase()方法会返回一个新分配的字符串,其中包含slice转换为大写或小写后的文本。结果的长度可能与slice不同;详细信息请参见 “字符的大小写转换”。
# 从字符串解析其他类型
Rust为从字符串解析值以及生成值的文本表示提供了标准特性。
如果一个类型实现了std::str::FromStr特性,那么它就提供了一种从字符串切片解析值的标准方式:
pub trait FromStr: Sized {
type Err;
fn from_str(s: &str) -> Result<Self, Self::Err>;
}
2
3
4
所有常见的基本类型都实现了FromStr:
use std::str::FromStr;
assert_eq!(usize::from_str("3628800"), Ok(3628800));
assert_eq!(f64::from_str("128.5625"), Ok(128.5625));
assert_eq!(bool::from_str("true"), Ok(true));
assert!(f64::from_str("not a float at all").is_err());
assert!(bool::from_str("TRUE").is_err());
2
3
4
5
6
char类型也为只有一个字符的字符串实现了FromStr:
assert_eq!(char::from_str("é"), Ok('é'));
assert!(char::from_str("abcdefg").is_err());
2
std::net::IpAddr类型,一个表示IPv4或IPv6互联网地址的枚举,也实现了FromStr:
use std::net::IpAddr;
let address =
IpAddr::from_str("fe80::0000:3ea9:f4ff:fe34:7a50")?;
assert_eq!(address,
IpAddr::from([0xfe80, 0, 0, 0, 0x3ea9, 0xf4ff, 0xfe34, 0x7a50]));
2
3
4
5
字符串切片有一个parse方法,它可以将切片解析为你想要的任何类型,前提是该类型实现了FromStr。与Iterator::collect类似,有时你需要明确指定想要的类型,所以parse并不总是比直接调用from_str更易读:
let address = "fe80::0000:3ea9:f4ff:fe34:7a50".parse::<IpAddr>()?;
# 将其他类型转换为字符串
将非文本值转换为字符串主要有三种方式:
- 具有自然的人类可读打印形式的类型可以实现
std::fmt::Display特性,这使你能够在format!宏中使用{}格式说明符:
assert_eq!(format!("{}, wow", "doge"), "doge, wow");
assert_eq!(format!("{}", true), "true");
assert_eq!(format!("({:.3}, {:.3})", 0.5, f64::sqrt(3.0) / 2.0),
"(0.500, 0.866)");
// 使用上面定义的address
let formatted_addr: String = format!("{}", address);
assert_eq!(formatted_addr, "fe80::3ea9:f4ff:fe34:7a50");
2
3
4
5
6
7
Rust的所有基本数值类型都实现了Display,字符、字符串和切片也是如此。智能指针类型Box<T>、Rc<T>和Arc<T>如果T本身实现了Display,它们也会实现Display:它们的显示形式就是其引用对象的显示形式。像Vec和HashMap这样的容器没有实现Display,因为这些类型没有单一的自然人类可读形式。
- 如果一个类型实现了
Display,标准库会自动为它实现std::str::ToString特性,当你不需要format!的灵活性时,其唯一的方法to_string会更方便:
// 接续上面的代码
assert_eq!(address.to_string(),
"fe80::3ea9:f4ff:fe34:7a50");
2
3
ToString特性在Display特性之前引入,灵活性较差。对于你自己的类型,通常应该实现Display而不是ToString。
- 标准库中的每个公共类型都实现了
std::fmt::Debug,它接受一个值并将其格式化为对程序员有帮助的字符串。使用Debug生成字符串最简单的方法是通过format!宏的{:?}格式说明符:
// 接续上面的代码
let addresses = vec![address,
IpAddr::from_str("192.168.0.1")?];
assert_eq!(format!("{:?}", addresses),
"[fe80::3ea9:f4ff:fe34:7a50, 192.168.0.1]");
2
3
4
5
这利用了对任何实现了Debug的T,Vec<T>的通用Debug实现。Rust的所有集合类型都有这样的实现。
你也应该为自己的类型实现Debug。通常最好让Rust派生一个实现,就像我们在第12章为Complex类型所做的那样:
#[derive(Copy, Clone, Debug)]
struct Complex {
re: f64,
im: f64
}
2
3
4
5
Display和Debug格式化特性只是format!宏及其相关宏用于将值格式化为文本的几个特性中的两个。我们将在 “格式化值” 中介绍其他特性,并解释如何实现它们。
# 借用为其他类似文本的类型
你可以通过几种不同的方式借用切片的内容:
- 切片和字符串实现了
AsRef<str>、AsRef<[u8]>、AsRef<Path>和AsRef<OsStr>。许多标准库函数使用这些特性作为其参数类型的限定,所以你可以直接将切片和字符串传递给它们,即使它们真正需要的是其他类型。更多详细解释请参见 “AsRef和AsMut”。 - 切片和字符串还实现了
std::borrow::Borrow<str>特性。HashMap和BTreeMap使用Borrow特性,使String能够很好地作为表中的键。详细信息请参见 “Borrow和BorrowMut”。
# 以UTF-8形式访问文本
根据你是想获取文本字节的所有权还是仅借用它们,有两种主要方式来访问表示文本的字节:
slice.as_bytes():以&[u8]的形式借用slice的字节。由于这不是可变引用,slice可以假定其字节将始终保持格式良好的UTF-8编码。string.into_bytes():获取string的所有权,并按值返回一个包含该字符串字节的Vec<u8>。这是一种低成本的转换,因为它只是将字符串一直用作缓冲区的Vec<u8>移交出去。由于string不再存在,这些字节也就无需继续保持格式良好的UTF-8编码,调用者可以随意修改Vec<u8>。
# 从UTF-8数据生成文本
如果你有一段你认为包含UTF-8数据的字节,根据你处理错误的方式,有几种将其转换为String或切片的方法:
str::from_utf8(byte_slice):接受一个&[u8]字节切片并返回一个Result:如果byte_slice包含格式良好的UTF-8编码,则返回Ok(&str),否则返回错误。String::from_utf8(vec):尝试从按值传递的Vec<u8>构造一个字符串。如果vec中保存的是格式良好的UTF-8编码,from_utf8会返回Ok(string),其中string获取了vec的所有权并将其用作自身的缓冲区。这个过程不会进行堆分配或文本复制。如果字节不是有效的UTF-8编码,此方法返回Err(e),其中e是FromUtf8Error错误值。调用e.into_bytes()会将原始向量vec返回给你,所以在转换失败时,向量不会丢失:
let good_utf8: Vec<u8> = vec![0xe9, 0x8c, 0x86];
assert_eq!(String::from_utf8(good_utf8).ok(), Some("錆".to_string()));
let bad_utf8: Vec<u8> = vec![0x9f, 0xf0, 0xa6, 0x80];
let result = String::from_utf8(bad_utf8);
assert!(result.is_err());
// 由于String::from_utf8失败,它没有消耗原始向量,并且错误值将其完好无损地返回给我们。
assert_eq!(result.unwrap_err().into_bytes(), vec![0x9f, 0xf0, 0xa6, 0x80]);
2
3
4
5
6
7
8
String::from_utf8_lossy(byte_slice):尝试从&[u8]共享字节切片构造一个String或&str。这种转换总是会成功,它会用Unicode替换字符替换任何格式错误的UTF-8编码部分。返回值是一个Cow<str>,如果byte_slice包含格式良好的UTF-8编码,它会直接借用byte_slice中的&str;否则,它会拥有一个新分配的String,其中格式错误的字节已被替换字符取代。因此,当byte_slice格式良好时,不会进行堆分配或复制。我们将在 “推迟分配” 中更详细地讨论Cow<str>。String::from_utf8_unchecked:如果你确定你的Vec<u8>包含格式良好的UTF-8编码,那么你可以调用这个不安全函数。它只是将Vec<u8>包装成一个String并返回,根本不会检查字节。你需要确保没有将格式错误的UTF-8引入系统,这就是为什么这个函数被标记为不安全的原因。str::from_utf8_unchecked:类似地,这个函数接受一个&[u8]并将其作为&str返回,而不检查它是否包含格式良好的UTF-8编码。与String::from_utf8_unchecked一样,你要负责确保这样做是安全的。
# 推迟分配
假设你希望程序向用户打招呼。在Unix系统上,你可以这样写:
fn get_name() -> String {
std::env::var("USER") // Windows使用"USERNAME"
.unwrap_or("whoever you are".to_string())
}
println!("Greetings, {}!", get_name());
2
3
4
5
6
对于Unix用户,这会用他们的用户名向他们打招呼。对于Windows用户和没有设置用户名的用户,它会提供备用的通用文本。
std::env::var函数返回一个String,并且有充分的理由这样做(我们在此不深入讨论)。但这意味着备用的通用文本也必须作为String返回。这有点令人失望:当get_name返回一个静态字符串时,根本不需要进行分配。
问题的关键在于,有时get_name的返回值应该是一个拥有所有权的String,有时应该是一个&'static str,而在运行程序之前我们无法知道会是哪一种。这种动态特性暗示我们可以考虑使用std::borrow::Cow,即写时复制类型,它可以持有拥有所有权的数据或借用的数据。
正如在 “借用和ToOwned的应用:不起眼的Cow” 中所解释的,Cow<'a, T>是一个枚举,有两个变体:Owned和Borrowed。Borrowed持有一个引用&'a T,Owned持有&T的拥有所有权的版本:对于&str是String,对于&[i32]是Vec<i32>,依此类推。无论Cow<'a, T>是Owned还是Borrowed,它总是可以为你提供一个&T以供使用。实际上,Cow<'a, T>可以解引用为&T,其行为类似于一种智能指针。
将get_name修改为返回一个Cow,代码如下:
use std::borrow::Cow;
fn get_name() -> Cow<'static, str> {
std::env::var("USER")
.map(|v| Cow::Owned(v))
.unwrap_or(Cow::Borrowed("whoever you are"))
}
2
3
4
5
6
7
如果成功读取了"USER"环境变量,map会将得到的String作为Cow::Owned返回。如果读取失败,unwrap_or会将其静态的&str作为Cow::Borrowed返回。调用者可以保持不变:
println!("Greetings, {}!", get_name());
只要T实现了std::fmt::Display特性,显示Cow<'a, T>与显示T会产生相同的结果。
当你可能需要也可能不需要修改借用的某些文本时,Cow也很有用。当不需要修改时,你可以继续借用它。但是Cow的写时复制行为可以根据需要为你提供值的拥有所有权的可变副本。Cow的to_mut方法会确保Cow是Cow::Owned,必要时应用值的ToOwned实现,然后返回对该值的可变引用。
所以,如果你发现部分用户(但不是所有用户)有他们希望被称呼的头衔,你可以这样写:
fn get_title() -> Option<&'static str> { ... }
let mut name = get_name();
if let Some(title) = get_title() {
name.to_mut().push_str(", ");
name.to_mut().push_str(title);
}
println!("Greetings, {}!", name);
2
3
4
5
6
7
8
这可能会产生如下输出:
$ cargo run
Greetings, jimb, Esq.!
$
2
3
这里的好处是,如果get_name()返回一个静态字符串且get_title返回None,Cow会直接将静态字符串传递给println!。你成功地推迟了分配,直到真正有必要时才进行,同时代码仍然很简洁。
由于Cow经常用于字符串,标准库对Cow<'a, str>有一些特殊支持。它提供了从String和&str的From和Into转换,所以你可以更简洁地编写get_name:
fn get_name() -> Cow<'static, str> {
std::env::var("USER")
.map(|v| v.into())
.unwrap_or("whoever you are".into())
}
2
3
4
5
Cow<'a, str>也实现了std::ops::Add和std::ops::AddAssign,所以要给名字添加头衔,你可以这样写:
if let Some(title) = get_title() {
name += ", ";
name += title;
}
2
3
4
或者,由于String可以作为write!宏的目标:
use std::fmt::Write;
if let Some(title) = get_title() {
write!(name.to_mut(), ", {}", title).unwrap();
}
2
3
4
和之前一样,在尝试修改Cow之前不会进行分配。
请记住,并非每个Cow<..., str>都必须是'static的:你可以使用Cow借用之前计算好的文本,直到需要复制的那一刻。
# 字符串作为通用集合
String实现了std::default::Default和std::iter::Extend:default返回一个空字符串,extend可以将字符、字符串切片、Cow<..., str>或字符串追加到字符串的末尾。这与Rust的其他集合类型(如Vec和HashMap)为通用构造模式(如collect和partition)实现的特性组合相同。
&str类型也实现了Default,返回一个空切片。这在一些特殊情况下很有用;例如,它允许你为包含字符串切片的结构体派生Default实现。
# 格式化值
在本书中,我们一直在使用像println!这样的文本格式化宏:
println!("{:.3}µs: relocated {} at {:#x} to {:#x}, {} bytes",
0.84391, "object",
140737488346304_usize, 6299664_usize, 64);
2
3
上述调用会产生如下输出:
0.844µs: relocated object at 0x7fffffffdcc0 to 0x602010, 64 bytes
字符串字面值充当输出的模板:模板中的每个{...}都会被后面参数的格式化形式替换。模板字符串必须是常量,这样Rust才能在编译时根据参数的类型进行检查。每个参数都必须被使用,否则Rust会报告编译时错误。
标准库中的几个功能都使用这种格式化字符串的小语言:
format!宏使用它来构建String。println!和print!宏将格式化后的文本写入标准输出流。writeln!和write!宏将其写入指定的输出流。panic!宏使用它来构建一个(理想情况下信息丰富的)表示终止异常的表达式。
Rust的格式化功能设计为开放式的。你可以通过实现std::fmt模块中的格式化特性,扩展这些宏以支持自己的类型。你还可以使用format_args!宏和std::fmt::Arguments类型,使自己的函数和宏支持这种格式化语言。
格式化宏总是借用参数的共享引用,它们从不获取参数的所有权,也不会对其进行修改。
模板中的{...}形式称为格式参数,其形式为{which:how}。这两部分都是可选的,{}也经常被使用。
which值用于选择模板后面的哪个参数应该占据该参数的位置。你可以通过索引或名称选择参数。没有which值的参数会简单地从左到右与参数配对。
how值表示参数应该如何格式化,比如需要多少填充、精度是多少、使用哪种数字基数等等。如果存在how值,则其前面的冒号是必需的。表17-4展示了一些示例。
表17-4. 格式化字符串示例
| 模板字符串 | 参数列表 | 结果 |
|---|---|---|
| "number of {}: {}" | "elephants", 19 | "number of elephants: 19" |
| "from {1} to {0}" | "the grave", "the cradle" | "from the cradle to the grave" |
| "v = {:?}" | vec![0,1,2,5,12,29] | "v = [0, 1, 2, 5, 12, 29]" |
| "name = {:?}" | "Nemo" | "name = "Nemo"" |
| "{:8.2} km/s" | 11.186 | " 11.19 km/s" |
| "{:20} {:02x} {:02 x}" | "adc #42", 105, 42 | "adc #42 69 2a" |
| "{1:02x} {2:02x} {0}" | "adc #42", 105, 42 | "69 2a adc #42" |
| "{lsb:02x} {msb:02x} {insn}" | insn="adc #42", lsb=105, msb=42 | "69 2a adc #42" |
| "{:02?}" | [110, 11, 9] | "[110, 11, 09]" |
| "{:02x?}" | [110, 11, 9] | "[6e, 0b, 09]" |
如果你想在输出中包含{或}字符,在模板中把这些字符加倍即可:
assert_eq!(format!("{{a, c}} ⊂ {{a, b, c}}"),
"{a, c} ⊂ {a, b, c}");
2
# 格式化文本值
格式化像&str或String(char被当作单字符字符串处理)这样的文本类型时,参数的how值有几个部分,均为可选:
- 文本长度限制:如果参数的长度超过此限制,Rust会截断它。如果未指定限制,Rust会使用完整的文本。
- 最小字段宽度:在进行任何截断之后,如果参数的长度小于此宽度,Rust会(默认)在右侧用(默认的)空格进行填充,使其达到该字段宽度。如果省略此选项,Rust不会对参数进行填充。
- 对齐方式:如果需要对参数进行填充以满足最小字段宽度,此选项指定文本应在字段中的位置。
<、^和>分别将文本置于起始、中间和末尾位置。 - 填充字符:用于填充过程的字符。如果省略,Rust使用空格。如果你指定了填充字符,则还必须指定对齐方式。
表17-5展示了一些示例,说明了如何编写格式化指令以及它们的效果。所有示例都使用相同的八个字符的参数"bookends"。
表17-5. 文本的格式化字符串指令
| 使用的特性 | 模板字符串 | 结果 |
|---|---|---|
| 默认 | {} | "bookends" |
| 最小字段宽度 | {:4} | "bookends" |
{:12} | "bookends " | |
| 文本长度限制 | {:.4} | "book" |
{:.12} | "bookends" | |
| 字段宽度、长度限制 | {:12.20} | "bookends " |
{:4.20} | "bookends" | |
{:4.6} | "booken" | |
{:6.4} | "book " | |
| 左对齐、宽度 | {:<12} | "bookends " |
| 居中、宽度 | {:^12} | " bookends " |
| 右对齐、宽度 | {:>12} | " bookends" |
用=填充、居中、宽度 | {:=^12} | "==bookends==" |
用*填充、右对齐、宽度、限制 | {:*>12.4} | "********book" |
Rust的格式化器对宽度的理解比较简单:它假设每个字符占用一列,不考虑组合字符、半角片假名、零宽空格或Unicode的其他复杂情况。例如:
assert_eq!(format!("{:4}", "th\u{e9}"), "th\u{e9} ");
assert_eq!(format!("{:4}", "the\u{301}"), "the\u{301}");
2
虽然Unicode规定这些字符串都等同于thé,但Rust的格式化器不知道像\u{301}(组合尖音符)这样的字符需要特殊处理。它对第一个字符串的填充是正确的,但认为第二个字符串宽度为四列,因此没有添加填充。虽然很容易看出Rust在这种特定情况下可以如何改进,但对所有Unicode脚本进行真正的多语言文本格式化是一项艰巨的任务,最好依靠平台的用户界面工具包来处理,或者生成HTML和CSS,让网页浏览器来整理。有一个很受欢迎的库unicode-width可以处理这方面的一些问题。
除了&str和String,你还可以直接将具有文本引用的智能指针类型(如Rc<String>或Cow<'a, str>)传递给格式化宏。
由于文件名路径不一定是格式良好的UTF-8,std::path::Path不完全是文本类型,你不能直接将std::path::Path传递给格式化宏。不过,Path的display方法返回的值可以进行格式化,它会以适合平台的方式处理相关问题:
println!("processing file: {}", path.display());
# 格式化数字
当格式化参数是像usize或f64这样的数值类型时,参数的how值有以下几个部分,均为可选:
- 填充和对齐:与文本类型的处理方式相同。
+字符:要求即使参数为正数,也始终显示其符号。#字符:要求添加明确的基数前缀,如0x或0b。见本列表最后的“表示法”项。0字符:要求通过在数字前添加前导零来满足最小字段宽度,而不是使用通常的填充方式。- 最小字段宽度:如果格式化后的数字宽度小于此值,Rust会(默认)在左侧用(默认的)空格进行填充,使其达到给定的宽度。
- 浮点型参数的精度:表示Rust应在小数点后包含多少位数字。Rust会根据需要进行四舍五入或补零,以精确生成这么多小数位。对于整型参数,精度会被忽略 。
- 表示法:对于整型,
b表示二进制,o表示八进制,x或X分别表示使用小写或大写字母的十六进制。如果你包含了#字符,这些会添加明确的Rust风格的基数前缀0b、0o、0x或0X。对于浮点型,基数e或E要求使用科学计数法,带有规范化的系数,用e或E表示指数。如果你未指定任何表示法,Rust会以十进制格式化数字。
表17-6展示了一些格式化i32值1234的示例。
表17-6. 整数的格式化字符串指令
| 使用的特性 | 模板字符串 | 结果 |
|---|---|---|
| 默认 | {} | "1234" |
| 强制显示符号 | {:+} | "+1234" |
| 最小字段宽度 | {:12} | " 1234" |
{:2} | "1234" | |
| 符号、宽度 | {:+12} | " +1234" |
| 前导零、宽度 | {:012} | "000000001234" |
| 符号、前导零、宽度 | {:+012} | "+00000001234" |
| 左对齐、宽度 | {:<12} | "1234 " |
| 居中、宽度 | {:^12} | " 1234 " |
| 右对齐、宽度 | {:>12} | " 1234" |
| 左对齐、符号、宽度 | {:<+12} | "+1234 " |
| 居中、符号、宽度 | {:^+12} | " +1234 " |
| 右对齐、符号、宽度 | {:>+12} | " +1234" |
用=填充、居中、宽度 | {:=^12} | "====1234====" |
| 二进制表示法 | {:b} | "10011010010" |
| 宽度、八进制表示法 | {:12o} | " 2322" |
| 符号、宽度、十六进制表示法 | {:+12x} | " +4d2" |
| 符号、宽度、大写十六进制表示法 | {:+12X} | " +4D2" |
| 符号、明确的基数前缀、宽度、十六进制 | {:+#12x} | " +0x4d2" |
| 符号、基数、前导零、宽度、十六进制 | {:+#012x} | "+0x0000004d2" |
{:+#06x} | "+0x4d2" |
最后两个示例表明,最小字段宽度适用于整个数字,包括符号、基数前缀等。负数总是包含它们的符号,结果与“强制显示符号”示例中的类似。
当你要求添加前导零时,对齐和填充字符会被忽略,因为零会扩展数字以填满整个字段。
使用参数1234.5678,我们可以展示浮点型特有的效果(表17-7)。
表17-7. 浮点数的格式化字符串指令
| 使用的特性 | 模板字符串 | 结果 |
|---|---|---|
| 默认 | {} | "1234.5678" |
| 精度 | {:.2} | "1234.57" |
{:.6} | "1234.567800" | |
| 最小字段宽度 | {:12} | " 1234.5678" |
| 最小字段宽度、精度 | {:12.2} | " 1234.57" |
{:12.6} | " 1234.567800" | |
| 前导零、最小字段宽度、精度 | {:012.6} | "01234.567800" |
| 科学计数法 | {:e} | "1.2345678e3" |
| 科学计数法、精度 | {:.3e} | "1.235e3" |
| 科学计数法、最小字段宽度、精度 | {:12.3e} | " 1.235e3" |
{:12.3E} | " 1.235E3" |
# 格式化其他类型
除了字符串和数字,你还可以格式化其他几种标准库类型:
- 错误类型都可以直接格式化,这使得将它们包含在错误消息中变得很容易。每个错误类型都应该实现
std::error::Error特性,该特性扩展了默认的格式化特性std::fmt::Display。因此,任何实现了Error的类型都可以直接进行格式化。 - 你可以格式化网络协议地址类型,如
std::net::IpAddr和std::net::SocketAddr。 - 布尔值
true和false也可以格式化,不过通常这些字符串并不适合直接展示给终端用户。
你应该使用与格式化字符串时相同的格式参数。长度限制、字段宽度和对齐控制的工作方式与预期一致。
# 为调试而格式化值
为了帮助调试和记录日志,{:?}参数以一种对程序员有帮助的方式格式化Rust标准库中的任何公共类型。你可以使用它来检查向量、切片、元组、哈希表、线程以及其他数百种类型。
例如,你可以这样写:
use std::collections::HashMap;
let mut map = HashMap::new();
map.insert("Portland", (45.5237606, -122.6819273));
map.insert("Taipei", (25.0375167, 121.5637));
println!("{:?}", map);
2
3
4
5
6
这段代码的输出为:
{"Taipei": (25.0375167, 121.5637), "Portland": (45.5237606, -122.6819273)}
HashMap和(f64, f64)类型已经知道如何自行格式化,无需你额外费力。
如果你在格式参数中包含#字符,Rust会对值进行漂亮打印。将上述代码改为println!("{:#?}", map),会得到如下输出:
{
"Taipei": (
25.0375167,
121.5637
),
"Portland": (
45.5237606,
-122.6819273
)
}
2
3
4
5
6
7
8
9
10
这些确切的格式并不保证一成不变,有时会在不同的Rust版本之间有所变化。
调试格式化通常以十进制打印数字,但你可以在问号前加上x或X来要求以十六进制打印。前导零和字段宽度语法也同样适用。例如,你可以这样写:
println!("ordinary: {:02?}", [9, 15, 240]);
println!("hex: {:02x?}", [9, 15, 240]);
2
这段代码的输出为:
ordinary: [09, 15, 240]
hex: [09, 0f, f0]
2
如前所述,你可以使用#[derive(Debug)]语法,使你自己的类型能够与{:?}一起使用:
#[derive(Copy, Clone, Debug)]
struct Complex {
re: f64,
im: f64
}
2
3
4
5
有了这个定义后,我们可以使用{:?}格式来打印Complex值:
let third = Complex { re: -0.5, im: f64::sqrt(0.75) };
println!("{:?}", third);
2
这段代码的输出为:
Complex { re: -0.5, im: 0.8660254037844386 }
这对于调试来说已经足够,但如果{}能以更传统的形式打印它们,比如-0.5 + 0.8660254037844386i,那就更好了。在“格式化你自己的类型”中,我们将展示如何实现这一点。
# 为调试而格式化指针
通常情况下,如果你将任何类型的指针(引用、Box、Rc等)传递给格式化宏,宏只会跟随指针并格式化其引用的对象,指针本身并不受关注。但在调试时,有时查看指针会很有帮助:地址可以作为单个值的大致“名称”,在检查具有循环或共享的结构时,这可能会很有启发性。
{:p}表示法将引用、Box和其他类似指针的类型格式化为地址:
use std::rc::Rc;
let original = Rc::new("mazurka".to_string());
let cloned = original.clone();
let impostor = Rc::new("mazurka".to_string());
println!("text: {}, {}, {}", original, cloned, impostor);
println!("pointers: {:p}, {:p}, {:p}", original, cloned, impostor);
2
3
4
5
6
7
8
这段代码的输出为:
text: mazurka, mazurka, mazurka
pointers: 0x7f99af80e000, 0x7f99af80e000, 0x7f99af80e030
2
当然,每次运行时具体的指针值会有所不同,但即便如此,通过比较地址可以清楚地看出,前两个指针引用的是同一个String,而第三个指针指向一个不同的值。
地址看起来往往像一堆十六进制数字,所以更精细的可视化可能会很有用,但{:p}这种方式仍然是一种简单有效的快速解决方案。
# 通过索引或名称引用参数
格式参数可以显式选择它使用的参数。例如:
assert_eq!(format!("{1},{0},{2}", "zeroth", "first", "second"),
"first,zeroth,second");
2
你可以在冒号后包含格式参数:
assert_eq!(format!("{2:#06x},{1:b},{0:=>10}", "first", 10, 100),
"0x0064,1010,=====first");
2
你还可以通过名称选择参数。这使得包含许多参数的复杂模板更易读。例如:
assert_eq!(format!("{description:.<25}{quantity:2} @ {price:5.2}",
price = 3.25,
quantity = 3,
description = "Maple Turmeric Latte"),
"Maple Turmeric Latte ..... 3 @ 3.25");
2
3
4
5
(这里的命名参数类似于Python中的关键字参数,但这只是格式化宏的一个特殊功能,并非Rust函数调用语法的一部分。)
你可以在单个格式化宏的使用中混合使用索引、命名和位置(即没有索引或名称)参数。位置参数会从左到右与参数配对,就好像索引和命名参数不存在一样:
assert_eq!(format!("{mode} {2} {} {}",
"people", "eater", "purple", mode = "flying"),
"flying purple people eater");
2
3
命名参数必须出现在参数列表的末尾。
# 动态宽度和精度
参数的最小字段宽度、文本长度限制和数字精度不必总是固定值,你可以在运行时选择它们。
我们之前看到过这样的表达式,它将字符串内容在一个20字符宽的字段中右对齐:
format!("{:>20}", content)
但如果你想在运行时选择字段宽度,可以这样写:
format!("{:>1$}", content, get_width())
将最小字段宽度写成1$,这告诉format!使用第二个参数的值作为宽度。这里引用的参数必须是usize类型。你也可以通过名称引用参数:
format!("{:>width$}", content, width = get_width())
同样的方法也适用于文本长度限制:
format!("{:>width$.limit$}", content,
width = get_width(), limit = get_limit())
2
你还可以用*代替文本长度限制或浮点精度,这表示将下一个位置参数作为精度。下面的代码将content最多裁剪为get_limit()个字符:
format!("{:.*}", get_limit(), content)
用作精度的参数必须是usize类型。目前没有对应字段宽度的类似语法。
# 格式化你自己的类型
格式化宏使用std::fmt模块中定义的一组特性将值转换为文本。你可以通过自己实现这些特性中的一个或多个,让Rust的格式化宏能够格式化你自己的类型。
格式参数的表示法表明了其参数类型必须实现的特性,如表17-8所示。 表17-8. 格式化字符串指令表示法
| 表示法 | 示例 | 特性 | 目的 |
|---|---|---|---|
| 无 | {} | std::fmt::Display | 文本、数字、错误:通用特性 |
b | {bits:#b} | std::fmt::Bin | 以二进制表示数字 |
o | {:#5o} | std::fmt::Oct | 以八进制表示数字 |
x | {:4x} | std::fmt::LowerHex | 以十六进制表示数字,小写字母 |
X | {:016X} | std::fmt::UpperHex | 以十六进制表示数字,大写字母 |
e | {:.3e} | std::fmt::LowerExp | 以科学计数法表示浮点数 |
E | {:.3E} | std::fmt::UpperExp | 以科学计数法表示浮点数,大写E |
? | {:#?} | std::fmt::Debug | 用于开发者调试的视图 |
p | {:p} | std::fmt::Pointer | 将指针格式化为地址,用于开发者 |
当你在类型定义上使用#[derive(Debug)]属性,以便能够使用{:?}格式参数时,你实际上是让Rust为你实现std::fmt::Debug特性。
所有格式化特性都具有相同的结构,仅名称不同。我们以std::fmt::Display为例:
trait Display {
fn fmt(&self, dest: &mut std::fmt::Formatter) -> std::fmt::Result;
}
2
3
fmt方法的任务是生成self的正确格式化表示,并将其字符写入dest。除了作为输出流之外,dest参数还包含从格式参数解析出的详细信息,如对齐方式和最小字段宽度。
例如,在本章前面我们提到,如果Complex值能以通常的a + bi形式打印会更好。下面是一个实现此功能的Display实现:
use std::fmt;
impl fmt::Display for Complex {
fn fmt(&self, dest: &mut fmt::Formatter) -> fmt::Result {
let im_sign = if self.im < 0.0 { '-' } else { '+' };
write!(dest, "{} {} {}i", self.re, im_sign, f64::abs(self.im))
}
}
2
3
4
5
6
7
8
这里利用了Formatter本身就是一个输出流的事实,所以write!宏可以为我们完成大部分工作。有了这个实现后,我们可以这样写:
let one_twenty = Complex { re: -0.5, im: 0.866 };
assert_eq!(format!("{}", one_twenty), "-0.5 + 0.866i");
let two_forty = Complex { re: -0.5, im: -0.866 };
assert_eq!(format!("{}", two_forty), "-0.5 - 0.866i");
2
3
4
5
有时以极坐标形式显示复数会很有帮助:想象在复平面上从原点到该复数画一条线,极坐标形式给出这条线的长度以及它与正x轴顺时针方向的夹角。格式参数中的#字符通常用于选择某种替代显示形式;Display实现可以将其视为使用极坐标形式的请求:
impl fmt::Display for Complex {
fn fmt(&self, dest: &mut fmt::Formatter) -> fmt::Result {
let (re, im) = (self.re, self.im);
if dest.alternate() {
let abs = f64::sqrt(re * re + im * im);
let angle = f64::atan2(im, re) / std::f64::consts::PI * 180.0;
write!(dest, "{} ∠ {}°", abs, angle)
} else {
let im_sign = if im < 0.0 { '-' } else { '+' };
write!(dest, "{} {} {}i", re, im_sign, f64::abs(im))
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
使用这个实现:
let ninety = Complex { re: 0.0, im: 2.0 };
assert_eq!(format!("{}", ninety), "0 + 2i");
assert_eq!(format!("{:#}", ninety), "2 ∠ 90°");
2
3
虽然格式化特性的fmt方法返回一个fmt::Result值(一种特定于模块的Result类型),但你应该只传播Formatter操作中的错误,就像fmt::Display实现中调用write!时那样;你的格式化函数本身绝不能产生错误。这使得像format!这样的宏可以直接返回一个String,而不是Result<String, ...>,因为将格式化后的文本追加到String中永远不会失败。这也确保了你从write!或writeln!得到的任何错误都反映了底层I/O流的实际问题,而不是格式化问题。
Formatter还有许多其他有用的方法,包括一些用于处理像映射、列表等结构化数据的方法,这里我们不做介绍;你可以查阅在线文档获取完整详细信息。
# 在自己的代码中使用格式化语言
你可以通过使用Rust的format_args!宏和std::fmt::Arguments类型,编写自己的函数和宏来接受格式模板和参数。例如,假设你的程序在运行时需要记录状态消息,并且你希望使用Rust的文本格式化语言来生成这些消息。以下是一个简单的示例:
fn logging_enabled() -> bool { ... }
use std::fs::OpenOptions;
use std::io::Write;
fn write_log_entry(entry: std::fmt::Arguments) {
if logging_enabled() {
// 目前先简单处理,每次都打开文件
let mut log_file = OpenOptions::new()
.append(true)
.create(true)
.open("log-file-name")
.expect("failed to open log file");
log_file.write_fmt(entry)
.expect("failed to write to log");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
你可以这样调用write_log_entry:
write_log_entry(format_args!("Hark! {:?}\n ", mysterious_value));
在编译时,format_args!宏会解析模板字符串,并根据参数的类型进行检查,如果有任何问题会报告错误。在运行时,它会计算参数的值,并构建一个Arguments值,其中包含格式化文本所需的所有信息:模板的预解析形式,以及对参数值的共享引用。
构建一个Arguments值的成本很低:它只是收集一些指针。此时还不会进行格式化工作,只是收集后续格式化所需的信息。这一点很重要:如果未启用日志记录,那么将数字转换为十进制、填充值等操作所花费的时间都将被浪费。
File类型实现了std::io::Write特性,其write_fmt方法接受一个Argument并进行格式化,然后将结果写入底层流。上面调用write_log_entry的代码看起来不太美观,这时宏就可以发挥作用了:
macro_rules! log { // 在宏定义中,名称后不需要!
($format:tt, $($arg:expr),*) => (
write_log_entry(format_args!($format, $($arg),*))
)
}
2
3
4
5
我们将在第21章详细介绍宏。目前,你只需相信这个定义了一个新的log!宏,它会将参数传递给format_args!,然后对生成的Arguments值调用你的write_log_entry函数。像println!、writeln!和format!这样的格式化宏,原理大致相同。
你可以这样使用log!:
log!("O day and night, but this is wondrous strange! {:?}\n ", mysterious_value);
这样看起来会更好一些。
# 正则表达式
外部的regex库是Rust官方的正则表达式库。它提供了常见的搜索和匹配函数,对Unicode有很好的支持,同时也可以搜索字节字符串。虽然它不支持其他正则表达式包中常见的一些特性,如反向引用和环视模式,但这些简化使得regex库能够确保搜索时间与表达式的大小以及被搜索文本的长度呈线性关系。这些保证,以及其他特性,使得即使在使用不可信的表达式搜索不可信的文本时,regex库也是安全可用的。
在本书中,我们只对regex库进行概述;具体细节你应该查阅其在线文档。
虽然regex库不在标准库std中,但它由负责std的Rust库团队维护。要使用regex库,在你的Cargo.toml文件的[dependencies]部分添加以下内容:
regex = "1"
在接下来的内容中,我们假设你已经完成了上述修改。
# 正则表达式的基本用法
Regex值表示一个已解析好、可使用的正则表达式。Regex::new构造函数尝试将&str解析为正则表达式,并返回一个Result:
use regex::Regex;
// 语义化版本号,如0.2.1。
// 可能包含预发布版本后缀,如0.2.1-alpha。
// (为简洁起见,不包含构建元数据后缀。)
//
// 注意使用r"... "原始字符串语法,以避免反斜杠带来的麻烦。
let semver = Regex::new(r"(\d+)\.(\d+)\.(\d+)(-[-.[[:alnum:]]*)?")?;
// 简单搜索,返回布尔结果。
let haystack = r#"regex = "0.2.5""#;
assert!(semver.is_match(haystack));
2
3
4
5
6
7
8
9
10
Regex::captures方法在字符串中搜索第一个匹配项,并返回一个regex::Captures值,该值保存了表达式中每个组的匹配信息:
// 你可以获取捕获组
let captures = semver.captures(haystack)
.ok_or("semver regex should have matched")?;
assert_eq!(&captures[0], "0.2.5");
assert_eq!(&captures[1], "0");
assert_eq!(&captures[2], "2");
assert_eq!(&captures[3], "5");
2
3
4
5
6
7
如果请求的组未匹配,对Captures值进行索引会导致程序恐慌(panic)。要测试特定的组是否匹配,可以调用Captures::get,它会返回一个Option<regex::Match>。Match值记录了单个组的匹配情况:
assert_eq!(captures.get(4), None);
assert_eq!(captures.get(3).unwrap().start(), 13);
assert_eq!(captures.get(3).unwrap().end(), 14);
assert_eq!(captures.get(3).unwrap().as_str(), "5");
2
3
4
你可以迭代字符串中的所有匹配项:
let haystack = "In the beginning, there was 1.0.0. \
For a while, we used 1.0.1-beta, \
but in the end, we settled on 1.2.4.";
let matches: Vec<&str> = semver.find_iter(haystack)
.map(|match_| match_.as_str())
.collect();
assert_eq!(matches, vec!["1.0.0", "1.0.1-beta", "1.2.4"]);
2
3
4
5
6
7
find_iter迭代器会从字符串开头到结尾,为表达式的每个不重叠匹配项生成一个Match值。captures_iter方法类似,但会生成记录所有捕获组的Captures值。当需要报告捕获组时,搜索速度会变慢,所以如果你不需要捕获组,最好使用不返回它们的方法之一。
# 延迟构建正则表达式值
Regex::new构造函数可能开销较大:在快速的开发机器上,构建一个1200字符的正则表达式可能需要近一毫秒,即使是简单的表达式也需要几微秒。最好避免在繁重的计算循环中构建Regex;相反,你应该只构建一次Regex,然后重复使用它。
lazy_static库提供了一种很好的方式来延迟初始化静态值,在它们第一次被使用时才进行构建。首先,在你的Cargo.toml文件中添加依赖:
[dependencies]
lazy_static = "1"
2
这个库提供了一个宏来声明这样的变量:
use lazy_static::lazy_static;
lazy_static! {
static ref SEMVER: Regex = Regex::new(r"(\d+)\.(\d+)\.(\d+)(-[-.[[:alnum:]]*)?")
.expect("error parsing regex");
}
2
3
4
5
6
这个宏展开后会声明一个名为SEMVER的静态变量,但其类型并不完全是Regex。实际上,它是一个由宏生成的类型,实现了Deref<Target = Regex>,因此它暴露了与Regex相同的所有方法。在第一次解引用SEMVER时,会计算初始化器的值,并将结果保存以供后续使用。由于SEMVER是一个静态变量,而不仅仅是局部变量,所以初始化器在程序执行期间最多运行一次 。
有了这个声明后,使用SEMVER就很简单了:
use std::io::BufRead;
let stdin = std::io::stdin();
for line_result in stdin.lock().lines() {
let line = line_result?;
if let Some(match_) = SEMVER.find(&line) {
println!("{}", match_.as_str());
}
}
2
3
4
5
6
7
8
9
你可以将lazy_static!声明放在模块中,甚至放在使用Regex的函数内部,如果这样的作用域最合适的话。正则表达式在每次程序执行时仍然只会被编译一次。
# 规范化
大多数用户会认为法语中“茶”这个词“thé”是由三个字符组成的。然而,Unicode实际上有两种表示这个文本的方式:
- 在组合形式中,“thé”由三个字符“t”、“h”和“é”组成,其中“é”是一个Unicode字符,码点为0xe9。
- 在分解形式中,“thé”由四个字符“t”、“h”、“e”和“\u{301}”组成,这里的“e”是普通的ASCII字符,没有重音,而码点0x301是“组合尖音符”字符,它会给跟随其后的任何字符添加一个尖音符。
Unicode并不认为“é”的组合形式或分解形式哪一个是“正确”的,而是认为它们都是同一个抽象字符的等效表示。Unicode规定这两种形式都应以相同的方式显示,并且文本输入方法可以生成任意一种形式,所以用户通常不会知道他们看到或输入的是哪种形式。(Rust允许你在字符串字面量中直接使用Unicode字符,所以如果你不关心得到哪种编码,你可以直接写“thé”。这里为了清晰起见,我们使用\u转义。)
然而,作为Rust的&str或String值,"th\u{e9}"和"the\u{301}"是完全不同的。它们长度不同,比较结果不相等,哈希值也不同,并且与其他字符串排序时顺序也不同:
assert!("th\u{e9}" != "the\u{301}");
assert!("th\u{e9}" > "the\u{301}");
// Hasher设计用于累积一系列值的哈希值,
// 所以只对一个值进行哈希有点麻烦。
use std::hash::{Hash, Hasher};
use std::collections::hash_map::DefaultHasher;
fn hash<T: ?Sized + Hash>(t: &T) -> u64 {
let mut s = DefaultHasher::new();
t.hash(&mut s);
s.finish()
}
// 这些值在未来的Rust版本中可能会改变。
assert_eq!(hash("th\u{e9}"), 0x53e2d0734eb1dff3);
assert_eq!(hash("the\u{301}"), 0x90d837f0a0928144);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
显然,如果你打算比较用户提供的文本,或者将其用作哈希表或B树中的键,你需要首先将每个字符串转换为某种规范形式。
幸运的是,Unicode为字符串指定了规范化形式。根据Unicode的规则,每当两个字符串应被视为等效时,它们的规范化形式在字符层面上是完全相同的。当用UTF - 8编码时,它们在字节层面上也是完全相同的。这意味着你可以使用==比较规范化后的字符串,将它们用作HashMap或HashSet中的键等等,并且你会得到符合Unicode定义的相等性判断结果。
不进行规范化甚至可能会带来安全问题。例如,如果你的网站在某些情况下对用户名进行规范化,而在其他情况下不进行,你可能会得到两个不同的用户,用户名都是“bananasflambé”,但你的代码的某些部分会将他们视为同一个用户,而其他部分会区分他们,从而导致其中一个用户的权限被错误地扩展到另一个用户。当然,有很多方法可以避免这类问题,但历史表明,也有很多方法会导致问题发生。
# 规范化形式
Unicode定义了四种规范化形式,每种形式都适用于不同的用途。有两个问题需要考虑:
- 首先,你更倾向于字符尽可能是组合形式还是分解形式?例如,越南语单词“Phở”最紧凑的组合表示形式是三个字符的字符串
"Ph\u{1edf}",其中声调符号“̉”和元音符号“̛”都应用于基本字符“o”,形成一个Unicode字符'\u{1edf}',Unicode将其命名为“带有上角和上弯的拉丁小写字母o”。最分解的表示形式将基本字母及其两个符号拆分为三个单独的Unicode字符:“o”、“\u{31b}”(组合上角符号)和“\u{309}”(组合上弯符号),结果为“Pho\u{31b}\u{309}”。(每当组合符号作为单独的字符出现,而不是作为组合字符的一部分时,所有规范化形式都指定了它们必须出现的固定顺序,所以即使字符有多个重音符号,规范化也是明确指定的。)组合形式通常兼容性问题较少,因为它更接近Unicode建立之前大多数语言使用的文本表示形式。它可能也能更好地与像Rust的format!宏这样简单的字符串格式化功能配合使用。另一方面,分解形式可能更适合显示文本或搜索,因为它使文本的详细结构更加明确。 - 第二个问题是:如果两个字符序列表示相同的基本文本,但在文本格式化方式上有所不同,你是希望将它们视为等效还是区分它们?Unicode为普通数字“5”、上标数字“⁵”(即
\u{2075})和带圈数字“⑤”(即\u{2464})分别定义了字符,但声明这三个字符是兼容等效的。类似地,Unicode为连字“ffi”(\u{fb03})定义了一个单独的字符,但声明它与三个字符的序列“ffi”是兼容等效的。兼容性等效在搜索时很有用:使用仅包含ASCII字符的“difficult”进行搜索,应该匹配包含连字“ffi”的字符串“di\u{fb03}cult”。对后一个字符串应用兼容性分解会将连字替换为三个普通字母“ffi”,使搜索更容易。但是将文本规范化为兼容等效形式可能会丢失重要信息,所以不应随意应用。例如,在大多数情况下,将“2⁵”存储为“25”是不正确的。
Unicode规范化形式C和规范化形式D(NFC和NFD)使用每个字符的最大组合形式和最大分解形式,但不会尝试统一兼容等效序列。NFKC和NFKD规范化形式与NFC和NFD类似,但会将所有兼容等效序列规范化为它们所属类别的某个简单代表形式。
万维网联盟(World Wide Web Consortium)的《万维网字符模型》建议对所有内容使用NFC。Unicode标识符和模式语法附录建议在编程语言中对标识符使用NFKC,并在必要时提供调整形式的原则。
# unicode-normalization 库
Rust的unicode-normalization库提供了一个特性,为&str添加了方法,可将文本转换为四种规范化形式中的任意一种。要使用它,在你的Cargo.toml文件的[dependencies]部分添加以下内容:
unicode-normalization = "0.1.17"
有了这个声明后,&str有四个新方法,它们会返回字符串特定规范化形式的迭代器:
use unicode_normalization::UnicodeNormalization;
// 无论左边的字符串使用何种表示形式(仅通过查看你不应该能分辨出来),
// 这些断言都将成立。
assert_eq!("Phở"assert_eq!("① Di\u{fb03}culty".nfkc().collect::<String>(), "1
Difficulty");.nfd().collect::<String>(), "Pho\u{31b}\u{309}");
assert_eq!("Phở".nfc().collect::<String>(), "Ph\u{1edf}");
// 这里左边的字符串使用了“ffi”连字字符。
assert_eq!("@ Di\u{fb03}culty".nfkc().collect::<String>(), "1 Difficulty");
2
3
4
5
6
7
8
9
10
对一个规范化后的字符串再次以相同形式进行规范化,保证会返回相同的文本。
虽然规范化字符串的任何子串本身也是规范化的,但两个规范化字符串的连接不一定是规范化的:例如,第二个字符串可能以组合字符开头,而这些组合字符应该放在第一个字符串末尾的组合字符之前。
只要文本在规范化时不使用未分配的码点,Unicode保证其规范化形式在标准的未来版本中不会改变。这意味着规范化形式通常可以安全地用于持久存储,即使Unicode标准在不断发展。