 第18章 输入与输出
第18章 输入与输出
# 第18章 输入与输出
杜利特尔:你有什么确凿的证据证明你存在呢? 炸弹20号:嗯…… 这个嘛…… 我思故我在。 杜利特尔:说得好,非常好。但你怎么知道其他事物是存在的呢? 炸弹20号:我的感官系统告诉我的。 ——《暗星》
Rust标准库的输入输出功能围绕Read、BufRead和Write这三个特性展开:
- 实现
Read的类型,具备面向字节的输入方法,这类值被称为读取器(reader)。 - 实现
BufRead的是缓冲读取器,它们不仅支持Read的所有方法,还提供了读取文本行等方法。 - 实现
Write的类型支持面向字节和UTF-8文本的输出,这类值被称为写入器(writer)。
图18-1展示了这三个特性,以及一些读取器和写入器类型的示例。
在本章中,我们将解释如何使用这些特性及其方法,介绍图中所示的读取器和写入器类型,并展示与文件、终端和网络进行交互的其他方式。
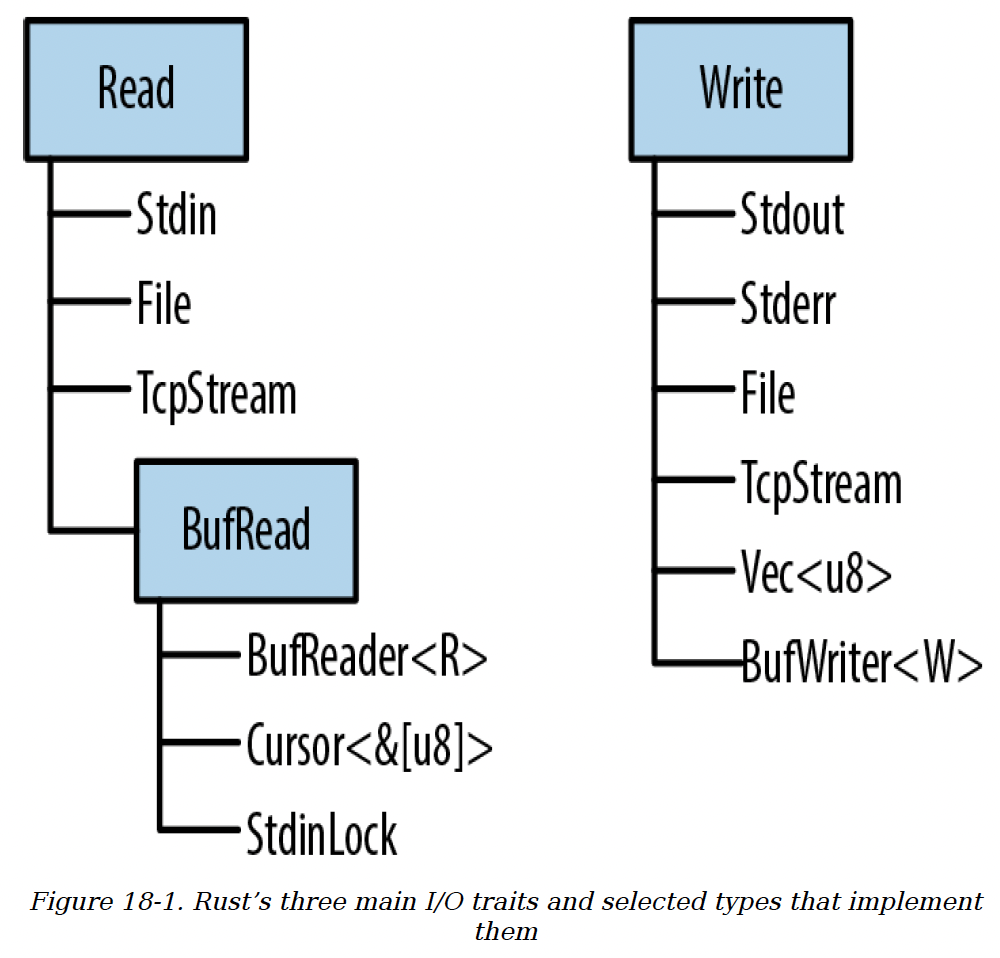 图18-1. Rust的三个主要I/O特性及实现它们的部分类型
图18-1. Rust的三个主要I/O特性及实现它们的部分类型
# 读取器和写入器
读取器是程序可以从中读取字节的对象,例如:
- 使用
std::fs::File::open(filename)打开的文件。 std::net::TcpStreams,用于通过网络接收数据。std::io::stdin(),用于从进程的标准输入流读取数据。std::io::Cursor<&[u8]>和std::io::Cursor<Vec<u8>>,这些读取器从已经存在于内存中的字节数组或向量中 “读取” 数据。
写入器是程序可以向其中写入字节的对象,例如:
- 使用
std::fs::File::create(filename)打开的文件。 std::net::TcpStreams,用于通过网络发送数据。std::io::stdout()和std::io::stderr(),用于写入终端。Vec<u8>,其写入方法会将数据追加到向量中。std::io::Cursor<Vec<u8>>,它与Vec<u8>类似,但既可以读取数据,也可以写入数据,还能在向量内的不同位置进行定位。std::io::Cursor<&mut [u8]>,它与std::io::Cursor<Vec<u8>>非常相似,不过它无法扩展缓冲区,因为它只是现有字节数组的一个切片。
由于读取器和写入器都有标准特性(std::io::Read和std::io::Write),编写适用于各种输入或输出通道的泛型代码非常常见。例如,下面这个函数可以将任何读取器中的所有字节复制到任何写入器中:
use std::io::{self, Read, Write, ErrorKind};
const DEFAULT_BUF_SIZE: usize = 8 * 1024;
pub fn copy<R: ?Sized, W: ?Sized>(reader: &mut R, writer: &mut W) -> io::Result<u64>
where
R: Read,
W: Write {
let mut buf = [0; DEFAULT_BUF_SIZE];
let mut written = 0;
loop {
let len = match reader.read(&mut buf) {
Ok(0) => return Ok(written),
Ok(len) => len,
Err(ref e) if e.kind() == ErrorKind::Interrupted => continue,
Err(e) => return Err(e),
};
writer.write_all(&buf[..len])?;
written += len as u64;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这是Rust标准库中std::io::copy()的实现。由于它是泛型函数,你可以用它将数据从File复制到TcpStream,从标准输入Stdin复制到内存中的Vec<u8>等等。
如果这里的错误处理代码不太容易理解,可以回顾第7章。在接下来的内容中,我们会经常使用Result类型,掌握它的工作原理非常重要。
std::io的三个特性Read、BufRead和Write,以及Seek,使用非常频繁,因此有一个prelude模块专门包含这些特性:
use std::io::prelude::*;
在本章中你会多次看到这个导入语句。我们还习惯导入std::io模块本身:
use std::io::{self, Read, Write, ErrorKind};
这里的self关键字将io声明为std::io模块的别名。这样,std::io::Result和std::io::Error可以更简洁地写成io::Result和io::Error等等。
# 读取器
std::io::Read有几个用于读取数据的方法,所有这些方法都通过可变引用获取读取器本身。
reader.read(&mut buffer):从数据源读取一些字节,并将它们存储到给定的缓冲区中。buffer参数的类型是&mut [u8],这个方法最多读取buffer.len()个字节。返回类型是io::Result<u64>,它是Result<u64, io::Error>的类型别名。读取成功时,u64值表示读取的字节数,这个数字可能等于或小于buffer.len(),即使还有更多数据,这取决于数据源。Ok(0)表示没有更多输入可读。读取失败时,.read()返回Err(err),其中err是一个io::Error值。io::Error类型的值可以打印输出,方便查看;对于程序来说,它有一个.kind()方法,返回一个io::ErrorKind类型的错误代码。这个枚举的成员名称如PermissionDenied(权限被拒绝)和ConnectionReset(连接重置)等。大多数错误表示严重问题,不能忽视,但有一种错误需要特殊处理。io::ErrorKind::Interrupted对应于Unix错误代码EINTR,表示读取操作被信号中断。除非程序设计为能巧妙处理信号,否则应该重试读取操作。上一节中copy()函数的代码展示了这种处理方式的示例。可以看出,.read()方法非常底层,甚至继承了底层操作系统的一些特性。如果你要为一种新的数据源类型实现Read特性,这会给你很大的发挥空间。但如果你只是想读取一些数据,这个方法会有点麻烦。因此,Rust提供了几个更高级的便捷方法,它们都基于.read()方法给出了默认实现,并且都处理了ErrorKind::Interrupted错误,所以你无需自己处理。reader.read_to_end(&mut byte_vec):从这个读取器读取所有剩余输入,并将其追加到byte_vec中,byte_vec是一个Vec<u8>。返回一个io::Result<usize>,表示读取的字节数。这个方法对堆积到向量中的数据量没有限制,所以不要在不可信的数据源上使用它。(你可以使用下一项中描述的.take()方法来限制读取量。)reader.read_to_string(&mut string):与read_to_end类似,但将数据追加到给定的String中。如果流中的数据不是有效的UTF-8编码,这个方法会返回一个ErrorKind::InvalidData错误。在一些编程语言中,字节输入和字符输入由不同类型处理。如今,UTF-8占据主导地位,Rust认可这一事实标准,并在各处都支持UTF-8。其他字符集可以通过开源的encoding库来支持。reader.read_exact(&mut buf):读取刚好足够的数据来填满给定的缓冲区,参数类型是&[u8]。如果在读取buf.len()个字节之前读取器就没有数据了,这个方法会返回一个ErrorKind::UnexpectedEof错误。
这些是Read特性的主要方法。此外,还有三个适配器方法,它们按值获取读取器,并将其转换为迭代器或不同类型的读取器:
reader.bytes():返回一个遍历输入流字节的迭代器,迭代器的元素类型是io::Result<u8>,所以每次读取字节时都需要进行错误检查。此外,这个方法每次读取一个字节时都会调用reader.read(),如果读取器没有缓冲,效率会非常低。reader.chain(reader2):返回一个新的读取器,它先产生reader的所有输入,然后是reader2的所有输入。reader.take(n):返回一个新的读取器,它与reader从相同的数据源读取数据,但最多只读取n个字节。
没有用于关闭读取器的方法。读取器和写入器通常实现了Drop特性,这样它们会自动关闭。
# 缓冲读取器
为了提高效率,读取器和写入器可以进行缓冲处理,这意味着它们有一块内存(缓冲区),用于在内存中保存一些输入或输出数据。如图18-2所示,这样可以减少系统调用。在这个例子中,应用程序通过调用read_line()方法从BufReader读取数据,而BufReader则从操作系统以更大的数据块获取输入。
该图并非按比例绘制。实际上,BufReader缓冲区的默认大小是几千字节,因此一次系统读取操作可以满足数百次read_line()调用。这很重要,因为系统调用速度较慢。(如图所示,操作系统也有一个缓冲区,原因相同:系统调用速度慢,但从磁盘读取数据更慢。)
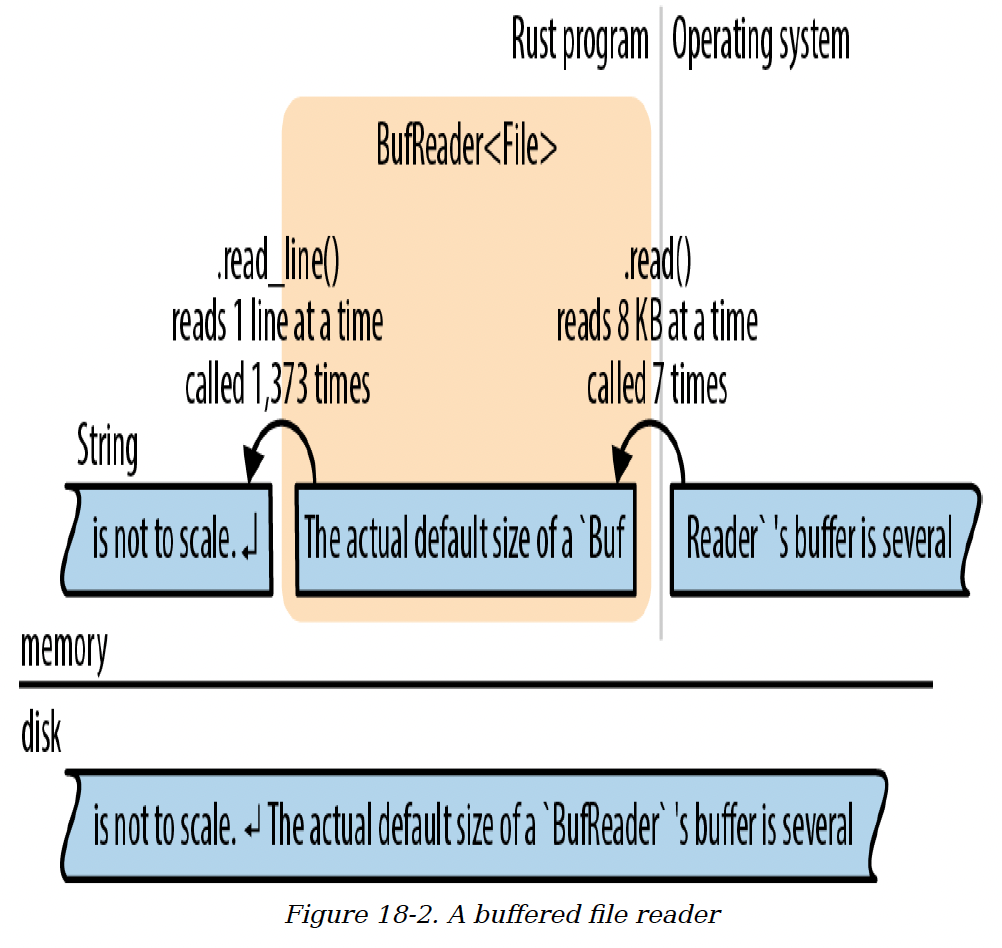 图18-2. 缓冲文件读取器
图18-2. 缓冲文件读取器
缓冲读取器同时实现了Read和另一个特性BufRead,BufRead添加了以下方法:
reader.read_line(&mut line):读取一行文本并将其追加到line中,line是一个String。行尾的换行符'\n'会包含在line中。如果输入的是Windows风格的行尾"\r\n",这两个字符都会包含在line中。返回值是io::Result<usize>,表示读取的字节数,包括行尾字符(如果有的话)。如果读取器已到达输入末尾,line不会被修改,且返回Ok(0)。reader.lines():返回一个遍历输入行的迭代器,迭代器元素类型是io::Result<String>,字符串中不包含换行符。如果输入的是Windows风格的行尾"\r\n",这两个字符都会被去除。对于文本输入,这个方法几乎总是你想要的。接下来的两个部分会展示一些使用示例。reader.read_until(stop_byte, &mut byte_vec)、reader.split(stop_byte):这两个方法与read_line()和lines()类似,但它们是面向字节的,生成的是Vec<u8>而不是String。你可以选择分隔字节stop_byte。
BufRead还提供了一对底层方法.fill_buf()和.consume(n),用于直接访问读取器的内部缓冲区。有关这些方法的更多信息,请查看在线文档。
接下来的两个部分将更详细地介绍缓冲读取器。
# 读取行
下面是一个实现Unix系统中grep工具功能的函数。它在多行文本中(通常是通过管道从另一个命令传入)搜索给定的字符串:
use std::io;
use std::io::prelude::*;
fn grep(target: &str) -> io::Result<()> {
let stdin = io::stdin();
for line_result in stdin.lock().lines() {
let line = line_result?;
if line.contains(target) {
println!("{}", line);
}
}
Ok(())
}
2
3
4
5
6
7
8
9
10
11
12
13
因为我们要调用.lines(),所以需要一个实现了BufRead的输入源。在这个例子中,我们调用io::stdin()来获取通过管道传入的数据。然而,Rust标准库使用互斥锁(mutex)来保护stdin。我们调用.lock()来锁定stdin,以供当前线程独占使用,它返回一个实现了BufRead的StdinLock值。循环结束时,StdinLock会被丢弃,释放互斥锁。(如果没有互斥锁,两个线程同时尝试从stdin读取数据会导致未定义行为。C语言也有同样的问题,并且解决方式相同:所有C标准输入输出函数在幕后都会获取一个锁。唯一的区别是在Rust中,锁是API的一部分。)
函数的其余部分很简单:它调用.lines()并遍历生成的迭代器。由于这个迭代器生成的是Result值,我们使用?操作符来检查错误。
假设我们想让grep程序更进一步,增加对搜索磁盘文件的支持。我们可以将这个函数泛型化:
fn grep<R>(target: &str, reader: R) -> io::Result<()>
where
R: BufRead
{
for line_result in reader.lines() {
let line = line_result?;
if line.contains(target) {
println!("{}", line);
}
}
Ok(())
}
2
3
4
5
6
7
8
9
10
11
12
现在我们既可以传入StdinLock,也可以传入缓冲的File:
let stdin = io::stdin();
grep(&target, stdin.lock())?; // 可行
let f = File::open(file)?;
grep(&target, BufReader::new(f))?; // 也可行
2
3
4
注意,File不会自动进行缓冲。File实现了Read,但没有实现BufRead。不过,为File或任何其他未缓冲的读取器创建一个缓冲读取器很容易,BufReader::new(reader)就可以做到。(如果要设置缓冲区的大小,可以使用BufReader::with_capacity(size, reader)。)
在大多数语言中,文件默认是缓冲的。如果你想要无缓冲的输入或输出,必须想办法关闭缓冲。在Rust中,File和BufReader是两个独立的库特性,因为有时你可能需要无缓冲的文件,有时又可能需要不基于文件的缓冲(例如,你可能希望对网络输入进行缓冲)。
下面是完整的程序,包括错误处理和一些简单的参数解析:
// grep - Search stdin or some files for lines matching a given string.
use std::error::Error;
use std::io::{self, BufReader};
use std::io::prelude::*;
use std::fs::File;
use std::path::PathBuf;
fn grep<R>(target: &str, reader: R) -> io::Result<()>
where
R: BufRead
{
for line_result in reader.lines() {
let line = line_result?;
if line.contains(target) {
println!("{}", line);
}
}
Ok(())
}
fn grep_main() -> Result<(), Box<dyn Error>> {
// 获取命令行参数。第一个参数是要搜索的字符串;其余的是文件名。
let mut args = std::env::args().skip(1);
let target = match args.next() {
Some(s) => s,
None => Err("usage: grep PATTERN FILE...")?,
};
let files: Vec<PathBuf> = args.map(PathBuf::from).collect();
if files.is_empty() {
let stdin = io::stdin();
grep(&target, stdin.lock())?;
} else {
for file in files {
let f = File::open(file)?;
grep(&target, BufReader::new(f))?;
}
}
Ok(())
}
fn main() {
let result = grep_main();
if let Err(err) = result {
eprintln!("{}", err);
std::process::exit(1);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 收集行
包括.lines()在内的几个读取器方法,返回的迭代器会生成Result值。当你第一次想要将文件的所有行收集到一个大向量中时,会遇到如何处理这些Result值的问题:
// 可行,但不是我们想要的结果
let results: Vec<io::Result<String>> = reader.lines().collect();
// 错误: 无法将Result集合转换为Vec<String>
let lines: Vec<String> = reader.lines().collect();
2
3
4
第二次尝试无法编译通过:因为错误该如何处理呢?直接的解决方法是编写一个for循环,并检查每个项是否有错误:
let mut lines = vec![];
for line_result in reader.lines() {
lines.push(line_result?);
}
2
3
4
这样写还不错,但如果能在这里使用.collect()就更好了,实际上我们是可以做到的。我们只需要知道要指定什么类型:
let lines = reader.lines().collect::<io::Result<Vec<String>>>()?;
这是如何实现的呢?标准库中包含了针对Result的FromIterator实现(在在线文档中很容易被忽略),这使得上述操作成为可能:
impl<T, E, C> FromIterator<Result<T, E>> for Result<C, E>
where
C: FromIterator<T>
{
...
}
2
3
4
5
6
这需要仔细理解,但它是个很巧妙的方法。假设C是任何集合类型,比如Vec或HashSet。只要我们已经知道如何从T值的迭代器构建一个C,那么我们就可以从生成Result<T, E>值的迭代器构建一个Result<C, E>。我们只需要从迭代器中获取值,并从Ok结果构建集合,但如果遇到Err,则停止并返回该错误。
换句话说,io::Result<Vec<String>>是一个集合类型,所以.collect()方法可以创建并填充该类型的值。
# 写入器
如我们所见,输入操作主要通过方法来完成。而输出操作则略有不同。
在本书中,我们一直在使用println!()来生成纯文本输出:
println!("Hello, world!");
println!("The greatest common divisor of {:?} is {}", numbers, d);
println!(); // 打印一个空行
2
3
还有一个print!()宏,它不会在末尾添加换行符,另外eprintln!和eprint!宏用于写入标准错误流。所有这些宏的格式化代码与“格式化值”中描述的format!宏的格式化代码相同。
要将输出发送到写入器,可使用write!()和writeln!()宏。它们与print!()和println!()类似,但有两个区别:
writeln!(io::stderr(), "error: world not helloable")?;
writeln!(&mut byte_vec, "The greatest common divisor of {:?} is {}", numbers, d)?;
2
一个区别是,写入宏都多了一个第一个参数,即写入器。另一个区别是,它们返回一个Result,因此必须处理错误。这就是为什么我们在每行的末尾使用了?操作符。
打印宏不会返回Result;如果写入失败,它们会直接引发恐慌(panic)。由于它们写入的是终端,这种情况很少见。
Write特性有以下这些方法:
writer.write(&buf):将切片buf中的一些字节写入底层流。它返回一个io::Result<usize>。成功时,返回写入的字节数,这个数字可能小于buf.len(),具体取决于流的情况。与Reader::read()一样,这是一个底层方法,你应避免直接使用。writer.write_all(&buf):写入切片buf中的所有字节。返回Result<()>。writer.flush():将任何缓冲的数据刷新到底层流。返回Result<()>。
注意,虽然println!和eprintln!宏会自动刷新标准输出和标准错误流,但print!和eprint!宏不会。在使用它们时,你可能需要手动调用flush()。
与读取器一样,写入器在被丢弃时会自动关闭。
就像BufReader::new(reader)为任何读取器添加缓冲区一样,BufWriter::new(writer)为任何写入器添加缓冲区:
let file = File::create("tmp.txt")?;
let writer = BufWriter::new(file);
2
如果要设置缓冲区的大小,可以使用BufWriter::with_capacity(size, writer)。
当BufWriter被丢弃时,所有剩余的缓冲数据都会被写入底层写入器。然而,如果在写入过程中发生错误,该错误将被忽略。(由于这发生在BufWriter的.drop()方法内部,没有合适的地方来报告错误。)为确保你的应用程序能注意到所有输出错误,在丢弃缓冲写入器之前,应手动调用.flush()。
# 文件
我们已经见过两种打开文件的方式:
File::open(filename):打开一个现有文件用于读取。它返回一个io::Result<File>,如果文件不存在则会报错。File::create(filename):创建一个新文件用于写入。如果具有给定文件名的文件已存在,则会将其截断。
注意,File类型位于文件系统模块std::fs中,而不是std::io中。
当这两种方式都不满足需求时,你可以使用OpenOptions来指定所需的精确行为:
use std::fs::OpenOptions;
let log = OpenOptions::new()
.append(true) // 如果文件存在,追加到文件末尾
.open("server.log")?;
let file = OpenOptions::new()
.write(true)
.create_new(true) // 如果文件已存在则失败
.open("new_file.txt")?;
2
3
4
5
6
7
8
9
10
.append()、.write()、.create_new()等方法设计为可以像这样链式调用:每个方法都返回self。这种方法链式调用的设计模式在Rust中很常见,它有一个名字:构建器(builder)模式。std::process::Command是另一个例子。有关OpenOptions的更多详细信息,请查看在线文档。
一旦文件被打开,它的行为就和其他读取器或写入器一样。如果需要,你可以为其添加缓冲区。当你丢弃File时,它会自动关闭。
# 定位
File还实现了Seek特性,这意味着你可以在文件中随意跳转,而不必从头到尾一次性读取或写入。Seek的定义如下:
pub trait Seek {
fn seek(&mut self, pos: SeekFrom) -> io::Result<u64>;
}
pub enum SeekFrom {
Start(u64),
End(i64),
Current(i64)
}
2
3
4
5
6
7
8
9
借助这个枚举,seek方法的表达能力很强:使用file.seek(SeekFrom::Start(0))可以将文件指针移到开头,使用file.seek(SeekFrom::Current(-8))可以向后移动几个字节,依此类推。
在文件中定位操作速度较慢。无论你使用的是硬盘还是固态硬盘(SSD),一次定位操作所花费的时间与读取几兆字节数据的时间差不多。
# 其他读取器和写入器类型
到目前为止,本章一直以File为例进行讲解,但还有许多其他有用的读取器和写入器类型:
io::stdin():返回标准输入流的读取器,其类型为io::Stdin。由于它由所有线程共享,每次读取都需要获取和释放一个互斥锁。Stdin有一个.lock()方法,用于获取互斥锁并返回一个io::StdinLock,这是一个缓冲读取器,它会持有互斥锁直到被丢弃。因此,对StdinLock的单个操作可以避免互斥锁带来的开销。我们在“读取行”中展示了使用此方法的示例代码。由于技术原因,io::stdin().lock()不能直接使用。锁持有对Stdin值的引用,这意味着Stdin值必须存储在某个地方,以确保其生命周期足够长:
let stdin = io::stdin();
let lines = stdin.lock().lines(); // 可行
2
io::stdout()、io::stderr():返回标准输出和标准错误流的Stdout和Stderr写入器类型。它们也有互斥锁和.lock()方法。Vec<u8>:实现了Write。向Vec<u8>写入数据会将新数据追加到向量中。(然而,String没有实现Write。要使用Write构建字符串,首先写入Vec<u8>,然后使用String::from_utf8(vec)将向量转换为字符串。)Cursor::new(buf):创建一个Cursor,这是一个从buf读取数据的缓冲读取器。这是创建一个从String读取数据的读取器的方式。参数buf可以是任何实现了AsRef<[u8]>的类型,所以你也可以传入&[u8]、&str或Vec<u8>。Cursor的内部结构很简单。它只有两个字段:buf本身和一个整数,表示下一次读取将在buf中的偏移量。初始位置为0。Cursor实现了Read、BufRead和Seek。如果buf的类型是&mut [u8]或Vec<u8>,那么Cursor还实现了Write。向Cursor写入数据会从当前位置开始覆盖buf中的字节。如果你尝试在&mut [u8]的末尾之后写入数据,可能会得到部分写入结果或一个io::Error错误。不过,使用Cursor在Vec<u8>的末尾之后写入数据是没问题的:它会扩展向量。因此,Cursor<&mut [u8]>和Cursor<Vec<u8>>实现了std::io::prelude中的所有四个特性。std::net::TcpStream:表示一个TCP网络连接。由于TCP支持双向通信,它既是读取器也是写入器。类型关联函数TcpStream::connect(("hostname", PORT))尝试连接到服务器,并返回一个io::Result<TcpStream>。std::process::Command:支持生成一个子进程,并将数据通过管道传输到其标准输入,如下所示:
use std::process::{Command, Stdio};
let mut child =
Command::new("grep")
.arg("-e")
.arg("a.*e.*i.*o.*u")
.stdin(Stdio::piped())
.spawn()?;
let mut to_child = child.stdin.take().unwrap();
for word in my_words {
writeln!(to_child, "{}", word)?;
}
drop(to_child); // 关闭grep的标准输入,使其退出
child.wait()?;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
child.stdin的类型是Option<std::process::ChildStdin>;在这里,我们在设置子进程时使用了.stdin(Stdio::piped()),所以当.spawn()成功时,child.stdin肯定是有值的。如果我们没有这样做,child.stdin将为None。Command还有类似的方法.stdout()和.stderr(),可用于在child.stdout和child.stderr中请求读取器。
std::io模块还提供了一些返回简单读取器和写入器的函数:
io::sink():这是一个空操作写入器。所有写入方法都返回Ok,但数据会被直接丢弃。io::empty():这是一个空操作读取器。读取总是成功,但返回输入结束标志。io::repeat(byte):返回一个读取器,它会不断重复给定的字节。
# 二进制数据、压缩和序列化
许多开源库都基于std::io框架提供额外的功能。
byteorder库提供了ReadBytesExt和WriteBytesExt特性,为所有读取器和写入器添加了用于二进制输入和输出的方法:
use byteorder::{ReadBytesExt, WriteBytesExt, LittleEndian};
let n = reader.read_u32::<LittleEndian>()?;
writer.write_i64::<LittleEndian>(n as i64)?;
2
3
4
flate2库提供了用于读取和写入gzip压缩数据的适配方法:
use flate2::read::GzDecoder;
let file = File::open("access.log.gz")?;
let mut gzip_reader = GzDecoder::new(file);
2
3
4
serde库及其相关的格式库(如serde_json)实现了序列化和反序列化功能:它们在Rust结构体和字节之间进行转换。我们之前在 “特性与他人的类型” 中提到过这个库。现在我们可以更深入地了解一下。
假设我们有一些数据,比如一个文本冒险游戏的地图,存储在HashMap中:
type RoomId = String; // 每个房间都有一个唯一的名称
type RoomExits = Vec<(char, RoomId)>; // ...以及一个出口列表
type RoomMap = HashMap<RoomId, RoomExits>; // 房间名称和出口,很简单
// 创建一个简单的地图
let mut map = RoomMap::new();
map.insert("Cobble Crawl".to_string(),
vec![('W', "Debris Room".to_string())]);
map.insert("Debris Room".to_string(),
vec![('E', "Cobble Crawl".to_string()),
('W', "Sloping Canyon".to_string())]);
...
2
3
4
5
6
7
8
9
10
11
12
将这些数据转换为JSON格式进行输出只需要一行代码:
serde_json::to_writer(&mut std::io::stdout(), &map)?;
在内部,serde_json::to_writer使用了serde::Serialize特性的serialize方法。该库为所有它知道如何序列化的类型附加了这个特性,这包括我们数据中出现的所有类型:字符串、字符、元组、向量和HashMap。
serde非常灵活。在这个程序中,输出是JSON数据,因为我们选择了serde_json序列化器。其他格式,如MessagePack,也同样可用。同样,你可以将这个输出发送到文件、Vec<u8>或任何其他写入器。前面的代码将数据打印到标准输出。输出如下:
{"Debris Room":[["E","Cobble Crawl"],["W","Sloping Canyon"]],"Cobble Crawl":[["W","Debris Room"]]}
serde还支持派生两个关键的serde特性:
#[derive(Serialize, Deserialize)]
struct Player {
location: String,
items: Vec<String>,
health: u32
}
2
3
4
5
6
这个#[derive]属性可能会使编译时间稍长一些,所以当你在Cargo.toml文件中将serde列为依赖项时,需要显式请求它支持这个功能。以下是我们在前面代码中使用的依赖配置:
[dependencies]
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
2
3
更多详细信息请查看serde的文档。简而言之,构建系统会为Player自动生成serde::Serialize和serde::Deserialize的实现,这样序列化一个Player值就很简单:
serde_json::to_writer(&mut std::io::stdout(), &player)?;
输出如下:
{"location":"Cobble Crawl","items":["a wand"],"health":3}
# 文件和目录
既然我们已经介绍了如何使用读取器和写入器,接下来的几个部分将介绍Rust中用于处理文件和目录的功能,这些功能位于std::path和std::fs模块中。所有这些功能都涉及到文件名的处理,所以我们先从文件名类型开始介绍。
# OsStr和Path
不方便的是,操作系统并不强制要求文件名是有效的Unicode。下面是两个在Linux shell中创建文本文件的命令。只有第一个命令使用了有效的UTF-8文件名:
$ echo "hello world" > ô.txt
$ echo "O brave new world, that has such filenames in't" > $'\xf4'.txt
2
这两个命令都能顺利执行,因为Linux内核无法区分UTF-8和Ogg Vorbis格式。在内核看来,任何字节串(不包括空字节和斜杠)都是可接受的文件名。在Windows上情况类似:几乎任何16位 “宽字符” 字符串都是可接受的文件名,即使这些字符串不是有效的UTF-16。
操作系统处理的其他字符串,如命令行参数和环境变量,也是如此。
Rust字符串始终是有效的Unicode。实际上,文件名大多是Unicode,但Rust必须处理极少数不是Unicode的情况。这就是为什么Rust有std::ffi::OsStr和OsString类型。
OsStr是一种字符串类型,是UTF-8的超集。它的作用是能够表示当前系统上的所有文件名、命令行参数和环境变量,无论它们是否是有效的Unicode。在Unix系统上,OsStr可以保存任何字节序列。在Windows上,OsStr使用一种UTF-8的扩展形式存储,这种扩展形式可以编码任何16位值序列,包括不匹配的代理项对。
所以我们有两种字符串类型:str用于表示实际的Unicode字符串;OsStr用于表示操作系统可能提供的任何内容(不管是不是合法的Unicode)。我们再介绍一种:std::path::Path,用于表示文件名。这纯粹是为了方便。Path与OsStr完全一样,但它添加了许多与文件名相关的便捷方法,我们将在下一节介绍这些方法。绝对路径和相对路径都使用Path。对于路径的单个组件,则使用OsStr。
最后,对于每种字符串类型,都有一个对应的拥有所有权的类型:String拥有一个在堆上分配的str;std::ffi::OsString拥有一个在堆上分配的OsStr;std::path::PathBuf拥有一个在堆上分配的Path。表18-1概述了每种类型的一些特性。
表18-1. 文件名类型
str | OsStr | Path | |
|---|---|---|---|
| 未 Sized 类型,总是通过引用传递 | 是 | 是 | 是 |
| 可以包含任何Unicode文本 | 是 | 是 | 是 |
| 通常看起来就像UTF-8 | 是 | 是 | 是 |
| 可以包含非Unicode数据 | 否 | 是 | 是 |
| 文本处理方法 | 是 | 否 | 否 |
| 与文件名相关的方法 | 否 | 否 | 是 |
| 拥有所有权、可增长、在堆上分配的等效类型 | String | OsString | PathBuf |
| 转换为拥有所有权的类型 | .to_string() | .to_os_string() | .to_path_buf() |
这三种类型都实现了一个公共特性AsRef<Path>,所以我们可以轻松声明一个泛型函数,接受 “任何文件名类型” 作为参数。这使用了我们在 “AsRef和AsMut” 中展示的技术:
use std::path::Path;
use std::io;
fn swizzle_file<P>(path_arg: P) -> io::Result<()>
where
P: AsRef<Path>
{
let path = path_arg.as_ref();
...
}
2
3
4
5
6
7
8
9
10
所有接受路径参数的标准函数和方法都使用了这种技术,所以你可以随意将字符串字面量传递给它们中的任何一个。
# Path和PathBuf方法
Path提供了以下方法,以及其他一些方法:
Path::new(str):将&str或&OsStr转换为&Path。这不会复制字符串。新的&Path指向与原始&str或&OsStr相同的字节:
use std::path::Path;
let home_dir = Path::new("/home/fwolfe");
2
3
(类似的方法OsStr::new(str)将&str转换为&OsStr。)
path.parent():返回路径的父目录(如果有的话)。返回类型是Option<&Path>。这不会复制路径。路径的父目录始终是路径的子串:
assert_eq!(Path::new("/home/fwolfe/program.txt").parent(),
Some(Path::new("/home/fwolfe")));
2
path.file_name():返回路径的最后一个组件(如果有的话)。返回类型是Option<&OsStr>。在通常情况下,路径由目录、斜杠和文件名组成,这个方法会返回文件名:
use std::ffi::OsStr;
assert_eq!(Path::new("/home/fwolfe/program.txt").file_name(),
Some(OsStr::new("program.txt")));
2
3
4
path.is_absolute()、path.is_relative():这些方法用于判断文件路径是绝对路径(如Unix路径/usr/bin/advent或Windows路径C:\Program Files)还是相对路径(如src/main.rs)。path1.join(path2):连接两个路径,返回一个新的PathBuf:
let path1 = Path::new("/usr/share/dict");
assert_eq!(path1.join("words"),
Path::new("/usr/share/dict/words"));
2
3
如果path2是绝对路径,这个方法只会返回path2的副本,所以这个方法可以用于将任何路径转换为绝对路径:
let abs_path = std::env::current_dir()?.join(any_path);
path.components():返回一个遍历给定路径组件的迭代器,从左到右。这个迭代器的元素类型是std::path::Component,这是一个枚举,它可以表示文件名中可能出现的所有不同部分:
pub enum Component<'a> {
Prefix(PrefixComponent<'a>), // 在Windows上,代表驱动器盘符或共享名
RootDir, // 根目录,Unix上是`/`,Windows上是`\`
CurDir, // 特殊目录`.`
ParentDir, // 特殊目录`..`
Normal(&'a OsStr) // 普通的文件和目录名
}
2
3
4
5
6
7
例如,Windows路径\\venice\Music\A Love Supreme\04-Psalm.mp3由一个代表\\venice\Music的Prefix、一个RootDir,然后是两个代表A Love Supreme和04-Psalm.mp3的Normal组件组成。更多详细信息,请查看在线文档。
path.ancestors():返回一个从路径向上遍历到根目录的迭代器。生成的每个元素都是一个Path:首先是路径本身,然后是它的父目录,再然后是它的祖父目录,依此类推:
let file = Path::new("/home/jimb/calendars/calendar-18x18.pdf");
assert_eq!(file.ancestors().collect::<Vec<_>>(),
vec![Path::new("/home/jimb/calendars/calendar-18x18.pdf"),
Path::new("/home/jimb/calendars"),
Path::new("/home/jimb"),
Path::new("/home"),
Path::new("/")]);
2
3
4
5
6
7
这与反复调用parent直到返回None非常相似。最后一个元素始终是根路径或前缀路径。
这些方法在内存中的字符串上操作。路径还有一些用于查询文件系统的方法,如.exists()、.is_file()、.is_dir()、.read_dir()、.canonicalize()等等。更多信息请查看在线文档。
有三种将Path转换为字符串的方法。每种方法都考虑到了路径中可能存在无效UTF-8的情况:
path.to_str():将Path转换为字符串,返回Option<&str>。如果路径不是有效的UTF-8,这个方法返回None:
if let Some(file_str) = path.to_str() {
println!("{}", file_str);
} // ...否则跳过这个名字奇怪的文件
2
3
path.to_string_lossy():这个方法基本与to_str相同,但在所有情况下都能返回某种字符串。如果路径不是有效的UTF-8,这些方法会进行复制,用Unicode替换字符U+FFFD(�)替换每个无效的字节序列。返回类型是std::borrow::Cow<str>:一种要么是借用的,要么是拥有所有权的字符串。要从这个值获取String,可以使用它的.to_owned()方法。(关于Cow的更多信息,请参见 “借用和ToOwned的应用:不起眼的Cow”。)path.display():这个方法用于打印路径:
println!("Download found. You put it in: {}", dir_path.display());
这个方法返回的值不是字符串,但它实现了std::fmt::Display,所以可以与format!()、println!()等宏一起使用。如果路径不是有效的UTF-8,输出中可能会包含�字符。
# 文件系统访问函数
表18-2展示了std::fs中的一些函数,以及它们在Unix和Windows上大致等效的命令。所有这些函数都返回io::Result值。除非另有说明,它们的返回类型是Result<()>。
表18-2. 文件系统访问函数概述
| Rust函数 | Unix | Windows |
|---|---|---|
create_dir(path) | mkdir() | CreateDirectory() |
create_dir_all(path) | 类似mkdir -p | 类似mkdir |
remove_dir(path) | rmdir() | RemoveDirectory() |
remove_dir_all(path) | 类似rm -r | 类似rmdir /s |
remove_file(path) | unlink() | DeleteFile() |
copy(src_path, dest_path) -> Result<u64> | 类似cp -p | CopyFileEx() |
rename(src_path, dest_path) | rename() | MoveFileEx() |
hard_link(src_path, dest_path) | link() | CreateHardLink() |
canonicalize(path) -> Result<PathBuf> | realpath() | GetFinalPathNameByHandle() |
metadata(path) -> Result<Metadata> | stat() | GetFileInformationByHandle() |
symlink_metadata(path) -> Result<Metadata> | lstat() | GetFileInformationByHandle() |
read_dir(path) -> Result<ReadDir> | opendir() | FindFirstFile() |
read_link(path) -> Result<PathBuf> | readlink() | FSCTL_GET_REPARSE_POINT |
set_permissions(path, perm) | chmod() | SetFileAttributes() |
(copy()返回的数字是复制文件的大小,以字节为单位。关于创建符号链接,请参见 “特定平台的特性”。)
如你所见,Rust致力于提供可移植的函数,这些函数在Windows、macOS、Linux和其他Unix系统上都能按预期工作。
关于文件系统的完整教程超出了本书的范围,但如果你对这些函数中的任何一个感到好奇,可以很容易在网上找到更多相关信息。我们将在下一节展示一些示例。
所有这些函数都是通过调用操作系统的功能来实现的。例如,std::fs::canonicalize(path)不仅仅是通过字符串处理来消除给定路径中的.和..。它会使用当前工作目录来解析相对路径,并且会跟踪符号链接。如果路径不存在,这是一个错误。
std::fs::metadata(path)和std::fs::symlink_metadata(path)返回的Metadata类型包含文件类型、大小、权限和时间戳等信息。一如既往,详细信息请查阅文档。
为了方便起见,Path类型内置了其中一些函数作为方法:例如,path.metadata()与std::fs::metadata(path)是一样的。
# 读取目录
要列出目录的内容,可以使用std::fs::read_dir,或者等效地使用Path的.read_dir()方法:
for entry_result in path.read_dir()? {
let entry = entry_result?;
println!("{}", entry.file_name().to_string_lossy());
}
2
3
4
注意这段代码中两次使用了?。第一行用于检查打开目录时是否出错。第二行用于检查读取下一个目录项时是否出错。
entry的类型是std::fs::DirEntry,它是一个结构体,只有几个方法:
entry.file_name():文件或目录的名称,类型为OsString。entry.path():与file_name()返回的内容相同,但会将原始路径与之拼接,生成一个新的PathBuf。如果我们列出的目录是/home/jimb,而entry.file_name()是.emacs,那么entry.path()将返回PathBuf::from("/home/jimb/.emacs")。entry.file_type():返回一个io::Result<FileType>。FileType有.is_file()、.is_dir()和.is_symlink()方法。entry.metadata():获取关于此目录项的其余元数据。
在读取目录时,特殊目录.和..不会列出。
下面是一个更具体的示例。以下代码将磁盘上的一个目录树递归地复制到另一个位置:
use std::fs;
use std::io;
use std::path::Path;
/// 将现有的目录`src`复制到目标路径`dst`。
fn copy_dir_to(src: &Path, dst: &Path) -> io::Result<()> {
if!dst.is_dir() {
fs::create_dir(dst)?;
}
for entry_result in src.read_dir()? {
let entry = entry_result?;
let file_type = entry.file_type()?;
copy_to(&entry.path(), &file_type, &dst.join(entry.file_name()))?;
}
Ok(())
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
一个单独的函数copy_to用于复制单个目录项:
/// 将`src`处的内容复制到目标路径`dst`。
fn copy_to(src: &Path, src_type: &fs::FileType, dst: &Path) -> io::Result<()> {
if src_type.is_file() {
fs::copy(src, dst)?;
} else if src_type.is_dir() {
copy_dir_to(src, dst)?;
} else {
return Err(io::Error::new(io::ErrorKind::Other,
format!("don't know how to copy: {}",
src.display())));
}
Ok(())
}
2
3
4
5
6
7
8
9
10
11
12
13
# 特定平台的特性
到目前为止,我们的copy_to函数可以复制文件和目录。假设我们还想在Unix系统上支持符号链接。目前没有一种可移植的方法能创建在Unix和Windows上都能工作的符号链接,但标准库提供了一个特定于Unix的symlink函数:
use std::os::unix::fs::symlink;
有了这个函数,我们的工作就简单了。我们只需要在copy_to函数的if表达式中添加一个分支:
...
} else if src_type.is_symlink() {
let target = src.read_link()?;
symlink(target, dst)?;
...
2
3
4
5
只要我们只针对Unix系统(如Linux和macOS)编译程序,这段代码就能正常工作。
std::os模块包含各种特定于平台的特性,比如symlink。标准库中std::os的实际内容大致如下(这里做了一些简化):
//! 特定于操作系统的功能。
#[cfg(unix)]
pub mod unix;
#[cfg(windows)]
pub mod windows;
#[cfg(target_os == "ios")]
pub mod ios;
#[cfg(target_os == "linux")]
pub mod linux;
#[cfg(target_os == "macos")]
pub mod macos;
2
3
4
5
6
7
8
9
10
11
#[cfg]属性表示条件编译:这些模块中的每一个都只存在于某些平台上。这就是为什么我们使用std::os::unix的修改后的程序只能在Unix系统上成功编译:在其他平台上,std::os::unix并不存在。
如果我们希望代码在所有平台上都能编译,并且在Unix系统上支持符号链接,那么我们也必须在程序中使用#[cfg]。在这种情况下,最简单的方法是在Unix系统上导入symlink,而在其他系统上定义我们自己的symlink占位函数:
#[cfg(unix)]
use std::os::unix::fs::symlink;
/// 为不提供`symlink`函数的平台定义的占位实现。
#[cfg(not(unix))]
fn symlink<P: AsRef<Path>, Q: AsRef<Path>>(src: P, _dst: Q) -> std::io::Result<()> {
Err(io::Error::new(io::ErrorKind::Other,
format!("can't copy symbolic link: {}",
src.as_ref().display())))
}
2
3
4
5
6
7
8
9
10
事实证明,symlink有点特殊。大多数特定于Unix的特性并不是独立的函数,而是扩展特性,这些扩展特性为标准库类型添加了新方法。(我们在 “特性与他人的类型” 中介绍过扩展特性。)有一个prelude模块可以用来一次性启用所有这些扩展:
use std::os::unix::prelude::*;
例如,在Unix系统上,这会为std::fs::Permissions添加一个.mode()方法,用于访问Unix上表示权限的底层u32值。类似地,它为std::fs::Metadata扩展了访问底层struct stat值字段的访问器,比如.uid(),用于获取文件所有者的用户ID。
总的来说,std::os中的内容相当基础。通过第三方库可以获得更多特定于平台的功能,比如用于访问Windows注册表的winreg库。
# 网络编程
网络编程的教程远远超出了本书的范围。不过,如果你已经对网络编程有一些了解,本节内容将帮助你在Rust中开始进行网络编程。
对于底层网络代码,可以从std::net模块入手,它为TCP和UDP网络提供跨平台支持。可以使用native_tls库来支持SSL/TLS。
这些模块提供了通过网络进行简单的阻塞式输入和输出的基础组件。你可以用几行代码编写一个简单的服务器,使用std::net并为每个连接生成一个线程。例如,下面是一个 “回显” 服务器:
use std::net::TcpListener;
use std::io;
use std::thread::spawn;
/// 永远接受连接,为每个连接生成一个线程。
fn echo_main(addr: &str) -> io::Result<()> {
let listener = TcpListener::bind(addr)?;
println!("listening on {}", addr);
loop {
// 等待客户端连接。
let (mut stream, addr) = listener.accept()?;
println!("connection received from {}", addr);
// 生成一个线程来处理这个客户端。
let mut write_stream = stream.try_clone()?;
spawn(move || {
// 将从`stream`接收到的所有内容回显回去。
io::copy(&mut stream, &mut write_stream)
.expect("error in client thread: ");
println!("connection closed");
});
}
}
fn main() {
echo_main("127.0.0.1:17007").expect("error: ");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
回显服务器只是简单地将你发送给它的所有内容原样返回。这种代码与你在Java或Python中编写的代码并没有太大区别。(我们将在下一章介绍std::thread::spawn()。)
然而,对于高性能服务器,你需要使用异步输入和输出。第20章介绍了Rust对异步编程的支持,并展示了网络客户端和服务器的完整代码。
更高层的协议由第三方库提供支持。例如,reqwest库为HTTP客户端提供了出色的API。下面是一个完整的命令行程序,它可以获取任何具有http:或https: URL的文档,并将其输出到终端。这段代码使用的是reqwest = "0.11",并启用了其"blocking"特性。reqwest也提供了异步接口。
use std::error::Error;
use std::io;
fn http_get_main(url: &str) -> Result<(), Box<dyn Error>> {
// 发送HTTP请求并获取响应。
let mut response = reqwest::blocking::get(url)?;
if!response.status().is_success() {
Err(format!("{}", response.status()))?;
}
// 读取响应体并将其写入标准输出。
let stdout = io::stdout();
io::copy(&mut response, &mut stdout.lock())?;
Ok(())
}
fn main() {
let args: Vec<String> = std::env::args().collect();
if args.len() != 2 {
eprintln!("usage: http-get URL");
return;
}
if let Err(err) = http_get_main(&args[1]) {
eprintln!("error: {}", err);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
用于HTTP服务器的actix-web框架提供了一些高级特性,比如Service和Transform特性,这些特性帮助你通过可插拔的组件来组合应用程序。websocket库实现了WebSocket协议。诸如此类。Rust是一门年轻的语言,拥有活跃的开源生态系统。对网络编程的支持正在迅速扩展。