 第20章 异步编程
第20章 异步编程
# 第20章 异步编程
假设你正在编写一个聊天服务器。对于每个网络连接,都有传入的数据包需要解析、传出的数据包需要组装、安全参数需要管理、聊天群组订阅需要跟踪等等。要同时管理许多连接,需要进行一些规划。
理想情况下,你可以为每个传入连接启动一个单独的线程:
use std::{net, thread};
let listener = net::TcpListener::bind(address)?;
for socket_result in listener.incoming() {
let socket = socket_result?;
let groups = chat_group_table.clone();
thread::spawn(|| {
log_error(serve(socket, groups));
});
}
2
3
4
5
6
7
8
9
10
对于每个新连接,这段代码都会启动一个新线程来运行serve函数,该函数能够专注于管理单个连接的需求。
这种方法在一切进展顺利时都能很好地工作,直到用户数量突然增加到数万。一个线程的栈增长到100 KiB或更多并不罕见,而这可能不是你想要的服务器内存使用方式。线程对于在多个处理器之间分配工作很有用且必要,但它们对内存的需求较大,因此我们通常需要一些与线程配合使用的互补方式来分解工作。
你可以使用Rust异步任务在单个线程或一组工作线程上交错执行许多独立的活动。异步任务与线程类似,但创建速度更快,它们之间传递控制权的效率更高,并且内存开销比线程低一个数量级。在单个程序中同时运行数十万个异步任务是完全可行的。当然,你的应用程序可能仍然会受到其他因素的限制,如网络带宽、数据库速度、计算能力或工作本身的内存需求,但使用任务所带来的内存开销比线程小得多。
一般来说,Rust异步代码看起来与普通的多线程代码非常相似,只是可能会阻塞的操作(如I/O或获取互斥锁)需要以稍微不同的方式处理。对这些操作进行特殊处理可以让Rust更多地了解你的代码行为,这也是实现性能提升的原因。前面代码的异步版本如下:
use async_std::{net, task};
let listener = net::TcpListener::bind(address).await?;
let mut new_connections = listener.incoming();
while let Some(socket_result) = new_connections.next().await {
let socket = socket_result?;
let groups = chat_group_table.clone();
task::spawn(async {
log_error(serve(socket, groups).await);
});
}
2
3
4
5
6
7
8
9
10
11
这段代码使用了async_std库的网络和任务模块,并在可能阻塞的调用后添加了.await。但总体结构与基于线程的版本相同。
本章的目标不仅是帮助你编写异步代码,还会详细介绍其工作原理,以便你能够预测它在应用程序中的性能表现,并了解其最有价值的应用场景。
- 为了展示异步编程的机制,我们将列出一组最小的语言特性,涵盖所有核心概念:未来值(futures)、异步函数、等待表达式(await expressions)、任务,以及
block_on和spawn_local执行器。 - 然后我们将介绍异步块和
spawn执行器。这些对于完成实际工作至关重要,但从概念上讲,它们只是我们前面提到的特性的变体。在这个过程中,我们会指出一些你在异步编程中可能遇到的独特问题,并解释如何处理它们。 - 为了展示所有这些部分如何协同工作,我们将逐步讲解聊天服务器和客户端的完整代码,前面的代码片段就是其中的一部分。
- 为了说明基本的未来值和执行器是如何工作的,我们将给出
spawn_blocking和block_on的简单但实用的实现。 - 最后,我们将解释
Pin类型,它不时出现在异步接口中,以确保安全地使用异步函数和块未来值。
# 从同步到异步
考虑一下,当你调用以下(非异步,完全传统的)函数时会发生什么:
use std::io::prelude::*;
use std::net;
fn cheapo_request(host: &str, port: u16, path: &str) -> std::io::Result<String> {
let mut socket = net::TcpStream::connect((host, port))?;
let request = format!("GET {} HTTP/1.1\r\nHost: {}\r\n\r\n", path, host);
socket.write_all(request.as_bytes())?;
socket.shutdown(net::Shutdown::Write)?;
let mut response = String::new();
socket.read_to_string(&mut response)?;
Ok(response)
}
2
3
4
5
6
7
8
9
10
11
12
这个函数打开一个到Web服务器的TCP连接,用一种过时的协议向其发送一个基本的HTTP请求,然后读取响应。图20-1展示了这个函数随时间的执行过程。
此图展示了函数调用栈如何随着时间从左向右运行。每个函数调用都是一个框,放置在其调用者之上。显然,cheapo_request函数在整个执行过程中都在运行。它调用Rust标准库中的函数,如TcpStream::connect以及TcpStream的write_all和read_to_string实现。这些函数又会依次调用其他函数,但最终程序会进行系统调用,向操作系统发出请求以实际完成某些操作,例如打开一个TCP连接或读写一些数据。
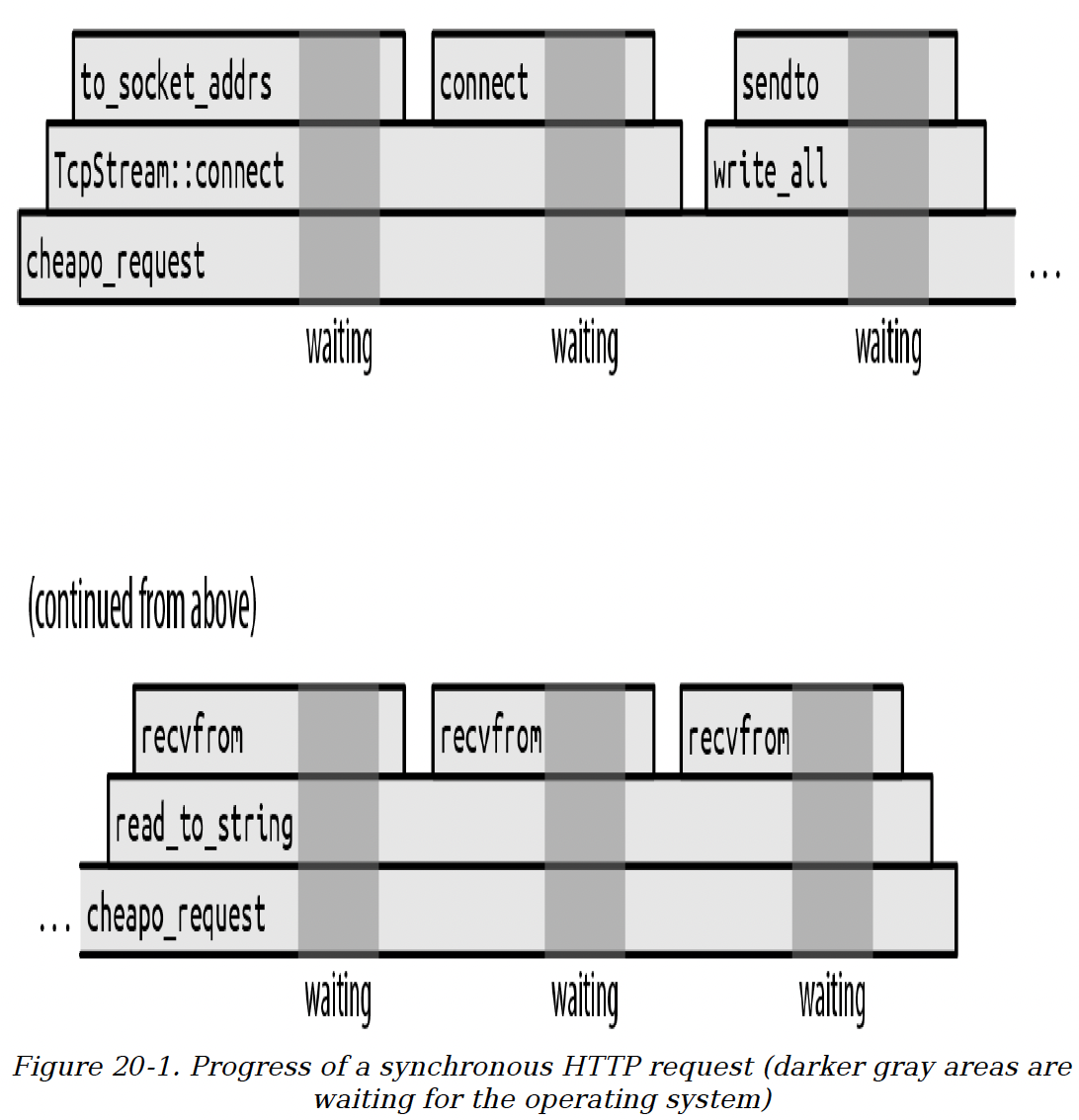 图20-1 异步HTTP请求的执行过程(深灰色区域表示等待操作系统的时间)
图20-1 异步HTTP请求的执行过程(深灰色区域表示等待操作系统的时间)
深灰色背景标记了程序等待操作系统完成系统调用的时间。我们没有按比例绘制这些时间。如果按比例绘制,整个图表将大部分是深灰色的:实际上,这个函数几乎把所有时间都花在等待操作系统上了。前面代码的执行过程在系统调用之间只是很窄的片段。
当这个函数等待系统调用返回时,它所在的单个线程会被阻塞:在系统调用完成之前,它无法执行其他任何操作。一个线程的栈大小达到几十或几百千字节并不罕见,所以如果这是某个更大系统的一部分,有许多线程在执行类似的任务,那么锁定这些线程的资源只是为了等待,代价可能会很高。
为了解决这个问题,线程需要能够在等待系统调用完成时去处理其他工作。但如何实现这一点并不明显。例如,我们用于从套接字读取响应的函数签名如下:
fn read_to_string(&mut self, buf: &mut String) -> std::io::Result<usize>;
从类型中就可以看出:这个函数在任务完成或出现错误之前不会返回。这个函数是同步的:操作完成后调用者才会继续执行。如果我们想在操作系统工作时让线程去做其他事情,就需要一个新的I/O库,它能提供这个函数的异步版本。
# 未来值(Futures)
Rust支持异步操作的方法是引入一个特性std::future::Future:
trait Future {
type Output;
// 目前,将`Pin<&mut Self>`理解为`&mut Self`。
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
enum Poll<T> {
Ready(T),
Pending,
}
2
3
4
5
6
7
8
9
10
Future代表一个你可以检测其是否完成的操作。一个未来值的poll方法永远不会等待操作完成:它总是立即返回。如果操作完成,poll返回Poll::Ready(output),其中output是最终结果。否则,它返回Pending。如果未来值值得再次轮询,它会通过调用一个唤醒器(在Context中提供的回调函数)来通知我们。我们将这种异步编程方式称为 “皮纳塔模型”:对于一个未来值,你唯一能做的就是用poll方法反复探测它,直到得到一个值。
所有现代操作系统都包含其系统调用的变体,我们可以用这些变体来实现这种轮询接口。例如,在Unix和Windows上,如果你将网络套接字设置为非阻塞模式,那么读写操作在可能阻塞时会返回一个错误,你必须稍后再试。
所以read_to_string的异步版本的签名大致如下:
fn read_to_string(&mut self, buf: &mut String) -> impl Future<Output = Result<usize>>;
除了返回类型,这个签名与我们之前展示的相同:异步版本返回一个Result<usize>的未来值。你需要轮询这个未来值,直到从中得到一个Ready(result)。每次轮询时,读取操作会尽可能地进行。最终结果会像普通I/O操作一样,给你一个成功值或错误值。这是一般模式:任何函数的异步版本都与同步版本接受相同的参数,但返回类型被Future包裹。
调用这个版本的read_to_string实际上并不会读取任何内容;它唯一的职责是构造并返回一个未来值,当对这个未来值进行轮询时,它会执行实际的工作。这个未来值必须保存调用所请求的所有必要信息。例如,这个read_to_string返回的未来值必须记住它被调用时的输入流,以及它应该将传入数据追加到的String。实际上,由于未来值持有self和buf的引用,read_to_string的正确签名必须是:
fn read_to_string<'a>(&'a mut self, buf: &'a mut String) -> impl Future<Output = Result<usize>> + 'a;
这里添加了生命周期标注,以表明返回的未来值的生命周期只能与self和buf所借用的值的生命周期一样长。
async-std库提供了std中所有I/O功能的异步版本,包括一个带有read_to_string方法的异步Read特性。async-std紧密遵循std的设计,尽可能在自己的接口中重用std的类型,所以错误、结果、网络地址以及大多数其他相关数据在这两个库中是兼容的。熟悉std有助于你使用async-std,反之亦然。
Future特性的规则之一是,一旦一个未来值返回了Poll::Ready,它可以认为自己再也不会被轮询了。有些未来值如果被过度轮询,会永远返回Poll::Pending;其他的可能会导致程序崩溃或挂起(不过,它们绝不能违反内存或线程安全,否则会导致未定义行为)。Future特性上的fuse适配器方法可以将任何未来值转换为一个永远返回Poll::Pending的未来值。但所有常用的消费未来值的方式都遵循这个规则,所以通常不需要使用fuse。
如果轮询听起来效率不高,别担心。Rust的异步架构经过精心设计,只要像read_to_string这样的基本I/O函数实现正确,你只会在值得轮询时才去轮询一个未来值。每次调用poll时,某个地方的某个操作应该返回Ready,或者至少朝着这个目标取得进展。我们将在 “基本未来值和执行器:何时值得再次轮询未来值?” 中解释这是如何实现的。
但是使用未来值似乎是个挑战:当你轮询时,如果得到Poll::Pending,你该怎么办?你必须暂时找点其他工作让这个线程去做,同时又不能忘记稍后回来再次轮询这个未来值。你的整个程序会充满用于跟踪哪些任务处于挂起状态以及它们准备好后该做什么的复杂代码。cheapo_request函数的简洁性被破坏了。
好消息是!其实并没有。
# 异步函数和 await 表达式
下面是cheapo_request写成异步函数的版本:
use async_std::io::prelude::*;
use async_std::net;
async fn cheapo_request(host: &str, port: u16, path: &str) -> std::io::Result<String> {
let mut socket = net::TcpStream::connect((host, port)).await?;
let request = format!("GET {} HTTP/1.1\r\nHost: {}\r\n\r\n", path, host);
socket.write_all(request.as_bytes()).await?;
socket.shutdown(net::Shutdown::Write)?;
let mut response = String::new();
socket.read_to_string(&mut response).await?;
Ok(response)
}
2
3
4
5
6
7
8
9
10
11
12
这段代码与我们最初的版本逐字对比,区别如下:
- 函数以
async fn开头,而不是fn。 - 它使用了
async_std库中TcpStream::connect、write_all和read_to_string的异步版本。这些函数都返回它们结果的未来值(本节的示例使用async_std1.7版本)。 - 在每个返回未来值的调用之后,代码中都有
.await。虽然这看起来像是对名为await的结构体字段的引用,但它实际上是语言内置的特殊语法,用于等待一个未来值准备就绪。await表达式会计算出未来值的最终值。函数就是通过这种方式从connect、write_all和read_to_string获取结果的。
与普通函数不同,当你调用一个异步函数时,它会在函数体开始执行之前立即返回。显然,调用的最终返回值还没有计算出来;你得到的是其最终值的未来值。所以,如果你执行这段代码:
let response = cheapo_request(host, port, path);
那么response将是一个std::io::Result<String>的未来值,而cheapo_request的函数体还没有开始执行。你不需要调整异步函数的返回类型;Rust会自动将async fn f(...) -> T视为一个返回T的未来值的函数,而不是直接返回T。
异步函数返回的未来值封装了函数体运行所需的所有信息:函数的参数、局部变量的空间等等。(就好像你把调用的栈帧捕获为一个普通的Rust值。)所以response必须保存为host、port和path传递的值,因为cheapo_request的函数体运行时需要这些值。
未来值的具体类型由编译器根据函数体和参数自动生成。这个类型没有名字;你只知道它实现了Future<Output = R>,其中R是异步函数的返回类型。从这个意义上说,异步函数的未来值类似于闭包:闭包也有由编译器生成的匿名类型,这些类型实现了FnOnce、Fn和FnMut特性。
当你首次轮询cheapo_request返回的未来值时,执行从函数体顶部开始,一直运行到TcpStream::connect返回的未来值的第一个await。await表达式会轮询connect的未来值,如果它还没有准备好,就会向它自己的调用者返回Poll::Pending:在TcpStream::connect的未来值轮询返回Poll::Ready之前,对cheapo_request的未来值的轮询无法越过第一个await继续进行。所以TcpStream::connect(...).await表达式大致相当于:
{
// 注意:这是伪代码,不是有效的Rust代码
let connect_future = TcpStream::connect(...);
'retry_point:
match connect_future.poll(cx) {
Poll::Ready(value) => value,
Poll::Pending => {
// 安排下次对`cheapo_request`的未来值进行`poll`时,从'retry_point继续执行
...
return Poll::Pending;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
await表达式获取未来值的所有权,然后对其进行轮询。如果未来值已准备好,那么未来值的最终值就是await表达式的值,执行继续进行。否则,它向自己的调用者返回Poll::Pending。
但关键的是,下一次对cheapo_request的未来值进行轮询时,不会再从函数顶部开始:而是在函数中即将轮询connect_future的位置继续执行。在该未来值准备好之前,我们不会继续执行异步函数的其余部分。
随着对cheapo_request的未来值的持续轮询,它会从一个await移动到下一个await,逐步执行函数体,只有在等待的子未来值准备好时才会继续。因此,cheapo_request的未来值需要被轮询的次数取决于子未来值的行为和函数自身的控制流。
cheapo_request的未来值会跟踪下一次轮询应该从哪里继续,以及继续执行所需的所有局部状态(变量、参数、临时变量等)。
能够在函数中间暂停执行,然后稍后继续,这是异步函数独有的特性。当一个普通函数返回时,它的栈帧就永远消失了。
由于await表达式依赖于能够继续执行的能力,所以你只能在异步函数内部使用它们。
在撰写本文时,Rust还不允许特性拥有异步方法。只有自由函数和特定类型的固有函数可以是异步的。取消这个限制需要对语言进行一些修改。在此期间,如果你需要定义包含异步函数的特性,可以考虑使用async-trait库,它提供了一种基于宏的解决方法。
# 从同步代码中调用异步函数:block_on
从某种意义上讲,异步函数只是把难题丢给了调用者。确实,在异步函数中获取一个未来值很容易:只需使用await。但异步函数本身返回的是一个未来值,所以现在调用者得想办法对其进行轮询。最终,总得有人实际去等待一个值。
我们可以在普通的同步函数(比如main函数)中,使用async_std的task::block_on函数来调用cheapo_request。task::block_on函数接受一个未来值,并对其进行轮询,直到得到一个结果:
fn main() -> std::io::Result<()> {
use async_std::task;
let response = task::block_on(cheapo_request("example.com", 80, "/"))?;
println!("{}", response);
Ok(())
}
2
3
4
5
6
由于block_on是一个同步函数,它会产生异步函数的最终值,所以你可以把它看作是从异步世界到同步世界的适配器。但它的阻塞特性也意味着你绝不能在异步函数中使用block_on:这会阻塞整个线程,直到得到结果。应该使用await代替。
图20 - 2展示了main函数一种可能的执行过程。
上方的时间线“简化视图”展示了程序异步调用的抽象视图:cheapo_request首先调用TcpStream::connect获取一个套接字,然后在该套接字上调用write_all和read_to_string,之后返回。这与本章前面同步版本的cheapo_request的时间线非常相似。
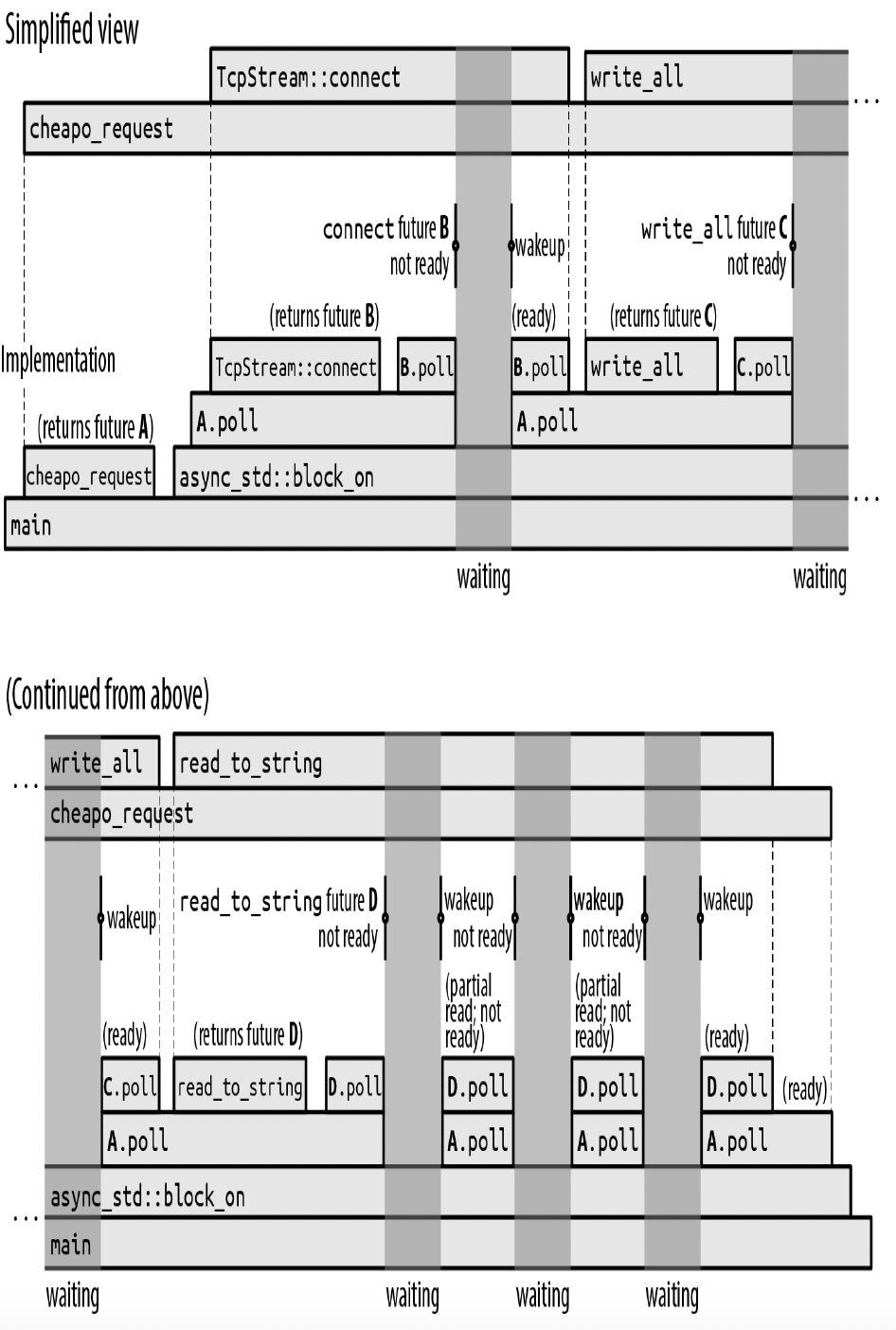 图20 - 2 阻塞等待异步函数
图20 - 2 阻塞等待异步函数
但这些异步调用中的每一个都是一个多步骤的过程:先创建一个未来值,然后对其进行轮询,直到它准备好,在此过程中可能还会创建并轮询其他子未来值。下方的时间线“实现”展示了实现这种异步行为的实际同步调用。这是一个很好的机会,让我们详细了解普通异步执行过程中到底发生了什么:
- 首先,
main函数调用cheapo_request,它返回其最终结果的未来值A。然后main将该未来值传递给async_std::block_on,block_on对其进行轮询。 - 对未来值
A的轮询使得cheapo_request的函数体开始执行。它调用TcpStream::connect以获取一个套接字的未来值B,然后等待这个未来值。更准确地说,由于TcpStream::connect可能会遇到错误,所以B是一个Result<TcpStream, std::io::Error>的未来值。 await会轮询未来值B。由于网络连接尚未建立,B.poll返回Poll::Pending,但会安排在套接字准备好时唤醒调用任务。- 由于未来值
B还没有准备好,A.poll向它自己的调用者block_on返回Poll::Pending。 - 由于
block_on无事可做,它进入睡眠状态。此时整个线程被阻塞。 - 当
B的连接准备好使用时,它会唤醒轮询它的任务。这使得block_on再次行动起来,它会再次尝试轮询未来值A。 - 对
A的轮询导致cheapo_request在其第一个await处恢复执行,在那里它再次轮询B。 - 这次,
B已经准备好:套接字创建完成,所以它向A.poll返回Poll::Ready(Ok(socket))。 - 对
TcpStream::connect的异步调用现在完成了。因此,TcpStream::connect(...).await表达式的值为Ok(socket)。 cheapo_request函数体的执行正常继续,使用format!宏构建请求字符串,并将其传递给socket.write_all。- 由于
socket.write_all是一个异步函数,它返回其结果的未来值C,cheapo_request会等待这个未来值。
后续的过程类似。在图20 - 2所示的执行过程中,socket.read_to_string的未来值在准备好之前被轮询了四次;每次唤醒都会从套接字读取一些数据,但read_to_string被指定要一直读到输入结束,这需要几个操作。
写一个不断调用poll的循环听起来并不难。但async_std::task::block_on的价值在于,它知道如何进入睡眠状态,直到未来值实际上值得再次轮询,而不是浪费处理器时间和电池电量进行数十亿次无意义的轮询调用。像connect和read_to_string这样的基本I/O函数返回的未来值会保留传递给poll的Context提供的唤醒器,并在block_on应该唤醒并再次尝试轮询时调用它。我们将在“基本未来值和执行器:何时值得再次轮询未来值?”中通过自己实现一个简单版本的block_on来确切展示这是如何工作的。
与我们前面展示的原始同步版本一样,这个异步版本的cheapo_request几乎把所有时间都花在了等待操作完成上。如果按比例绘制时间轴,图表几乎全是深灰色的,只有在程序被唤醒时才有一小段计算时间。
这里涉及了很多细节。幸运的是,你通常可以只从简化的上方时间线的角度来思考:有些函数调用是同步的,有些是异步的,需要使用await,但它们都只是函数调用。Rust异步支持的成功取决于帮助程序员在实践中使用简化视图,而不会被实现过程中的来回操作所干扰。
# 生成异步任务
async_std::task::block_on函数会阻塞,直到一个未来值准备就绪。但让线程完全阻塞在单个未来值上,并不比同步调用好:本章的目标是让线程在等待时去做其他工作。
为此,你可以使用async_std::task::spawn_local。这个函数接受一个未来值,并将其添加到一个任务池中,当block_on所阻塞等待的未来值未准备好时,它会尝试对任务池中的未来值进行轮询。所以,如果你将一堆未来值传递给spawn_local,然后对最终结果的未来值应用block_on,那么block_on会在有进展时轮询每个生成的未来值,并发地运行整个任务池,直到你的结果准备好。
在撰写本文时,spawn_local在async-std中只有启用了该库的不稳定特性时才可用。要做到这一点,你需要在Cargo.toml中像这样引用async-std:
async-std = { version = "1", features = ["unstable"] }
spawn_local函数是标准库中用于启动线程的std::thread::spawn函数的异步版本:
std::thread::spawn(c)接受一个闭包c,并启动一个线程来运行它,返回一个std::thread::JoinHandle,其join方法会等待线程完成,并返回c的返回值。async_std::task::spawn_local(f)接受未来值f,并将其添加到任务池中,以便在当前线程调用block_on时进行轮询。spawn_local返回它自己的async_std::task::JoinHandle类型,它本身也是一个未来值,你可以使用await来获取f的最终值。
例如,假设我们想并发地发出一组HTTP请求。下面是第一次尝试:
pub async fn many_requests(requests: Vec<(String, u16, String)>) -> Vec<std::io::Result<String>> {
use async_std::task;
let mut handles = vec![];
for (host, port, path) in requests {
handles.push(task::spawn_local(cheapo_request(&host, port, &path)));
}
let mut results = vec![];
for handle in handles {
results.push(handle.await);
}
results
}
2
3
4
5
6
7
8
9
10
11
12
这个函数对requests中的每个元素调用cheapo_request,将每个调用的未来值传递给spawn_local。它将得到的JoinHandle收集到一个向量中,然后等待每个JoinHandle。以任何顺序等待JoinHandle都没问题:因为请求已经被生成,只要这个线程调用block_on且无事可做时,它们的未来值就会根据需要被轮询。所有请求将并发运行。一旦它们完成,many_requests就会将结果返回给调用者。
前面的代码几乎是正确的,但Rust的借用检查器对cheapo_request的未来值的生命周期表示担忧:
error: `host` does not live long enough
handles.push(task::spawn_local(cheapo_request(&host, port,
&path)));
---------------^^^^^----------
----
| |
| borrowed value
does not
| live long
enough
argument requires that `host` is borrowed
for `'static`
}
- `host` dropped here while still borrowed
2
3
4
5
6
7
8
9
10
11
12
13
14
path也有类似的错误。
自然地,如果我们将引用传递给一个异步函数,它返回的未来值必须持有这些引用,所以这个未来值的生命周期不能超过它所借用的值的生命周期。这与任何持有引用的值所受的限制是一样的。
问题在于spawn_local不能确定在host和path被丢弃之前,你会等待任务完成。实际上,spawn_local只接受生命周期为'static的未来值,因为你可能会简单地忽略它返回的JoinHandle,让任务在程序的剩余执行时间内继续运行。这并非异步任务特有的问题:如果你试图使用std::thread::spawn启动一个闭包捕获了局部变量引用的线程,也会得到类似的错误。
一种解决方法是创建另一个异步函数,它接受参数的拥有所有权的版本:
async fn cheapo_owning_request(host: String, port: u16, path: String) -> std::io::Result<String> {
cheapo_request(&host, port, &path).await
}
2
3
这个函数接受String类型而不是&str引用,所以它的未来值自己拥有host和path字符串的所有权,并且它的生命周期是'static。借用检查器可以看到它立即等待cheapo_request的未来值,因此,如果这个未来值正在被轮询,那么它所借用的host和path变量肯定仍然存在。这样就没问题了。
使用cheapo_owning_request,你可以像这样生成所有请求:
for (host, port, path) in requests {
handles.push(task::spawn_local(cheapo_owning_request(host, port, path)));
}
2
3
你可以在同步的main函数中使用block_on来调用many_requests:
let requests = vec![
("example.com".to_string(), 80, "/".to_string()),
("www.red-bean.com".to_string(), 80, "/".to_string()),
("en.wikipedia.org".to_string(), 80, "/".to_string()),
];
let results = async_std::task::block_on(many_requests(requests));
for result in results {
match result {
Ok(response) => println!("{}", response),
Err(err) => eprintln!("error: {}", err),
}
}
2
3
4
5
6
7
8
9
10
11
12
这段代码在block_on的调用中并发运行所有三个请求。在其他请求被阻塞时,每个请求都能在有机会时取得进展,所有这些都在调用线程上进行。图20 - 3展示了对cheapo_request的三次调用一种可能的执行过程。
(我们鼓励你自己运行这段代码,在cheapo_request的顶部和每个await表达式之后添加eprintln!调用,这样你就能看到每次执行中调用是如何不同地交错进行的。)
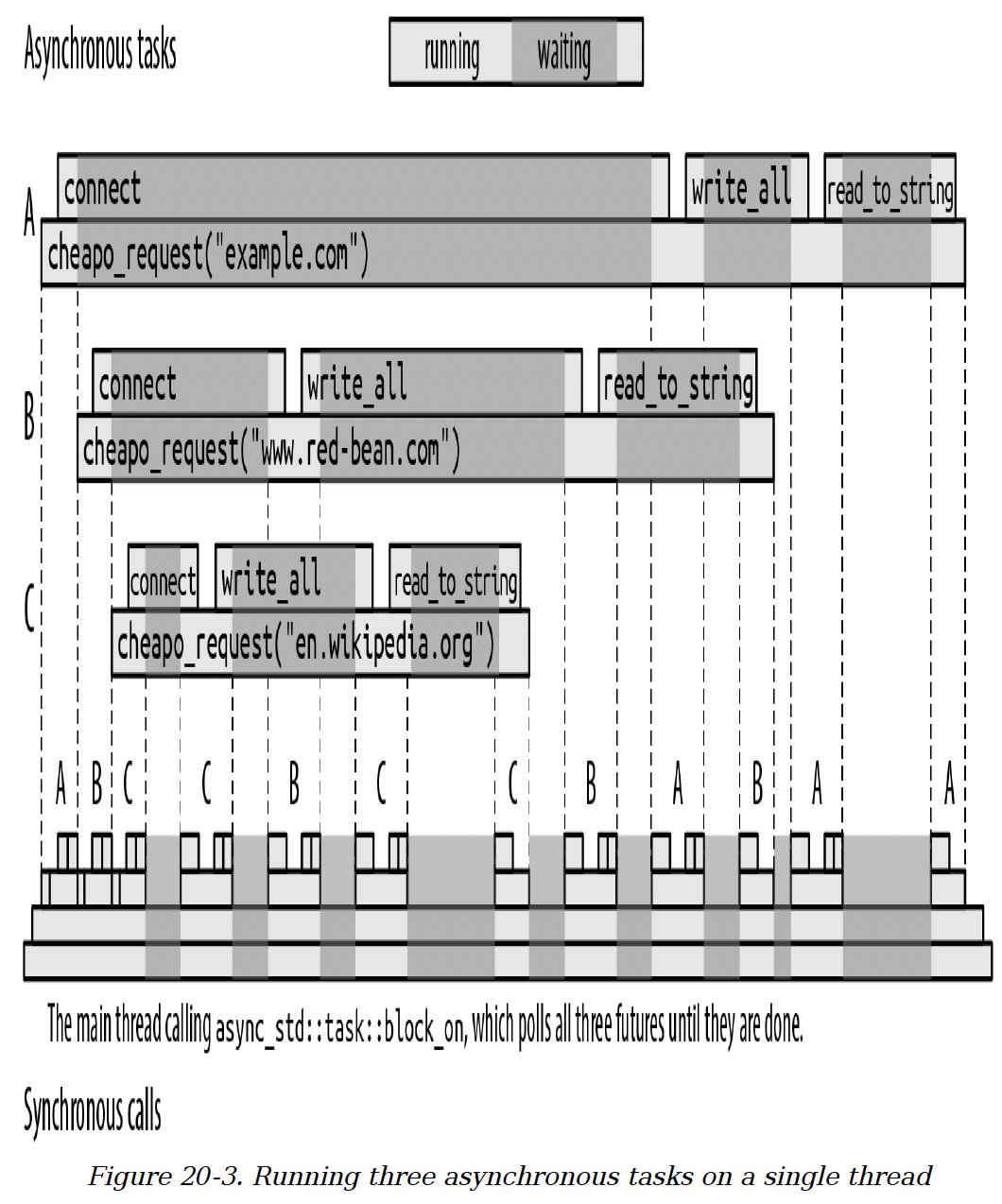 图20 - 3 在单个线程上运行三个异步任务
图20 - 3 在单个线程上运行三个异步任务
对many_requests的调用(为简单起见未展示)生成了三个异步任务,我们将其标记为A、B和C。block_on首先轮询A,A开始连接到example.com。一旦A返回Poll::Pending,block_on就将注意力转向下一个生成的任务,轮询未来值B,最后是C,它们各自开始连接到相应的服务器。
当所有可轮询的未来值都返回Poll::Pending时,block_on进入睡眠状态,直到某个TcpStream::connect的未来值表明其任务值得再次轮询。
在这次执行中,en.wikipedia.org服务器的响应比其他服务器更快,所以该任务最先完成。当一个生成的任务完成时,它会将其值保存在JoinHandle中,并将其标记为已准备好,这样many_requests在等待它时就可以继续进行。最终,其他对cheapo_request的调用要么成功,要么返回一个错误,然后many_requests本身就可以返回。最后,main函数从block_on接收结果向量。
所有这些执行都发生在单个线程上,通过对它们的未来值进行连续轮询,三次对cheapo_request的调用相互交错进行。一个异步调用看起来像是一个函数调用运行至完成,但这个异步调用实际上是通过对未来值的poll方法进行一系列同步调用来实现的。每个单独的poll调用都能快速返回,让出线程,以便另一个异步调用可以轮流执行。
我们终于实现了本章开头设定的目标:让线程在等待I/O完成时去做其他工作,这样线程的资源就不会被闲置。更好的是,实现这个目标的代码看起来非常像普通的Rust代码:有些函数被标记为async,有些函数调用后面跟着.await,我们使用async_std中的函数而不是std中的函数,但除此之外,它就是普通的Rust代码。
需要记住的是,异步任务和线程之间一个重要的区别是,从一个异步任务切换到另一个异步任务只发生在await表达式处,即当正在等待的未来值返回Poll::Pending时。这意味着,如果你在cheapo_request中放入一个长时间运行的计算,在这个计算完成之前,你传递给spawn_local的其他任务都没有机会运行。而对于线程,这个问题不会出现:操作系统可以在任何时候暂停任何线程,并设置定时器以确保没有线程独占处理器。
异步代码依赖于共享线程的未来值的主动协作。如果你需要让长时间运行的计算与异步代码共存,本章后面的 “长时间运行的计算:yield_now和spawn_blocking” 描述了一些选择。
# 异步块
除了异步函数,Rust还支持异步块。普通的块语句返回其最后一个表达式的值,而异步块返回其最后一个表达式的值的未来值。你可以在异步块中使用await表达式。
异步块看起来像普通的块语句,只是在前面加上async关键字:
let serve_one = async {
use async_std::net;
// 监听连接并接受一个连接。
let listener = net::TcpListener::bind("localhost:8087").await?;
let (mut socket, _addr) = listener.accept().await?;
// 与 `socket` 上的客户端进行通信。
...
};
2
3
4
5
6
7
8
这用一个未来值初始化了serve_one,当对这个未来值进行轮询时,它会监听并处理单个TCP连接。就像异步函数调用在其未来值被轮询之前不会开始执行一样,这个块的主体在serve_one被轮询之前也不会开始执行。
如果你在异步块中对一个错误应用?操作符,它只会从这个块返回,而不是从包含它的函数返回。例如,如果前面的bind调用返回一个错误,?操作符会将其作为serve_one的最终值返回。同样,return表达式也是从异步块返回,而不是从外部函数返回。
如果一个异步块引用了在周围代码中定义的变量,它的未来值会捕获这些变量的值,就像闭包一样。就像move闭包(见 “窃取变量的闭包”)一样,你可以在块开头使用async move来获取捕获变量的所有权,而不只是持有它们的引用。
异步块提供了一种简洁的方式,将你希望异步运行的一段代码分离出来。例如,在上一节中,spawn_local需要一个生命周期为'static的未来值,所以我们定义了cheapo_owning_request包装函数,以获得一个拥有其参数所有权的未来值。你可以通过在异步块中调用cheapo_request,而无需使用包装函数,就能达到同样的效果:
pub async fn many_requests(requests: Vec<(String, u16, String)>) -> Vec<std::io::Result<String>> {
use async_std::task;
let mut handles = vec![];
for (host, port, path) in requests {
handles.push(task::spawn_local(async move {
cheapo_request(&host, port, &path).await
}));
}
...
}
2
3
4
5
6
7
8
9
10
由于这是一个async move块,它的未来值像move闭包一样获取String类型的host和path值的所有权。然后它将引用传递给cheapo_request。借用检查器可以看到,这个块的await表达式获取了cheapo_request的未来值的所有权,所以对host和path的引用的生命周期不会超过它们所借用的被捕获变量的生命周期。这个异步块实现了与cheapo_owning_request相同的功能,但样板代码更少。
你可能会遇到一个小问题,即没有类似于异步函数参数后面的-> T这样的语法来指定异步块的返回类型。这在使用?操作符时可能会导致问题:
let input = async_std::io::stdin();
let future = async {
let mut line = String::new();
// 这返回 `std::io::Result<usize>`。
input.read_line(&mut line).await?;
println!("Read line: {}", line);
Ok(())
};
2
3
4
5
6
7
8
这段代码会报错:
error: type annotations needed
|
42 | let future = async {
| ------ consider giving `future` a type
...
46 | input.read_line(&mut line).await?;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ cannot infer type
2
3
4
5
6
7
Rust无法判断这个异步块的返回类型应该是什么。read_line方法返回Result<(), std::io::Error>,但由于?操作符使用From特性将当前的错误类型转换为所需的任何类型,所以这个异步块的返回类型可以是任何实现了From<std::io::Error>的E对应的Result<(), E>。
未来版本的Rust可能会添加指定异步块返回类型的语法。目前,你可以通过明确写出块的最终Ok的类型来解决这个问题:
let future = async {
...
Ok::<(), std::io::Error>(())
};
2
3
4
由于Result是一个泛型类型,需要成功类型和错误类型作为参数,所以我们可以在使用Ok或Err时像这样指定这些类型参数。
# 从异步块构建异步函数
异步块为我们提供了另一种实现与异步函数相同效果的方式,并且更具灵活性。例如,我们可以将cheapo_request示例写成一个普通的同步函数,该函数返回一个异步块的未来值:
use std::io;
use std::future::Future;
fn cheapo_request<'a>(host: &'a str, port: u16, path: &'a str) -> impl Future<Output = io::Result<String>> + 'a {
async move {
...函数体...
}
}
2
3
4
5
6
7
8
当你调用这个版本的函数时,它会立即返回异步块的值的未来值。这会捕获函数的参数,并且行为与异步函数返回的未来值一样。由于我们没有使用async fn语法,所以需要在返回类型中写出impl Future,但对调用者来说,这两个定义是相同函数签名的可互换实现。
当你希望在函数被调用时,在创建结果的未来值之前立即进行一些计算时,第二种方法会很有用。例如,另一种使cheapo_request与spawn_local兼容的方法是将它变成一个同步函数,返回一个生命周期为'static的未来值,该未来值捕获其参数的完全拥有所有权的副本:
fn cheapo_request(host: &str, port: u16, path: &str) -> impl Future<Output = io::Result<String>> + 'static {
let host = host.to_string();
let path = path.to_string();
async move {
...使用 `&*host`、`port` 和 `path`...
}
}
2
3
4
5
6
7
这个版本让异步块将host和path作为拥有所有权的String值捕获,而不是&str引用。由于这个未来值拥有运行所需的所有数据,所以它的生命周期为'static(我们在前面的签名中明确写出了+ 'static,但'static是-> impl返回类型的默认生命周期,所以省略它也没有影响)。
由于这个版本的cheapo_request返回的未来值的生命周期为'static,我们可以直接将它们传递给spawn_local:
let join_handle = async_std::task::spawn_local(
cheapo_request("areweasyncyet.rs", 80, "/")
);
...其他工作...
let response = join_handle.await?;
2
3
4
5
# 在线程池上生成异步任务
到目前为止,我们展示的示例几乎都把时间花在了等待I/O上,但有些工作负载是处理器计算和阻塞操作的混合。当计算量足够大,单个处理器无法处理时,你可以使用async_std::task::spawn将一个未来值生成到一个工作线程池上,这些线程专门用于轮询准备好取得进展的未来值。
async_std::task::spawn的用法与async_std::task::spawn_local类似:
use async_std::task;
let mut handles = vec![];
for (host, port, path) in requests {
handles.push(task::spawn(async move {
cheapo_request(&host, port, &path).await
}));
}
...
2
3
4
5
6
7
8
9
与spawn_local一样,spawn返回一个JoinHandle值,你可以使用await来获取未来值的最终结果。但与spawn_local不同的是,这个未来值不需要等到你调用block_on才会被轮询。一旦线程池中的某个线程空闲,它就会尝试对其进行轮询。
在实践中,spawn比spawn_local使用得更广泛,仅仅是因为人们希望自己的工作负载,无论计算和阻塞操作如何混合,都能在机器的资源上得到均衡分配。
使用spawn时要记住的一点是,线程池会尽量保持忙碌状态,所以你的未来值会被最先轮到的线程进行轮询。一个异步调用可能在一个线程上开始执行,在await表达式处阻塞,然后在另一个线程上恢复执行。所以,虽然将异步函数调用看作是一段单一、连贯的代码执行过程是一种合理的简化(实际上,异步函数和await表达式的目的就是鼓励你这样想),但这个调用实际上可能由许多不同的线程来执行。
如果你使用线程局部存储,可能会惊讶地发现,在await表达式之前存储在那里的数据,在之后被完全不同的数据取代了,因为你的任务现在由线程池中的另一个线程进行轮询。如果这是个问题,你应该使用任务局部存储;有关详细信息,请查看async-std库文档中的task_local!宏。
# 但是你的未来值实现了Send吗?
spawn有一个spawn_local没有的限制。由于未来值会被发送到另一个线程上运行,所以它必须实现Send标记特性。我们在 “线程安全:Send和Sync” 中介绍过Send。只有当一个未来值包含的所有值都是Send时,它才是Send:所有函数参数、局部变量,甚至匿名临时值都必须可以安全地移动到另一个线程。
和前面一样,这个要求并非异步任务所特有:如果你试图使用std::thread::spawn启动一个闭包捕获了非Send值的线程,也会得到类似的错误。不同之处在于,传递给std::thread::spawn的闭包会留在为运行它而创建的线程上,而在线程池上生成的未来值在每次等待时都可能从一个线程移动到另一个线程。
这个限制很容易在不经意间触发。例如,下面这段代码看起来没什么问题:
use async_std::task;
use std::rc::Rc;
async fn reluctant() -> String {
let string = Rc::new("ref-counted string".to_string());
some_asynchronous_thing().await;
format!("Your splendid string: {}", string)
}
task::spawn(reluctant());
2
3
4
5
6
7
8
9
10
一个异步函数的未来值需要保存足够的信息,以便函数能从await表达式处继续执行。在这个例子中,reluctant的未来值在await之后必须使用string,所以这个未来值至少有时会包含一个Rc<String>值。由于Rc指针不能在多个线程之间安全共享,所以这个未来值本身不是Send。而由于spawn只接受Send的未来值,Rust会报错:
error: future cannot be sent between threads safely
|
17 | task::spawn(reluctant());
| ^^^^^^^^^^^ future returned by `reluctant` is not
`Send`
|
|
127 | T: Future + Send + 'static,
| ---- required by this bound in
`async_std::task::spawn`
|
= help: within `impl Future`, the trait `Send` is not
implemented
for `Rc<String>`
note: future is not `Send` as this value is used across an await
|
10 | let string = Rc::new("ref-counted
string".to_string());
| ------ has type `Rc<String>` which is not
`Send`
11 |
12 | some_asynchronous_thing().await;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
await occurs here, with `string` maybe used
later
...
15 | }
| - `string` is later dropped here
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
这个错误信息很长,但包含了很多有用的细节:
- 它解释了为什么未来值需要是
Send:task::spawn要求如此。 - 它解释了哪个值不是
Send:局部变量string,其类型是Rc<String>。 - 它解释了
string为什么会影响未来值:它在指定的await表达式的作用域内。
有两种方法可以解决这个问题。一种是限制非Send值的作用域,使其不覆盖任何await表达式,这样就不需要将其保存在函数的未来值中:
async fn reluctant() -> String {
let return_value = {
let string = Rc::new("ref-counted string".to_string());
format!("Your splendid string: {}", string)
// `Rc<String>` 在这里超出作用域...
};
// ... 因此在我们在这里暂停时它不存在。
some_asynchronous_thing().await;
return_value
}
2
3
4
5
6
7
8
9
10
另一种解决方案是简单地使用std::sync::Arc代替Rc。Arc使用原子更新来管理其引用计数,这会使它稍微慢一些,但Arc指针是Send。
虽然最终你会学会识别并避免使用非Send类型,但一开始它们可能会有点让人意外。(至少,本书的作者经常感到惊讶。)例如,较旧的Rust代码有时会使用这样的泛型结果类型:
// 不推荐!
type GenericError = Box<dyn std::error::Error>;
type GenericResult<T> = Result<T, GenericError>;
2
3
这个GenericError类型使用装箱的特性对象来持有任何实现了std::error::Error的类型的值。但它没有对其进行进一步限制:如果有人有一个实现了Error的非Send类型,他们可以将该类型的装箱值转换为GenericError。
由于存在这种可能性,GenericError不是Send,因此下面的代码将无法工作:
fn some_fallible_thing() -> GenericResult<i32> {
...
}
// 这个函数的未来值不是 `Send`...
async fn unfortunate() {
// ... 因为这个调用的值...
match some_fallible_thing() {
Err(error) => {
report_error(error);
}
Ok(output) => {
// ... 在这个 await 中存在...
use_output(output).await;
}
}
}
// ... 因此这个 `spawn` 是一个错误。
async_std::task::spawn(unfortunate());
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
与前面的例子一样,编译器的错误信息解释了发生了什么,指出Result类型是问题所在。由于Rust认为some_fallible_thing的结果在整个match语句中都存在,包括await表达式,所以它判定unfortunate的未来值不是Send。从Rust的角度来看,这个错误有点过于保守:虽然GenericError确实不能安全地发送到另一个线程,但await只在结果为Ok时才会发生,所以当我们等待use_output的未来值时,错误值实际上并不存在。
理想的解决方案是使用更严格的泛型错误类型,就像我们在 “处理多种错误类型” 中建议的那样:
type GenericError = Box<dyn std::error::Error + Send + Sync +'static>;
type GenericResult<T> = Result<T, GenericError>;
2
这个特性对象明确要求底层的错误类型实现Send,这样就没问题了。
如果你的未来值不是Send,并且不方便使其成为Send,那么你仍然可以使用spawn_local在当前线程上运行它。当然,你需要确保线程在某个时刻调用block_on,给它运行的机会,而且你无法从在多个处理器之间分配工作中受益。
# 长时间运行的计算:yield_now和spawn_blocking
为了让一个未来值能与其他任务在同一线程上友好地共享资源,其poll方法应始终尽可能快速地返回。但是,如果你正在执行一个长时间的计算,可能需要很长时间才能到达下一个await,这会使其他异步任务在等待线程轮到它们执行时等待的时间比预期更长。
一种避免这种情况的方法是偶尔进行等待操作。async_std::task::yield_now函数返回一个专门为此设计的简单未来值:
while computation_not_done() {
...执行一个中等规模的计算步骤...
async_std::task::yield_now().await;
}
2
3
4
第一次轮询yield_now的未来值时,它会返回Poll::Pending,但会表明很快就值得再次轮询。这样做的效果是,你的异步调用会让出线程,让其他任务有机会运行,而且你的调用很快也会再次获得执行机会。第二次轮询yield_now的未来值时,它会返回Poll::Ready(()),此时你的异步函数可以继续执行。
然而,这种方法并不总是可行的。如果你正在使用外部库来进行长时间运行的计算,或者调用C或C++代码,可能不方便修改这些代码以使其更适合异步编程。或者,可能很难确保计算过程中的每一条路径都能时不时地执行到await。
对于这种情况,你可以使用async_std::task::spawn_blocking。这个函数接受一个闭包,在它自己的线程上启动该闭包运行,并返回其返回值的未来值。异步代码可以等待这个未来值,将其所在线程让给其他任务,直到计算完成。通过将繁重的工作放在一个单独的线程上,你可以让操作系统负责合理地分配处理器资源。
例如,假设我们需要将用户提供的密码与存储在身份验证数据库中的哈希版本进行比对。为了安全起见,验证密码需要进行大量的计算,这样即使攻击者获取了我们数据库的副本,他们也无法简单地尝试数万亿个可能的密码来进行匹配。argonautica库提供了一个专门用于存储密码的哈希函数:正确生成的argonautica哈希值需要花费相当长的时间来验证。我们可以在异步应用程序中这样使用argonautica(0.2版本):
async fn verify_password(password: &str, hash: &str, key: &str) -> Result<bool, argonautica::Error> {
// 复制参数,以便闭包可以是'static的。
let password = password.to_string();
let hash = hash.to_string();
let key = key.to_string();
async_std::task::spawn_blocking(move || {
argonautica::Verifier::default()
.with_hash(hash)
.with_password(password)
.with_secret_key(key)
.verify()
}).await
}
2
3
4
5
6
7
8
9
10
11
12
13
如果在给定key(作为整个数据库的密钥)的情况下,password与hash匹配,该函数将返回Ok(true)。通过在传递给spawn_blocking的闭包中进行验证,我们将耗时的计算推到了它自己的线程上,确保它不会影响我们对其他用户请求的响应速度。
# 异步设计的比较
在很多方面,Rust的异步编程方法与其他语言类似。例如,JavaScript、C#和Rust都有带await表达式的异步函数。而且这些语言都有表示未完成计算的值:Rust称它们为 “未来值(futures)”,JavaScript称它们为 “承诺(promises)”,C#称它们为 “任务(tasks)”,但它们都代表一个你可能需要等待的值。
然而,Rust对轮询的使用有所不同。在JavaScript和C#中,异步函数一旦被调用就会立即开始运行,系统库中内置了一个全局事件循环,当异步函数等待的值可用时,该事件循环会恢复挂起的异步函数调用。但在Rust中,异步调用在你将其传递给block_on、spawn或spawn_local等函数进行轮询并推动工作完成之前不会执行任何操作。这些函数被称为执行器(executors),它们承担了其他语言中全局事件循环的角色。
因为Rust让程序员选择执行器来轮询未来值,所以Rust系统中不需要内置全局事件循环。async-std库提供了我们在本章中使用的执行器函数,而我们将在本章后面使用的tokio库则定义了它自己的一组类似的执行器函数。在本章结尾,我们还将实现自己的执行器。你可以在同一个程序中使用这三种执行器。
# 一个真正的异步HTTP客户端
如果我们不展示一个使用合适的异步HTTP客户端库的示例,那就太失职了,因为这非常简单,而且有几个不错的库可供选择,包括reqwest和surf。
下面是对many_requests的重写,它比基于cheapo_request的版本更简单,使用surf并发地运行一系列请求。你需要在Cargo.toml文件中添加以下依赖项:
[dependencies]
async-std = "1.7"
surf = "1.0"
2
3
然后,我们可以这样定义many_requests:
pub async fn many_requests(urls: &[String]) -> Vec<Result<String, surf::Exception>> {
let client = surf::Client::new();
let mut handles = vec![];
for url in urls {
let request = client.get(&url).recv_string();
handles.push(async_std::task::spawn(request));
}
let mut results = vec![];
for handle in handles {
results.push(handle.await);
}
results
}
fn main() {
let requests = &["http://example.com".to_string(),
"https://www.red-bean.com".to_string(),
"https://en.wikipedia.org/wiki/Main_Page".to_string()];
let results = async_std::task::block_on(many_requests(requests));
for result in results {
match result {
Ok(response) => println!("*** {}\n", response),
Err(err) => eprintln!("error: {}\n", err),
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
使用单个surf::Client来发出所有请求,这样如果有几个请求指向同一台服务器,我们就可以重用HTTP连接。而且这里不需要异步块:由于recv_string是一个异步方法,它返回一个Send + 'static的未来值,所以我们可以直接将其未来值传递给spawn。
# 一个异步客户端和服务器
现在是时候把我们到目前为止讨论的关键概念组合成一个可运行的程序了。在很大程度上,异步应用程序与普通的多线程应用程序类似,但你可以留意一下,这里有机会编写更紧凑、更具表现力的代码。
本节的示例是一个聊天服务器和客户端。查看完整代码。真正的聊天系统很复杂,涉及从安全、重新连接到隐私和管理等诸多问题,但我们对其进行了简化,只保留了一些基本功能,以便聚焦于几个有趣的点。
特别地,我们希望能很好地处理背压(backpressure)问题。这意味着,如果一个客户端的网络连接较慢或完全断开连接,绝不能影响其他客户端按自己的节奏交换消息的能力。而且,由于一个慢客户端不应该让服务器消耗大量内存来保存其不断增长的消息积压,我们的服务器应该丢弃那些跟不上节奏的客户端的消息,但要通知它们消息流不完整。(真正的聊天服务器会将消息记录到磁盘上,并让客户端检索它们错过的消息,但我们这里省略了这部分。)
我们使用cargo new --lib async-chat命令启动项目,并在async-chat/Cargo.toml中添加以下内容:
[package]
name = "async-chat"
version = "0.1.0"
authors = ["You <you@example.com>"]
edition = "2018"
[dependencies]
async-std = { version = "1.7", features = ["unstable"] }
tokio = { version = "1.0", features = ["sync"] }
serde = { version = "1.0", features = ["derive", "rc"] }
serde_json = "1.0"
2
3
4
5
6
7
8
9
10
11
我们依赖四个库:
async-std库是我们在本章中一直在使用的异步I/O原语和实用工具的集合。tokio库是另一个类似于async-std的异步原语集合,它是最古老、最成熟的库之一。它被广泛使用,在设计和实现上都遵循高标准,但使用时比async-std需要更多的注意事项。tokio是一个很大的库,但我们只需要其中的一个组件,所以Cargo.toml依赖项中的features = ["sync"]字段会将tokio精简为我们需要的部分,使其成为一个轻量级的依赖项。在异步库生态系统还不太成熟的时候,人们避免在同一个程序中同时使用tokio和async-std,但这两个项目一直在合作,确保只要遵循每个库的文档规则,同时使用它们是可行的。- 我们在第18章中见过
serde和serde_json库。它们为我们提供了方便高效的工具来生成和解析JSON,我们的聊天协议使用JSON在网络上表示数据。我们希望使用serde的一些可选功能,所以在声明依赖项时选择了这些功能。
我们聊天应用程序(包括客户端和服务器)的整体结构如下:
async-chat
├── Cargo.toml
└── src
├── lib.rs
├── utils.rs
└── bin
├── client.rs
└── server
├── main.rs
├── connection.rs
├── group.rs
└── group_table.rs
2
3
4
5
6
7
8
9
10
11
12
这种包布局使用了我们在 “src/bin目录” 中提到的Cargo特性:除了主库src/lib.rs及其子模块src/utils.rs之外,它还包括两个可执行文件:
src/bin/client.rs是聊天客户端的单文件可执行文件。src/bin/server是服务器可执行文件,分布在四个文件中:main.rs包含主函数,还有三个子模块connection.rs、group.rs和group_table.rs。
在本章中,我们将逐步展示每个源文件的内容。一旦所有文件都就位,如果你在这个项目目录中输入cargo build,它将编译库,并构建两个可执行文件。Cargo会自动将库作为依赖项包含进来,这使得它成为放置客户端和服务器共享定义的方便位置。同样,cargo check会检查整个源文件树。要运行其中任何一个可执行文件,你可以使用以下命令:
$ cargo run --release --bin server -- localhost:8088
$ cargo run --release --bin client -- localhost:8088
2
--bin选项指定要运行的可执行文件,--选项后面的任何参数都会传递给可执行文件本身。我们的客户端和服务器只需要知道服务器的地址和TCP端口。
# 错误和结果类型
库的utils模块定义了我们在整个应用程序中使用的结果和错误类型。在src/utils.rs中:
use std::error::Error;
pub type ChatError = Box<dyn Error + Send + Sync + 'static>;
pub type ChatResult<T> = Result<T, ChatError>;
2
3
4
这些是我们在 “处理多种错误类型” 中建议使用的通用错误类型。async_std、serde_json和tokio库各自定义了它们自己的错误类型,但是?操作符可以使用标准库中From特性的实现,自动将它们都转换为ChatError,该实现可以将任何合适的错误类型转换为Box<dyn Error + Send + Sync + 'static>。Send和Sync约束确保如果生成到另一个线程上的任务失败,它可以安全地将错误报告给主线程。
在实际应用中,可以考虑使用anyhow库,它提供了与这些类似的Error和Result类型。anyhow库使用方便,并且提供了一些ChatError和ChatResult所没有的不错的功能。
# 协议
库在lib.rs中定义的这两个类型中涵盖了整个聊天协议:
use serde::{Deserialize, Serialize};
use std::sync::Arc;
pub mod utils;
#[derive(Debug, Deserialize, Serialize, PartialEq)]
pub enum FromClient {
Join { group_name: Arc<String> },
Post {
group_name: Arc<String>,
message: Arc<String>,
},
}
#[derive(Debug, Deserialize, Serialize, PartialEq)]
pub enum FromServer {
Message {
group_name: Arc<String>,
message: Arc<String>,
},
Error(String),
}
#[test]
fn test_fromclient_json() {
use std::sync::Arc;
let from_client = FromClient::Post {
group_name: Arc::new("Dogs".to_string()),
message: Arc::new("Samoyeds rock!".to_string()),
};
let json = serde_json::to_string(&from_client).unwrap();
assert_eq!(json,
r#"{"Post":
{"group_name":"Dogs","message":"Samoyeds rock!"}}"#);
assert_eq!(serde_json::from_str::<FromClient>(&json).unwrap(),
from_client);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
FromClient枚举表示客户端可以发送给服务器的数据包:它可以请求加入一个房间,并向其加入的任何房间发送消息。FromServer表示服务器可以返回的内容:发送到某个群组的消息和错误消息。使用引用计数的Arc<String>而不是普通的String,有助于服务器在管理群组和分发消息时避免复制字符串。
#[derive]属性告诉serde库为FromClient和FromServer生成Serialize和Deserialize特性的实现。这使我们能够调用serde_json::to_string将它们转换为JSON值,通过网络发送,最后调用serde_json::from_str将它们转换回Rust中的形式。
test_fromclient_json单元测试展示了其用法。有了serde派生的Serialize实现,我们可以调用serde_json::to_string将给定的FromClient值转换为以下JSON:
{"Post" :{"group_name" :"Dogs","message" :"Samoyeds rock!"}}
然后,派生的Deserialize实现将其解析回等效的FromClient值。请注意,FromClient中的Arc指针对序列化形式没有影响:引用计数的字符串直接作为JSON对象成员值出现。
# 获取用户输入:异步流
聊天客户端的首要任务是读取用户的命令,并将相应的数据包发送到服务器。管理一个合适的用户界面超出了本章的范围,所以我们将做最简单可行的事情:直接从标准输入读取行。以下代码位于src/bin/client.rs中:
use async_std::prelude::*;
use async_chat::utils::{self, ChatResult};
use async_std::io;
use async_std::net;
async fn send_commands(mut to_server: net::TcpStream) -> ChatResult<()> {
println!("Commands:\n\
join GROUP\n\
post GROUP MESSAGE...\n\
Type Control-D (on Unix) or Control-Z (on Windows)\
to close the connection.");
let mut command_lines =
io::BufReader::new(io::stdin()).lines();
while let Some(command_result) = command_lines.next().await {
let command = command_result?;
// 有关`parse_command`的定义,请查看GitHub仓库。
let request = match parse_command(&command) {
Some(request) => request,
None => continue,
};
utils::send_as_json(&mut to_server, &request).await?;
to_server.flush().await?;
}
Ok(())
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
这段代码调用async_std::io::stdin获取客户端标准输入的异步句柄,将其包装在async_std::io::BufReader中进行缓冲,然后调用lines逐行处理用户输入。它尝试将每一行解析为与某个FromClient值对应的命令,如果成功,就将该值发送到服务器。如果用户输入无法识别的命令,parse_command会打印错误消息并返回None,这样send_commands可以继续循环。如果用户输入文件结束指示符,那么lines流将返回None,send_commands也会返回。这与你在普通同步程序中编写的代码非常相似,只是它使用了async_std库中的版本。
异步BufReader的lines方法很有趣。它不能像标准库那样返回一个迭代器:Iterator::next方法是一个普通的同步函数,所以调用commands.next()会阻塞线程,直到下一行准备好。相反,lines返回一个Result<String>值的流。流是迭代器的异步类似物:它以异步友好的方式按需生成一系列值。以下是async_std::stream模块中Stream特性的定义:
trait Stream {
type Item;
// 目前,将`Pin<&mut Self>`理解为`&mut Self`。
fn poll_next(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>>;
}
2
3
4
5
你可以将其视为Iterator和Future特性的混合体。与迭代器一样,Stream有一个关联的Item类型,并使用Option来指示序列何时结束。但与未来值一样,流必须被轮询:为了获取下一个项(或得知流已结束),你必须调用poll_next,直到它返回Poll::Ready。流的poll_next实现应该始终快速返回,不阻塞。并且如果一个流返回Poll::Pending,它必须通过Context通知调用者何时值得再次轮询。
poll_next方法直接使用起来很麻烦,但通常你不需要这样做。与迭代器一样,流有一系列实用方法,如filter和map。其中有一个next方法,它返回流的下一个Option<Self::Item>的未来值。你不必显式地轮询流,而是可以调用next并等待它返回的未来值。
将这些部分组合在一起,send_commands通过使用while let循环遍历流生成的值来消费输入行的流:
while let Some(item) = stream.next().await {
...使用item...
}
2
3
(未来版本的Rust可能会引入一种异步版本的for循环语法来消费流,就像普通for循环消费Iterator值一样。)
在流结束后(即它返回Poll::Ready(None)表示流结束后)轮询流,就像在迭代器返回None后调用next,或者在未来值返回Poll::Ready后进行轮询一样:Stream特性没有规定流应该怎么做,有些流可能会表现异常。与未来值和迭代器一样,流有一个fuse方法,在需要时确保这种调用的行为可预测;详细信息请查看文档。
在使用流时,务必记住使用async_std的前置导入:
use async_std::prelude::*;
这是因为Stream特性的实用方法,如next、map、filter等,实际上并不是在Stream本身上定义的。相反,它们是一个单独的特性StreamExt的默认方法,StreamExt会为所有Stream自动实现:
pub trait StreamExt : Stream {
...将实用方法定义为默认方法...
}
impl<T: Stream> StreamExt for T { }
2
3
4
5
这是我们在 “特性与他人的类型” 中描述的扩展特性模式的一个示例。async_std::prelude模块将StreamExt方法引入作用域,所以使用前置导入可确保其方法在你的代码中可见。
# 发送数据包
为了在网络套接字上传输数据包,我们的客户端和服务器使用库模块utils中的send_as_json函数:
use async_std::prelude::*;
use serde::Serialize;
use std::marker::Unpin;
pub async fn send_as_json<S, P>(outbound: &mut S, packet: &P) -> ChatResult<()>
where
S: async_std::io::Write + Unpin,
P: Serialize,
{
let mut json = serde_json::to_string(&packet)?;
json.push('\n');
outbound.write_all(json.as_bytes()).await?;
Ok(())
}
2
3
4
5
6
7
8
9
10
11
12
13
14
这个函数将packet构建为String类型的JSON表示,在末尾添加一个换行符,然后将其全部写入outbound。
从它的where子句中,你可以看出send_as_json非常灵活。要发送的数据包类型P可以是任何实现了serde::Serialize的类型。输出流S可以是任何实现了async_std::io::Write的类型,async_std::io::Write是标准库中用于输出流的std::io::Write特性的异步版本。这足以让我们在异步TcpStream上发送FromClient和FromServer值。保持send_as_json的定义为泛型,可确保它不会以意外的方式依赖于流或数据包类型的细节:send_as_json只能使用这些特性中的方法。
S上的Unpin约束是使用write_all方法所必需的。我们将在本章后面介绍固定(pinning)和非固定(unpinning),但目前,在需要的地方为类型变量添加Unpin约束就足够了;如果你忘记了,Rust编译器会指出这些情况。
send_as_json没有直接将数据包序列化到输出流,而是先将其序列化为一个临时的String,然后再将其写入outbound。serde_json库确实提供了直接将值序列化到输出流的函数,但这些函数只支持同步流。要写入异步流,需要对serde_json和serde库中与格式无关的核心部分进行根本性更改,因为它们所围绕设计的特性具有同步方法。
与流一样,async_std的I/O特性的许多方法实际上是在扩展特性上定义的,所以在使用它们时,务必记住使用async_std::prelude::*。
# 接收数据包:更多异步流
为了接收数据包,我们的服务器和客户端将使用utils模块中的这个函数,从异步缓冲的TCP套接字(async_std::io::BufReader<TcpStream>)接收FromClient和FromServer值:
use serde::de::DeserializeOwned;
pub fn receive_as_json<S, P>(inbound: S) -> impl Stream<Item = ChatResult<P>>
where
S: async_std::io::BufRead + Unpin,
P: DeserializeOwned,
{
inbound.lines()
.map(|line_result| -> ChatResult<P> {
let line = line_result?;
let parsed = serde_json::from_str::<P>(&line)?;
Ok(parsed)
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
与send_as_json一样,这个函数在输入流和数据包类型上是泛型的:
- 流类型
S必须实现async_std::io::BufRead,它是std::io::BufRead的异步类似物,表示一个缓冲的输入字节流。 - 数据包类型
P必须实现DeserializeOwned,它是serde的Deserialize特性的更严格版本。为了提高效率,Deserialize可以生成直接从反序列化的缓冲区借用内容的&str和&[u8]值,以避免复制数据。但在我们的情况下,这并不可行:我们需要将反序列化后的值返回给调用者,所以它们的生命周期必须长于解析它们的缓冲区。实现DeserializeOwned的类型总是与它反序列化时的缓冲区无关。
调用inbound.lines()会给我们一个std::io::Result<String>值的流。然后我们使用流的map适配器将一个闭包应用于每个项,处理错误并将每一行解析为类型P的值的JSON形式。这给我们一个ChatResult<P>值的流,我们直接返回它。该函数的返回类型是:
impl Stream<Item = ChatResult<P>>
这表明我们返回某种类型,它会异步生成一系列ChatResult<P>值,但调用者无法确切知道具体是哪种类型。由于我们传递给map的闭包本身具有匿名类型,这是receive_as_json可能返回的最具体的类型。注意,receive_as_json本身不是一个异步函数。它是一个普通函数,返回一个异步值,即一个流。比 “到处添加async和.await” 更深入地理解Rust异步支持的机制,为像这样清晰、灵活和高效的定义开辟了可能性,这些定义充分利用了这门语言的特性。
为了了解receive_as_json的使用方式,下面是我们聊天客户端的handle_replies函数,它位于src/bin/client.rs中,用于从网络接收FromServer值的流,并将其打印出来供用户查看:
use async_chat::FromServer;
async fn handle_replies(from_server: net::TcpStream) -> ChatResult<()> {
let buffered = io::BufReader::new(from_server);
let mut reply_stream = utils::receive_as_json(buffered);
while let Some(reply) = reply_stream.next().await {
match reply? {
FromServer::Message { group_name, message } => {
println!("message posted to {}: {}", group_name, message);
}
FromServer::Error(message) => {
println!("error from server: {}", message);
}
}
}
Ok(())
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
这个函数接受一个从服务器接收数据的套接字,用BufReader(注意是async_std版本)将其包装,然后将其传递给receive_as_json以获取传入的FromServer值的流。然后它使用while let循环处理传入的回复,检查错误结果,并将每个服务器回复打印出来供用户查看。
# 客户端的主函数
既然我们已经介绍了send_commands和handle_replies,现在可以展示聊天客户端的主函数了,它位于src/bin/client.rs中:
use async_std::task;
fn main() -> ChatResult<()> {
let address = std::env::args().nth(1)
.expect("Usage: client ADDRESS:PORT");
task::block_on(async {
let socket = net::TcpStream::connect(address).await?;
socket.set_nodelay(true)?;
let to_server = send_commands(socket.clone());
let from_server = handle_replies(socket);
from_server.race(to_server).await?;
Ok(())
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
从命令行获取服务器地址后,main函数有一系列想要调用的异步函数,所以它将函数的其余部分包装在一个异步块中,并将该块的未来值传递给async_std::task::block_on来运行。
一旦建立连接,我们希望send_commands和handle_replies函数同时运行,这样在我们输入时就能看到其他人的消息到达。如果我们输入文件结束指示符,或者与服务器的连接断开,程序应该退出。
根据我们在本章其他地方的做法,你可能会期望看到这样的代码:
let to_server = task::spawn(send_commands(socket.clone()));
let from_server = task::spawn(handle_replies(socket));
to_server.await?;
from_server.await?;
2
3
4
但由于我们等待了两个JoinHandle,这会使程序在两个任务都完成后才退出。而我们希望只要其中一个任务完成就退出。未来值的race方法可以实现这一点。调用from_server.race(to_server)会返回一个新的未来值,它会轮询from_server和to_server,只要其中一个准备好,就返回Poll::Ready(v)。两个未来值必须具有相同的输出类型:最终值是最先完成的那个未来值的值。未完成的未来值将被丢弃。
race方法以及许多其他便捷实用方法,都定义在async_std::prelude::FutureExt特性中,async_std::prelude使我们能够使用这些方法。
此时,客户端代码中唯一我们还没有展示的部分是parse_command函数。这是相当简单的文本处理代码,所以我们这里不展示它的定义。详细内容请查看Git仓库中的完整代码。
# 服务器的主函数
以下是服务器主文件src/bin/server/main.rs的全部内容:
use async_std::prelude::*;
use async_chat::utils::ChatResult;
use std::sync::Arc;
mod connection;
mod group;
mod group_table;
use connection::serve;
fn main() -> ChatResult<()> {
let address = std::env::args().nth(1).expect("Usage: server ADDRESS");
let chat_group_table =
Arc::new(group_table::GroupTable::new());
async_std::task::block_on(async {
// 此代码在本章开头已展示。
use async_std::{net, task};
let listener = net::TcpListener::bind(address).await?;
let mut new_connections = listener.incoming();
while let Some(socket_result) =
new_connections.next().await {
let socket = socket_result?;
let groups = chat_group_table.clone();
task::spawn(async {
log_error(serve(socket, groups).await);
});
}
Ok(())
})
}
fn log_error(result: ChatResult<()>) {
if let Err(error) = result {
eprintln!("Error: {}", error);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
服务器的主函数与客户端的类似:它进行一些设置,然后调用block_on来运行一个异步块,该块执行实际工作。为了处理来自客户端的传入连接,它创建一个TcpListener套接字,其incoming方法返回一个std::io::Result<TcpStream>值的流。
对于每个传入连接,我们生成一个异步任务来运行connection::serve函数。每个任务还会接收一个指向GroupTable值的引用,该值表示服务器当前的聊天群组列表,所有连接通过Arc引用计数指针共享这个列表。
如果connection::serve返回一个错误,我们将一条消息记录到标准错误输出,然后让任务退出。其他连接继续正常运行。
# 处理聊天连接:异步互斥锁
下面是服务器的核心函数:src/bin/server/connection.rs中connection模块的serve函数:
use async_chat::{FromClient, FromServer};
use async_chat::utils::{self, ChatResult};
use async_std::prelude::*;
use async_std::io::BufReader;
use async_std::net::TcpStream;
use async_std::sync::Arc;
use crate::group_table::GroupTable;
pub async fn serve(socket: TcpStream, groups: Arc<GroupTable>) -> ChatResult<()> {
let outbound = Arc::new(Outbound::new(socket.clone()));
let buffered = BufReader::new(socket);
let mut from_client = utils::receive_as_json(buffered);
while let Some(request_result) = from_client.next().await {
let request = request_result?;
let result = match request {
FromClient::Join { group_name } => {
let group = groups.get_or_create(group_name);
group.join(outbound.clone());
Ok(())
}
FromClient::Post { group_name, message } => {
match groups.get(&group_name) {
Some(group) => {
group.post(message);
Ok(())
}
None => {
Err(format!("Group '{}' does not exist", group_name))
}
}
}
};
if let Err(message) = result {
let report = FromServer::Error(message);
outbound.send(report).await?;
}
}
Ok(())
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
这几乎是客户端handle_replies函数的镜像:代码的主要部分是一个循环,处理从缓冲的TCP流通过receive_as_json构建的FromClient值的输入流。如果发生错误,我们生成一个FromServer::Error数据包,将错误消息传达回客户端。
除了错误消息,客户端还希望接收来自其加入的聊天群组的消息,所以与客户端的连接需要与每个群组共享。我们可以简单地给每个群组一个TcpStream的克隆,但如果其中两个源试图同时向套接字写入数据包,它们的输出可能会交错,客户端最终可能会收到乱码的JSON。我们需要安排对连接的安全并发访问。
这是通过Outbound类型来管理的,Outbound在src/bin/server/connection.rs中定义如下:
use async_std::sync::Mutex;
pub struct Outbound(Mutex<TcpStream>);
impl Outbound {
pub fn new(to_client: TcpStream) -> Outbound {
Outbound(Mutex::new(to_client))
}
pub async fn send(&self, packet: FromServer) -> ChatResult<()> {
let mut guard = self.0.lock().await;
utils::send_as_json(&mut *guard, &packet).await?;
guard.flush().await?;
Ok(())
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
创建Outbound值时,它会获取一个TcpStream的所有权,并将其包装在一个互斥锁(Mutex)中,以确保一次只有一个任务可以使用它。serve函数将每个Outbound包装在一个Arc引用计数指针中,这样客户端加入的所有群组都可以指向同一个共享的Outbound实例。
调用Outbound::send时,首先会锁定互斥锁,返回一个可解引用为内部TcpStream的守护值(guard value)。我们使用send_as_json传输packet,最后调用guard.flush()以确保它不会在某个缓冲区中半传输状态下滞留。(据我们所知,TcpStream实际上不会缓冲数据,但Write特性允许其实现进行缓冲,所以我们不能冒险。)
表达式&mut *guard让我们解决了Rust不会为满足特性边界而应用解引用强制转换的问题。相反,我们显式地解引用互斥锁的守护值,然后借用它所保护的TcpStream的可变引用,从而得到send_as_json所需的&mut TcpStream。
注意,Outbound使用的是async_std::sync::Mutex类型,而不是标准库中的Mutex。这有三个原因。
首先,如果一个任务在持有互斥锁守护值时被挂起,标准库中的Mutex可能会出现问题。如果运行该任务的线程接收到另一个试图锁定同一个Mutex的任务,就会出现问题:从Mutex的角度来看,已经拥有它的线程正在尝试再次锁定它。标准的Mutex不是为处理这种情况而设计的,所以它会导致程序崩溃或死锁(它永远不会不恰当地授予锁)。目前正在进行相关工作,以使Rust在编译时检测到这个问题,并在std::sync::Mutex守护值在await表达式中存在时发出警告。由于Outbound::send在等待send_as_json和guard.flush的未来值时需要持有锁,所以它必须使用async_std的Mutex。
其次,异步Mutex的lock方法返回一个守护值的未来值,所以等待锁定互斥锁的任务会让出其线程,供其他任务使用,直到互斥锁可用(如果互斥锁已经可用,lock的未来值会立即准备好,任务根本不会挂起自身)。另一方面,标准Mutex的lock方法在等待获取锁时会阻塞整个线程。由于前面的代码在通过网络传输数据包时持有互斥锁,这可能会花费相当长的时间。
最后,标准Mutex必须只能由锁定它的同一个线程解锁。为了强制执行这一点,标准互斥锁的守护类型没有实现Send:它不能被传输到其他线程。这意味着持有这样一个守护值的未来值本身没有实现Send,不能传递给spawn在线程池上运行;它只能与block_on或spawn_local一起使用。async_std的Mutex的守护值实现了Send,所以在生成的任务中使用它没有问题。
# 群组表:同步互斥锁
但事情并非简单到 “在异步代码中总是使用async_std::sync::Mutex”。通常情况下,在持有互斥锁时无需等待任何操作,且持有锁的时间也不长。在这种情况下,标准库中的Mutex可能会更高效。我们聊天服务器的GroupTable类型就说明了这种情况。以下是src/bin/server/group_table.rs的完整内容:
use crate::group::Group;
use std::collections::HashMap;
use std::sync::{Arc, Mutex};
pub struct GroupTable(Mutex<HashMap<Arc<String>, Arc<Group>>>);
impl GroupTable {
pub fn new() -> GroupTable {
GroupTable(Mutex::new(HashMap::new()))
}
pub fn get(&self, name: &String) -> Option<Arc<Group>> {
self.0.lock()
.unwrap()
.get(name)
.cloned()
}
pub fn get_or_create(&self, name: Arc<String>) -> Arc<Group> {
self.0.lock()
.unwrap()
.entry(name.clone())
.or_insert_with(|| Arc::new(Group::new(name)))
.clone()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
GroupTable只是一个由互斥锁保护的哈希表,将聊天群组名称映射到实际的群组,两者都使用引用计数指针进行管理。get和get_or_create方法会锁定互斥锁,执行一些哈希表操作,可能还会进行一些内存分配,然后返回。
在GroupTable中,我们使用普通的std::sync::Mutex。这个模块中根本没有异步代码,所以也不存在需要避免的await操作。实际上,如果我们在这里使用async_std::sync::Mutex,就需要将get和get_or_create变成异步函数,这会引入创建未来值、挂起和恢复的开销,但却没有什么实际好处:互斥锁只是在一些哈希操作和可能的少量内存分配期间被锁定。
如果我们的聊天服务器有上百万用户,并且GroupTable的互斥锁真的成为了瓶颈,将其异步化并不能解决问题。使用某种专门为并发访问设计的集合类型(而不是HashMap)可能会更好。例如,dashmap库就提供了这样的类型。
# 聊天群组:tokio 的广播通道
在我们的服务器中,group::Group类型代表一个聊天群组。这个类型只需要支持connection::serve调用的两个方法:join用于添加新成员,post用于发布消息。发布的每条消息都需要分发给所有成员。
这就是我们要解决前面提到的背压问题的地方。这里有几个相互矛盾的需求:
- 如果一个成员跟不上群组中发布的消息(比如网络连接缓慢),群组中的其他成员不应受到影响。
- 即使一个成员落后了,也应该有办法让他们重新加入对话并继续以某种方式参与。
- 用于缓冲消息的内存不应无限制地增长。
由于在实现多对多通信模式时这些挑战很常见,tokio库提供了一种广播通道类型,它实现了一组合理的权衡。tokio广播通道是一个值(在我们的例子中是聊天消息)的队列,它允许任意数量的不同线程或任务发送和接收值。它被称为 “广播” 通道,是因为每个消费者都会得到发送的每个值的自己的副本(值类型必须实现Clone)。
通常情况下,广播通道会在队列中保留一条消息,直到每个消费者都获取到自己的副本。但是,如果队列的长度超过了创建时指定的最大容量,最旧的消息就会被丢弃。任何跟不上的消费者在下次尝试获取下一条消息时都会收到一个错误,并且通道会让他们跟上仍然可用的最旧消息。
例如,图20 - 4展示了一个最大容量为16个值的广播通道。
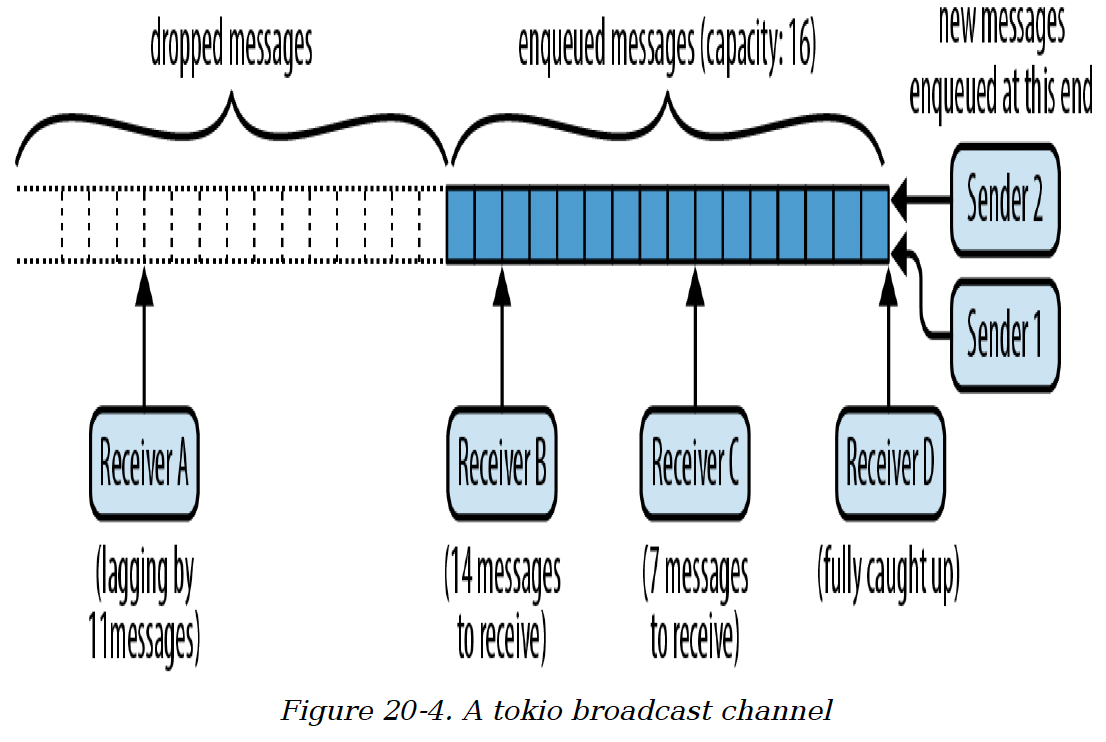 图20 - 4 一个tokio广播通道
图20 - 4 一个tokio广播通道
有两个发送者在队列中添加消息,四个接收者在队列中取出消息 —— 或者更准确地说,是从队列中复制消息。接收者B还有14条消息要接收,接收者C有7条,接收者D已经完全跟上。接收者A落后了,在它看到之前有11条消息被丢弃了。它下次尝试接收消息时会失败,返回一个指示这种情况的错误,并且它会被更新到当前队列的末尾。
我们的聊天服务器将每个聊天群组表示为一个携带Arc<String>值的广播通道:向群组发布消息会将其广播给所有当前成员。以下是group::Group类型的定义,它在src/bin/server/group.rs中:
use async_std::task;
use crate::connection::Outbound;
use std::sync::Arc;
use tokio::sync::broadcast;
pub struct Group {
name: Arc<String>,
sender: broadcast::Sender<Arc<String>>
}
impl Group {
pub fn new(name: Arc<String>) -> Group {
let (sender, _receiver) = broadcast::channel(1000);
Group { name, sender }
}
pub fn join(&self, outbound: Arc<Outbound>) {
let receiver = self.sender.subscribe();
task::spawn(handle_subscriber(self.name.clone(), receiver, outbound));
}
pub fn post(&self, message: Arc<String>) {
// 只有在没有订阅者时,这个操作才会返回错误。连接的输出端可能会在输入端之前退出,丢弃其订阅,
// 这可能会导致输入端试图向空群组发送消息。
let _ignored = self.sender.send(message);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
Group结构体包含聊天群组的名称,以及一个broadcast::Sender,它代表群组广播通道的发送端。Group::new方法调用broadcast::channel创建一个最大容量为1000条消息的广播通道。channel函数会返回一个发送者和一个接收者,但此时我们不需要接收者,因为群组还没有任何成员。
为了向群组中添加新成员,Group::join方法会调用发送者的subscribe方法为通道创建一个新的接收者。然后它会生成一个新的异步任务,在handle_subscribe函数中监控该接收者以获取消息并将其写回客户端。
有了这些细节,Group::post方法就很简单了:它只是将消息发送到广播通道。由于通道携带的值是Arc<String>值,给每个接收者一个消息副本只会增加消息的引用计数,而无需任何复制或堆内存分配。一旦所有订阅者都传输了该消息,引用计数就会降为零,消息就会被释放。以下是handle_subscriber的定义:
use async_chat::FromServer;
use tokio::sync::broadcast::error::RecvError;
async fn handle_subscriber(group_name: Arc<String>, mut receiver: broadcast::Receiver<Arc<String>>, outbound: Arc<Outbound>) {
loop {
let packet = match receiver.recv().await {
Ok(message) => FromServer::Message {
group_name: group_name.clone(),
message: message.clone(),
},
Err(RecvError::Lagged(n)) => FromServer::Error(
format!("Dropped {} messages from {}.", n, group_name)
),
Err(RecvError::Closed) => break,
};
if outbound.send(packet).await.is_err() {
break;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
虽然细节不同,但这个函数的形式很常见:它是一个循环,从广播通道接收消息,并通过共享的Outbound值将其传输回客户端。如果循环跟不上广播通道的速度,它会收到一个Lagged错误,并如实向客户端报告。
如果将数据包发送回客户端完全失败,可能是因为连接已经关闭,handle_subscriber会退出循环并返回,导致异步任务退出。这会丢弃广播通道的接收者,使其取消对通道的订阅。
这样,当一个连接断开时,下次群组尝试向其发送消息时,它的每个组成员身份都会被清理。
我们的聊天群组永远不会关闭,因为我们从不从群组表中删除群组,但为了完整起见,handle_subscriber已经准备好通过退出任务来处理Closed错误。
请注意,我们为每个客户端的每个组成员身份都创建了一个新的异步任务。这是可行的,因为异步任务比线程使用的内存少得多,并且在一个进程中从一个异步任务切换到另一个异步任务的效率非常高。
这就是聊天服务器的完整代码。它有点简陋,而且async_std、tokio和futures库中还有许多有价值的功能,我们在本书中无法全部涵盖,但希望这个扩展示例能够说明异步生态系统的一些功能是如何协同工作的:异步任务、流、异步I/O特性、通道以及两种类型的互斥锁。
# 原生Future和执行器:何时值得再次轮询Future?
聊天服务器展示了我们如何使用诸如TcpListener和广播通道之类的异步原语编写代码,以及如何使用block_on和spawn等执行器来驱动它们的执行。现在我们可以来看看这些是如何实现的。关键问题在于,当一个Future返回Poll::Pending时,它如何与执行器协调,以便在正确的时间再次对其进行轮询?
想想当我们运行聊天客户端主函数中的如下代码时会发生什么:
task::block_on(async {
let socket = net::TcpStream::connect(address).await?;
...
})
2
3
4
block_on第一次轮询这个异步块的Future时,网络连接几乎肯定不会立即就绪,所以block_on会进入睡眠状态。但它应该在什么时候唤醒呢?不知怎的,一旦网络连接就绪,TcpStream需要告诉block_on,它应该再次尝试轮询这个异步块的Future,因为它知道这次await将会完成,异步块的执行也能够继续推进。
当像block_on这样的执行器轮询一个Future时,它必须传入一个名为唤醒器(waker)的回调函数。如果Future尚未准备好,根据Future特性的规则,它目前必须返回Poll::Pending,并安排在该Future值得再次轮询时调用这个唤醒器。
所以,手动实现的Future通常如下所示:
use std::task::Waker;
struct MyPrimitiveFuture {
...
waker: Option<Waker>,
}
impl Future for MyPrimitiveFuture {
type Output =...;
fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<...> {
...
if... Future已准备好... {
return Poll::Ready(final_value);
}
// 保存唤醒器以供后续使用。
self.waker = Some(cx.waker().clone());
Poll::Pending
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
换句话说,如果Future的值已准备好,就返回它。否则,将Context的唤醒器的克隆保存起来,然后返回Poll::Pending。
当Future值得再次轮询时,它必须通过调用唤醒器来通知上一次轮询它的执行器:
// 如果我们有一个唤醒器,调用它,并清空`self.waker`。
if let Some(waker) = self.waker.take() {
waker.wake();
}
2
3
4
理想情况下,执行器和Future会轮流进行轮询和唤醒操作:执行器轮询Future,然后进入睡眠状态,接着Future调用唤醒器,这样执行器就会醒来并再次轮询Future。
异步函数和异步块的Future本身并不处理唤醒器。它们只是将接收到的Context传递给它们正在等待的子Future,将保存和调用唤醒器的任务委托给子Future。在我们的聊天客户端中,对异步块的Future的第一次轮询,在等待TcpStream::connect的Future时只是将Context传递下去。后续的轮询同样会将它们的Context传递给该块接下来等待的任何Future。
TcpStream::connect的Future的轮询处理方式如前面的示例所示:它将唤醒器交给一个辅助线程,该线程等待连接就绪,然后调用唤醒器。
Waker实现了Clone和Send,所以一个Future总是可以创建自己的唤醒器副本,并根据需要将其发送到其他线程。Waker::wake方法会消耗唤醒器。还有一个wake_by_ref方法不会消耗唤醒器,但有些执行器可以更高效地实现消耗版本(两者的区别最多只是一次克隆操作)。
执行器过度轮询一个Future并无危害,只是效率较低。然而,Future应该注意仅在轮询能够真正取得进展时才调用唤醒器:虚假的唤醒和轮询循环可能会导致执行器根本无法进入睡眠状态,这会浪费资源,并且使处理器对其他任务的响应性降低。
既然我们已经展示了执行器和原生Future如何通信,接下来我们将自己实现一个原生Future,然后逐步讲解block_on执行器的实现。
# 调用唤醒器:spawn_blocking
在本章前面,我们介绍了spawn_blocking函数,它会在另一个线程上启动给定的闭包,并返回其返回值的Future。现在我们已经具备了自己实现spawn_blocking所需的所有要素。为简单起见,我们的版本为每个闭包创建一个新线程,而不像async_std的版本那样使用线程池。
虽然spawn_blocking返回一个Future,但我们不会将其写成async fn。相反,它将是一个普通的同步函数,返回一个结构体SpawnBlocking,我们将为其实现Future特性。
我们的spawn_blocking的签名如下:
pub fn spawn_blocking<T, F>(closure: F) -> SpawnBlocking<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,
2
3
4
5
由于我们需要将闭包发送到另一个线程并将返回值带回,所以闭包F及其返回值T都必须实现Send。并且由于我们不知道线程会运行多长时间,它们的生命周期也都必须是'static。这些约束与std::thread::spawn本身所施加的约束相同。
SpawnBlocking<T>是闭包返回值的Future。它的定义如下:
use std::sync::{Arc, Mutex};
use std::task::Waker;
pub struct SpawnBlocking<T>(Arc<Mutex<Shared<T>>>);
struct Shared<T> {
value: Option<T>,
waker: Option<Waker>,
}
2
3
4
5
6
7
8
9
Shared结构体必须充当Future和运行闭包的线程之间的一个会合点,所以它由Arc拥有,并由Mutex保护(这里使用同步互斥锁就可以)。轮询Future时会检查value是否存在,如果不存在则将唤醒器保存在waker中。运行闭包的线程会将其返回值保存在value中,然后如果waker存在则调用它。
以下是spawn_blocking的完整定义:
pub fn spawn_blocking<T, F>(closure: F) -> SpawnBlocking<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,
{
let inner = Arc::new(Mutex::new(Shared {
value: None,
waker: None,
}));
std::thread::spawn({
let inner = inner.clone();
move || {
let value = closure();
let maybe_waker = {
let mut guard = inner.lock().unwrap();
guard.value = Some(value);
guard.waker.take()
};
if let Some(waker) = maybe_waker {
waker.wake();
}
}
});
SpawnBlocking(inner)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
创建Shared值后,这段代码会生成一个线程来运行闭包,将结果存储在Shared的value字段中,并调用唤醒器(如果有的话)。
我们可以为SpawnBlocking实现Future特性如下:
use std::future::Future;
use std::pin::Pin;
use std::task::{Context, Poll};
impl<T: Send> Future for SpawnBlocking<T> {
type Output = T;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<T> {
let mut guard = self.0.lock().unwrap();
if let Some(value) = guard.value.take() {
return Poll::Ready(value);
}
guard.waker = Some(cx.waker().clone());
Poll::Pending
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
轮询SpawnBlocking时会检查闭包的值是否已准备好,如果是则获取所有权并返回它。否则,Future仍处于挂起状态,所以它会将Context的唤醒器的克隆保存在Future的waker字段中。
一旦一个Future返回了Poll::Ready,就不应该再对其进行轮询。通常使用Future的方式,如await和block_on,都遵循这个规则。如果对SpawnBlocking的Future过度轮询,不会发生特别糟糕的事情,但它也不会特意去处理这种情况。这是手动实现的Future的典型情况。
# 实现block_on
除了能够实现基本的未来值,我们还具备构建一个简单执行器所需的所有要素。在本节中,我们将编写自己版本的block_on。它会比async_std中的版本简单得多;例如,它不支持spawn_local、任务局部变量,也不支持嵌套调用(在异步代码中调用block_on)。但它足以运行我们的聊天客户端和服务器。
代码如下:
use waker_fn::waker_fn; // Cargo.toml: waker-fn = "1.1"
use futures_lite::pin; // Cargo.toml: futures-lite = "1.11"
use crossbeam::sync::Parker; // Cargo.toml: crossbeam = "0.8"
use std::future::Future;
use std::task::{Context, Poll};
fn block_on<F: Future>(future: F) -> F::Output {
let parker = Parker::new();
let unparker = parker.unparker().clone();
let waker = waker_fn(move || unparker.unpark());
let mut context = Context::from_waker(&waker);
pin!(future);
loop {
match future.as_mut().poll(&mut context) {
Poll::Ready(value) => return value,
Poll::Pending => parker.park(),
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
这段代码相当简短,但其中有很多内容,所以让我们逐部分分析。
let parker = Parker::new();
let unparker = parker.unparker().clone();
2
crossbeam库的Parker类型是一个简单的阻塞原语:调用parker.park()会阻塞线程,直到其他人对通过parker.unparker()预先获取的相应Unparker调用.unpark()。如果你在一个尚未阻塞的线程上调用unpark,那么它下次调用park时会立即返回,不会阻塞。我们的block_on会在未来值未准备好时使用Parker进行等待,而我们传递给未来值的唤醒器会调用unpark来唤醒线程。
let waker = waker_fn(move || unparker.unpark());
waker_fn函数(来自同名库)根据给定的闭包创建一个Waker。在这里,我们创建了一个Waker,当它被调用时,会调用闭包move || unparker.unpark()。你也可以仅使用标准库来创建唤醒器,但waker_fn更方便一些。
pin!(future);
给定一个持有类型为F的未来值的变量,pin!宏会获取该未来值的所有权,并声明一个同名的新变量,其类型为Pin<&mut F>,并借用该未来值。这为我们提供了poll方法所需的Pin<&mut Self>。出于下一节将解释的原因,异步函数和异步块的未来值在被轮询之前,必须通过Pin进行引用。
loop {
match future.as_mut().poll(&mut context) {
Poll::Ready(value) => return value,
Poll::Pending => parker.park(),
}
}
2
3
4
5
6
最后,轮询循环非常简单。我们带着我们的唤醒器传递一个上下文,轮询未来值,直到它返回Poll::Ready。如果它返回Poll::Pending,我们阻塞线程,直到唤醒器被调用。然后我们再次尝试。
as_mut调用让我们在不放弃所有权的情况下轮询未来值;我们将在下一节中对此进行更详细的解释。
# Pinning
虽然异步函数和异步块对于编写清晰的异步代码至关重要,但处理它们的未来值需要格外小心。Pin类型帮助Rust确保它们被安全使用。
在本节中,我们将说明为什么异步函数调用和异步块的未来值不能像普通Rust值那样随意处理。然后我们将展示Pin如何作为一种“安全使用标志”,用于那些可以安全管理此类未来值的指针。最后,我们将展示一些使用Pin值的方法。
# 未来值的两个生命周期阶段
考虑这个简单的异步函数:
use async_std::io::prelude::*;
use async_std::{io, net};
async fn fetch_string(address: &str) -> io::Result<String> {
❶
let mut socket = net::TcpStream::connect(address).await❷?;
let mut buf = String::new();
socket.read_to_string(&mut buf).await❸?;
Ok(buf)
}
2
3
4
5
6
7
8
9
10
这个函数打开一个到给定地址的TCP连接,并以String类型返回服务器发送的任何内容。标记为❶、❷和❸的点是恢复点,即异步函数代码中执行可能被暂停的位置。
假设你像这样调用它,但不使用await:
let response = fetch_string("localhost:6502");
现在response是一个准备在fetch_string开头开始执行的未来值,并带有给定的参数。在内存中,这个未来值大致如图20 - 5所示。
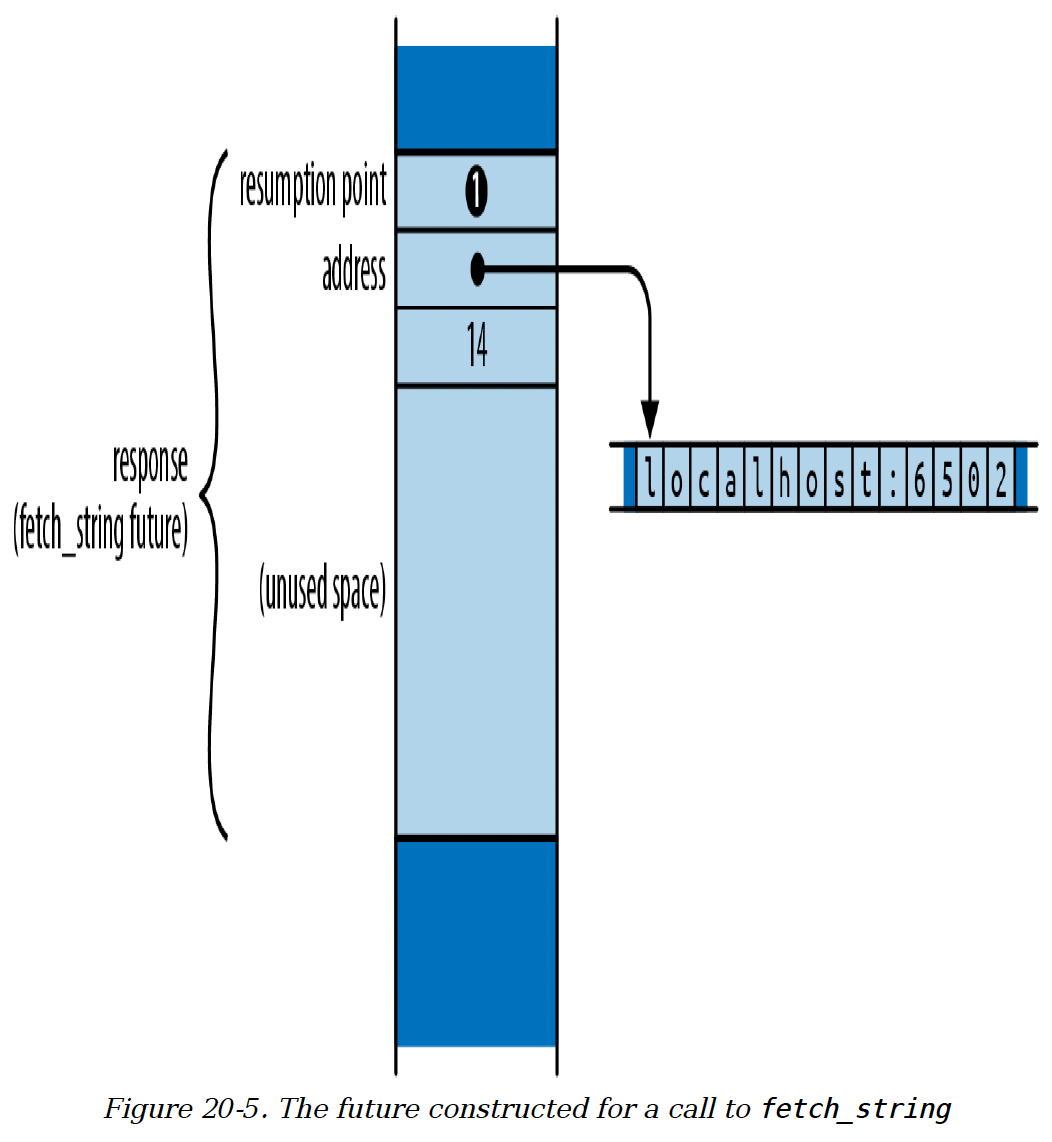 图20 - 5 为调用fetch_string构建的未来值
图20 - 5 为调用fetch_string构建的未来值
由于我们刚刚创建这个未来值,它表示执行应该从恢复点❶开始,即函数体的顶部。在这种状态下,未来值继续执行所需的唯一值是函数参数。
现在假设你对response进行了几次轮询,它到达了函数体中的这个点:
socket.read_to_string(&mut buf).await❸?;
进一步假设read_to_string的结果还未准备好,所以轮询返回Poll::Pending。此时,这个未来值如图20 - 6所示。
一个未来值必须始终保存下次轮询时恢复执行所需的所有信息。在这种情况下,这些信息包括:
恢复点❸,表示执行应该在等待轮询
read_to_string的未来值时恢复。在该恢复点存在的变量:
socket和buf。address的值不再存在于未来值中,因为函数不再需要它。read_to_string子未来值,await表达式正在轮询这个子未来值。
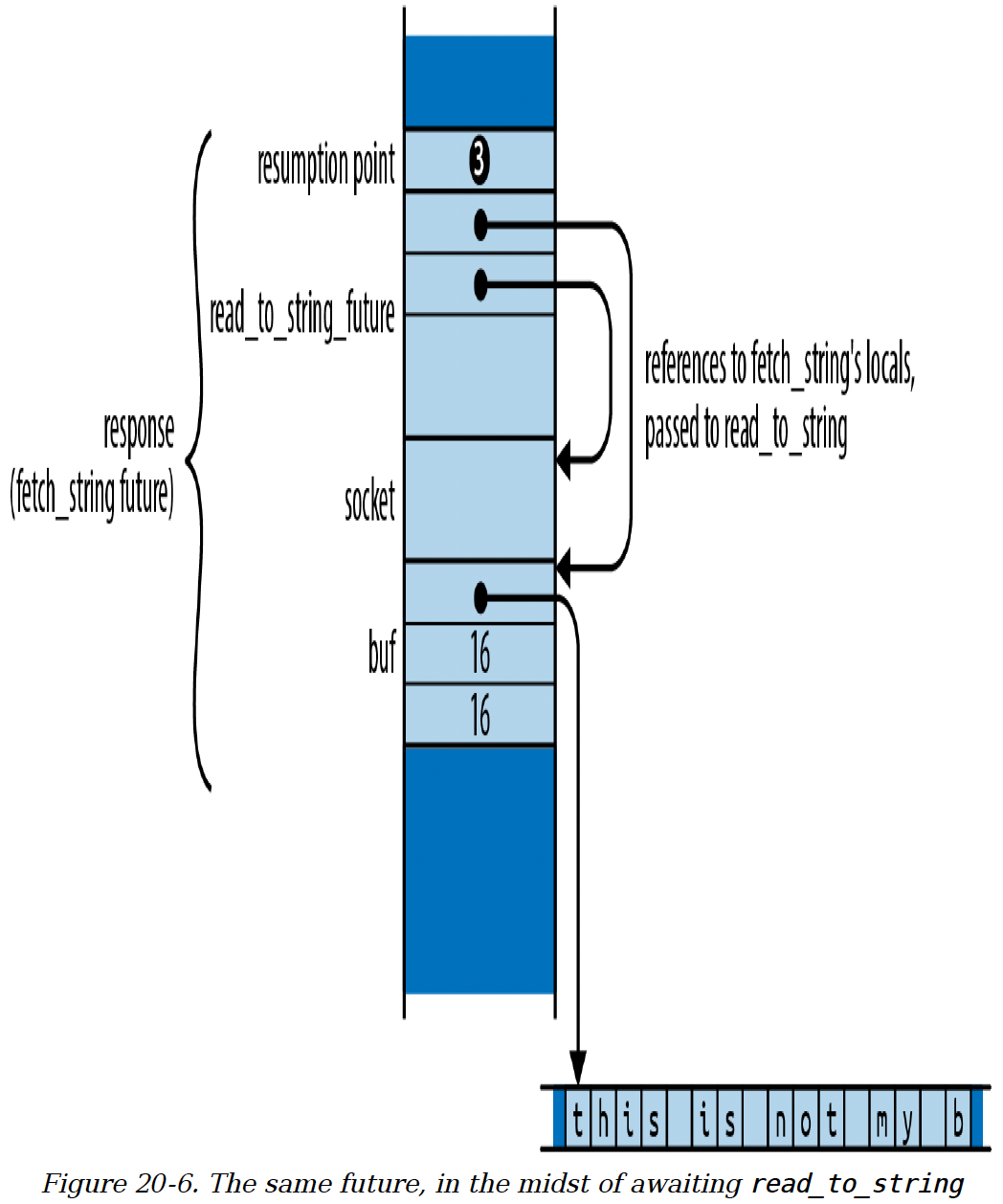 图20 - 6 同一个未来值,在等待read_to_string的过程中
图20 - 6 同一个未来值,在等待read_to_string的过程中
注意,对read_to_string的调用借用了对socket和buf的引用。在同步函数中,所有局部变量都存在于栈上,但在异步函数中,在await过程中仍然存在的局部变量必须存储在未来值中,这样在再次轮询时它们才可用。借用这样一个变量的引用,就相当于借用了未来值的一部分。
然而,Rust要求在值被借用时不能移动它们。假设你将这个未来值移动到一个新的位置:
let new_variable = response;
Rust没有办法找到所有活动的引用并相应地调整它们。这些引用不会指向socket和buf的新位置,而是继续指向现在已未初始化的response中的旧位置。如图20 - 7所示,它们变成了悬空指针。
防止被借用的值被移动通常是借用检查器的职责。借用检查器将变量视为所有权树的根,但与存储在栈上的变量不同,存储在未来值中的变量会随着未来值本身的移动而移动。这意味着对socket和buf的借用不仅影响fetch_string对其自身变量的操作,还影响其调用者对持有这些变量的未来值response的安全操作。异步函数的未来值是借用检查器的一个盲点,如果Rust想要保证内存安全,就必须以某种方式解决这个问题。
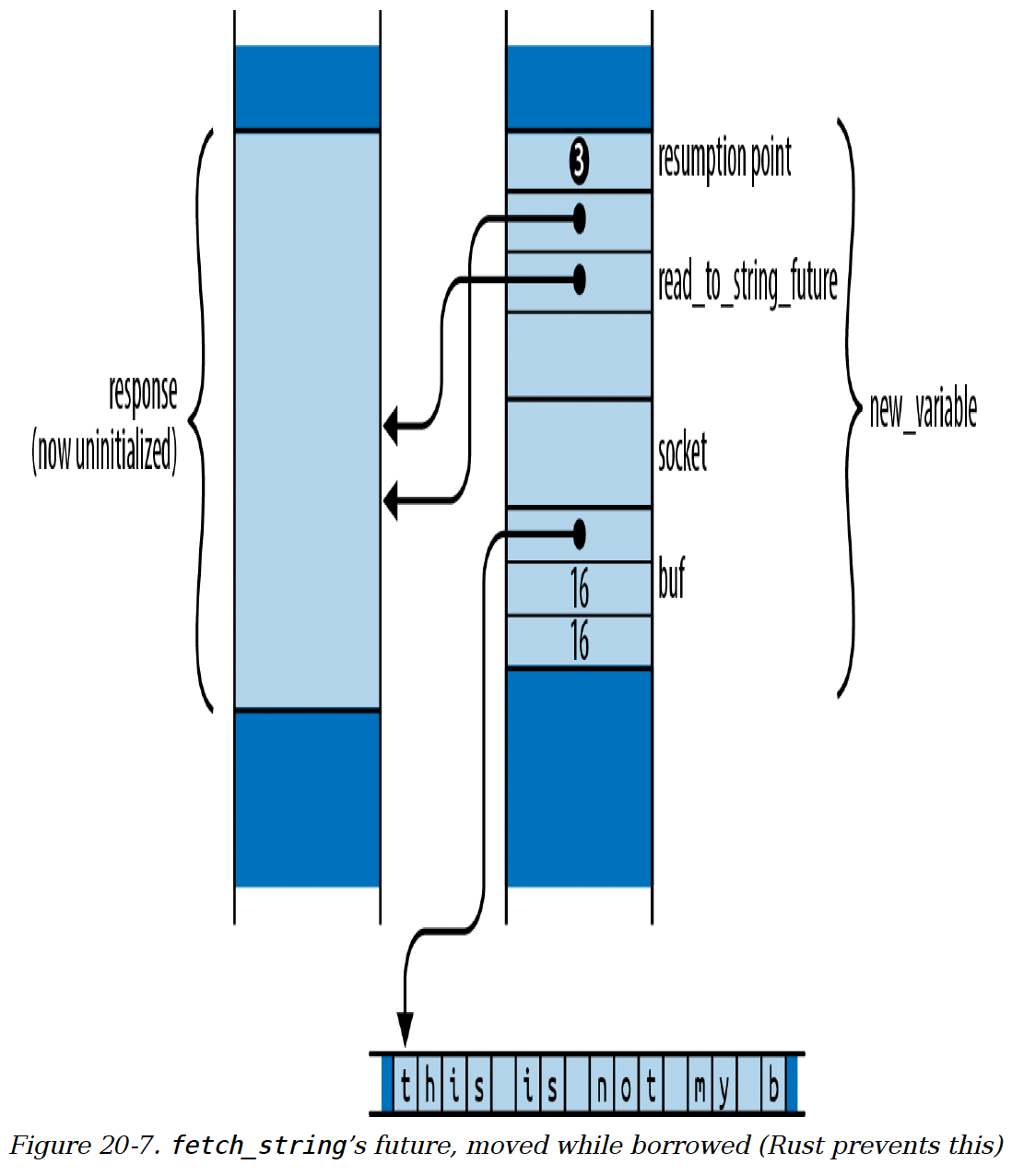 图20 - 7 fetch_string的未来值在被借用时被移动(Rust会阻止这种情况)
图20 - 7 fetch_string的未来值在被借用时被移动(Rust会阻止这种情况)
Rust对这个问题的解决方案基于这样一个见解:未来值在刚创建时总是可以安全移动的,只有在被轮询后才变得不安全。通过调用异步函数刚创建的未来值只保存一个恢复点和参数值。这些仅在异步函数体的作用域内,而函数体尚未开始执行。只有轮询未来值才会借用其内容。
由此我们可以看出,每个未来值都有两个生命周期阶段:
- 第一阶段从未来值创建时开始。由于函数体尚未开始执行,它的任何部分都不可能被借用。此时,它和任何其他Rust值一样可以安全移动。
- 第二阶段从未来值第一次被轮询时开始。一旦函数体开始执行,它可能会借用对存储在未来值中的变量的引用,然后进行
await操作,使未来值的这部分处于被借用状态。从第一次轮询之后开始,我们必须假设未来值可能不能安全移动。
第一生命周期阶段的灵活性使我们能够将未来值传递给block_on和spawn,并调用像race和fuse这样的适配器方法,这些方法都按值接受未来值。实际上,即使最初创建未来值的异步函数调用也必须将其返回给调用者;这也是一次移动。
要进入第二生命周期阶段,未来值必须被轮询。poll方法要求未来值作为Pin<&mut Self>值传递。Pin是指针类型(如&mut Self)的包装器,它限制了指针的使用方式,确保其指向的对象(如Self)再也不能被移动。所以在轮询未来值之前,你必须创建一个指向它的Pin包装指针。
这就是Rust确保未来值安全的策略:未来值在被轮询之前不会变得危险;在构建指向它的Pin包装指针之前,你不能轮询未来值;一旦你这样做了,未来值就不能再被移动。
“一个不能移动的值”听起来似乎不可能:在Rust中移动操作随处可见。我们将在下一节中详细解释Pin如何保护未来值。
虽然本节讨论的是异步函数,但这里的所有内容也适用于异步块。新创建的异步块的未来值就像闭包一样,只是捕获它将从周围代码中使用的变量。只有轮询这个未来值才会创建对其内容的引用,使其变得不安全而不能移动。
请记住,这种移动脆弱性仅限于异步函数和异步块的未来值,以及它们由编译器生成的特殊Future实现。如果你像我们在“调用唤醒器:spawn_blocking”中为SpawnBlocking类型手动实现Future那样,为自己的类型手动实现Future,那么这样的未来值在被轮询之前和之后都可以安全移动。在任何手动实现的poll中,借用检查器会确保在poll返回时,你对self部分的任何借用都已结束。只有异步函数和异步块具有在函数调用过程中暂停执行且借用仍在进行的能力,所以我们必须小心处理它们的未来值。
# 固定指针(Pinned Pointers)
Pin类型是指向未来值的指针的包装器,它限制了指针的使用方式,以确保未来值在被轮询后不能被移动。对于那些不介意被移动的未来值,这些限制可以解除,但对于安全地轮询异步函数和异步块的未来值来说,这些限制至关重要。
这里所说的指针,是指任何实现了Deref,可能还实现了DerefMut的类型。包装在Pin中的指针称为固定指针。Pin<&mut T>和Pin<Box<T>>是比较常见的例子。
标准库中Pin的定义很简单:
pub struct Pin<P> {
pointer: P,
}
2
3
注意,pointer字段不是pub的。这意味着,构造或使用Pin的唯一方式是通过该类型提供的精心选择的方法。
对于异步函数或异步块的未来值,只有几种方法可以获取指向它的固定指针:
futures-lite库中的pin!宏,用一个类型为Pin<&mut T>的新变量遮蔽一个类型为T的变量。新变量指向原始变量的值,该值已被移动到栈上的一个匿名临时位置。当变量超出作用域时,该值会被丢弃。我们在block_on的实现中使用pin!宏来固定我们想要轮询的未来值。- 标准库的
Box::pin构造函数获取任何类型T的值的所有权,将其移动到堆上,并返回一个Pin<Box<T>>。 Pin<Box<T>>实现了From<Box<T>>,所以Pin::from(boxed)获取boxed的所有权,并返回一个指向堆上相同T的固定装箱指针。
获取指向这些未来值的固定指针的每种方法都意味着放弃对未来值的所有权,而且没有办法再将其取回。当然,固定指针本身可以随意移动,但移动指针并不会移动它所指向的对象。所以,拥有一个指向未来值的固定指针就证明你已经永久放弃了移动该未来值的能力。这就是我们确保可以安全轮询未来值所需要知道的全部内容。
一旦固定了一个未来值,如果你想轮询它,所有Pin<pointer to T>类型都有一个as_mut方法,该方法解引用指针并返回poll所需的Pin<&mut T>。
as_mut方法还可以帮助你在不放弃所有权的情况下轮询未来值。我们的block_on实现中就是这样使用它的:
pin!(future);
loop {
match future.as_mut().poll(&mut context) {
Poll::Ready(value) => return value,
Poll::Pending => parker.park(),
}
}
2
3
4
5
6
7
这里,pin!宏将future重新声明为Pin<&mut F>,所以我们本可以直接将其传递给poll。但是可变引用是不可复制的,所以Pin<&mut F>也不可复制,这意味着直接调用future.poll()会获取future的所有权,导致循环的下一次迭代中变量未初始化。为了避免这种情况,我们在每次循环迭代时调用future.as_mut(),重新借用一个新的Pin<&mut F>。
没有办法获取指向固定未来值的&mut引用:如果你能获取,就可以使用std::mem::replace或std::mem::swap将其移出,并用另一个未来值替换它。
在普通异步代码中,我们不必担心固定未来值的问题,是因为获取未来值的最常见方式(等待它或传递给执行器)都会获取未来值的所有权,并在内部管理固定操作。例如,我们的block_on实现获取未来值的所有权,并使用pin!宏生成轮询所需的Pin<&mut F>。await表达式也会获取未来值的所有权,并在内部使用类似于pin!宏的方法。
# Unpin特性
然而,并非所有未来值都需要这种小心的处理。对于为普通类型(比如我们前面提到的SpawnBlocking类型)手动实现的Future,构造和使用固定指针的限制是不必要的。
这种稳定的类型实现了Unpin标记特性:
trait Unpin { }
在Rust中,几乎所有类型都借助编译器的特殊支持自动实现了Unpin。异步函数和异步块的未来值是这个规则的例外。
对于实现了Unpin的类型,Pin不会施加任何限制。你可以使用Pin::new从普通指针创建一个固定指针,还可以使用Pin::into_inner将指针取出。Pin本身会沿用指针自身的Deref和DerefMut实现。
例如,String实现了Unpin,所以我们可以这样写:
let mut string = "Pinned?".to_string();
let mut pinned: Pin<&mut String> = Pin::new(&mut string);
pinned.push_str(" Not");
Pin::into_inner(pinned).push_str(" so much.");
let new_home = string;
assert_eq!(new_home, "Pinned? Not so much.");
2
3
4
5
6
即使创建了Pin<&mut String>,我们仍然可以完全可变地访问字符串,并且在into_inner消耗了Pin,可变引用消失后,还可以将其移动到一个新变量中。所以对于实现了Unpin的类型(几乎是所有类型),Pin只是对指向该类型的指针的一个简单包装。
这意味着,当你为自己的Unpin类型实现Future时,你的poll实现可以将self当作&mut Self来处理,而不是Pin<&mut Self>。固定操作在很大程度上可以被忽略。
你可能会惊讶地发现,即使F没有实现Unpin,Pin<&mut F>和Pin<Box<F>>也实现了Unpin。这听起来有点奇怪 —— 一个Pin怎么会是Unpin的呢?但如果你仔细思考每个术语的含义,就会发现这是有道理的。即使F在被轮询后不能安全移动,但指向它的指针无论是否被轮询,总是可以安全移动的。移动的只是指针,而它所指向的易变对象保持不动。
当你想将异步函数或异步块的未来值传递给一个只接受Unpin未来值的函数时,了解这一点很有用。(在async_std中,这样的函数很少见,但在异步生态系统的其他地方并非如此。)即使F没有实现Unpin,Pin<Box<F>>也是Unpin的,所以对异步函数或异步块的未来值应用Box::pin,你就可以得到一个可以在任何地方使用的未来值,代价是一次堆内存分配。
有各种用于处理Pin的不安全方法,这些方法允许你对指针及其目标对象做任何你想做的操作,即使目标类型没有实现Unpin。但正如第22章所解释的,Rust无法检查这些方法的使用是否正确;使用它们的代码的安全性由你自己负责。
# 异步代码在何时有用?
编写异步代码比编写多线程代码更复杂。你必须使用正确的I/O和同步原语,手动拆分长时间运行的计算,或者将它们放到其他线程上执行,还要处理像固定操作这样在线程代码中不会出现的其他细节。那么异步代码具体有哪些优势呢?
有两个常见的说法经不起仔细推敲:
- “异步代码非常适合I/O操作。” 这种说法并不完全正确。如果你的应用程序在等待I/O操作上花费时间,将其异步化并不会使I/O操作运行得更快。如今常用的异步I/O接口在效率上并不比同步接口更高。无论哪种方式,操作系统要做的工作都是一样的。(实际上,一个尚未准备好的异步I/O操作稍后必须再次尝试,所以它需要两次系统调用才能完成,而不是一次。)
- “异步代码比多线程代码更容易编写。” 在像JavaScript和Python这样的语言中,这可能确实是真的。在这些语言中,程序员将
async/await作为一种行为良好的并发形式使用:只有一个执行线程,并且只有在await表达式处才会发生中断,所以通常不需要互斥锁来保证数据一致性:只要在使用数据时不进行await操作就行!当任务切换只有在你明确允许的情况下才会发生时,理解代码要容易得多。
但这个观点并不适用于Rust,在Rust中线程并没有那么麻烦。一旦你的程序编译通过,就不会存在数据竞争问题。不确定性行为仅限于像互斥锁、通道、原子操作等同步特性,而这些特性就是为处理这类问题而设计的。所以异步代码在帮助你了解其他线程可能何时影响你的代码方面并没有独特的优势;在所有安全的Rust代码中这一点都很清楚。当然,Rust的异步支持与线程结合使用时确实非常出色。如果放弃这种结合,那就太可惜了。
那么,异步代码真正的优势是什么呢?
- 异步任务可以使用更少的内存。在Linux上,一个线程的内存使用量(包括用户空间和内核空间)起始为20 KiB。而未来值可以小得多:我们聊天服务器的未来值大小只有几百字节,并且随着Rust编译器的不断改进,还在变得更小。
- 异步任务的创建速度更快。在Linux上,创建一个线程大约需要15微秒。生成一个异步任务大约需要300纳秒,大约是创建线程时间的五十分之一。
- 在Linux上,异步任务之间的上下文切换比操作系统线程之间的上下文切换更快,分别是0.2微秒和1.7微秒。不过,这些都是每种情况的最佳数据:如果切换是由于I/O准备就绪引起的,两种情况下的开销都会增加到1.7微秒。切换发生在不同处理器核心上的线程还是任务之间,也会有很大差异:核心之间的通信非常慢。
这让我们了解到异步代码可以解决哪些类型的问题。例如,一个异步服务器每个任务可能使用更少的内存,因此能够处理更多的并发连接。(这可能就是异步代码 “适合I/O操作” 这种说法的由来。)或者,如果你的设计自然地由许多相互通信的独立任务组成,那么每个任务的低开销、短创建时间和快速上下文切换都是重要的优势。这就是为什么聊天服务器是异步编程的经典示例,而多人游戏和网络路由器可能也是异步代码的良好应用场景。
在其他情况下,使用异步代码的优势就不那么明显了。如果你的程序有一个线程池在进行繁重的计算,或者闲置等待I/O完成,那么前面列出的优势可能对其性能影响不大。你必须优化计算过程、寻找更快的网络连接,或者采取其他实际影响限制因素的措施。
在实践中,我们找到的每一篇关于实现高并发服务器的文章都强调了测量、调优以及持续识别和消除任务之间竞争源的重要性。异步架构并不能让你跳过这些工作。事实上,虽然有很多现成的工具可以评估多线程程序的行为,但Rust异步任务对这些工具是不可见的,因此需要专门针对异步任务的工具。(正如一位智者所说:“现在你又多了一个问题。”)
即使你现在不使用异步代码,知道如果将来业务量大幅增加时还有这个选择也是不错的。
批注:
- 如果你确实需要一个HTTP客户端,可以考虑使用许多优秀的库,如
surf或reqwest,它们能正确且异步地完成工作。这个客户端主要是用于处理HTTPS重定向。- 这包括内核内存,并且计算的是为线程分配的物理页面,而不是虚拟的、尚未分配的页面。在macOS和Windows上,这个数字也类似。
- 在Linux上,由于处理器安全漏洞,内核不得不使用较慢的技术之前,上下文切换时间也在0.2微秒左右。